概要
手元に GPU リソースがなかったため、Google Colab の GPU を利用して YOLOv8 のファインチューニングを行いました。
デフォルトの YOLOv8 モデルには「ペン」を検出するクラスが含まれていないため、アノテーションしたデータセットを使ってペンを認識できるよう再学習しています。
本記事では、その学習手順とモデル運用の流れについて説明します。
実行環境について(ローカル / クラウド)
本記事では、以下のように役割を分けて作業しています。
-
Google Colab(クラウド)
- YOLO の学習を実行
-
ローカルPC
- 画像へのアノテーション作業
- 学習後のモデルを使った画像の読み取り(推論)
-
クラウドストレージ(例:Google Drive など)
- アノテーション済み画像や学習用データセットの保存
学習環境の構築
Colab上にファインチューニングを行うための環境を構築していきます。
Colabにアクセス
・GoogleColabにアクセスする
・New Notebookを選択する
Yoloをインストールする
この時点で既に、pythonが実行できる状態にあるので、
Yoloをインストールするための実行をします。
pip install ultralytics
Yoloのインストールの確認
Yolov8がインストールされると、同時に学習モデルもダウンロードされています。
試しにモデルを開いて、クラスが表示されるか確認してみました。
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
print(model.names)
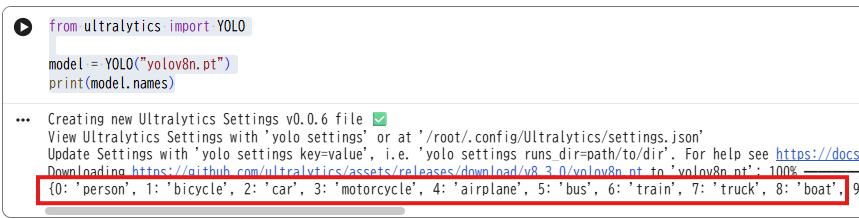
モデル内の学習されているクラスが表示されました
これで、Yolov8が正しくインストールされていることがわかりました。
アノテーションの準備
特定の物体を検出できるようにするためには、特定の物体の学習を行う必要があります。
「アノテーション」とは「注釈」という意味で、データ(テキスト、画像、音声など)にタグやメタデータと呼ばれる追加情報をつけていく作業を指します。
labelimgをインストール
アノテーションは、自分のPC内で行います。
今回はlabelimgというアノテーションツールを使いました。
CMDを開いてlabelimgをインストールします。
pip install labelImg
labelimgを実行
実行するとアノテーションツールを開くことができます。
labelimg

labelimgのエラー修正
labelimgを開くことができました!
しかし、labelimgのソース内でエラーとなる箇所がいくつか存在しているらしいです。そのためアノテーションを行う前に、ソースコードの修正を行います。修正は以下のサイトを参考にさせてもらいました。
画像を拡大するときもエラーが発生するため修正
971行あたり
self.zoom_widget.setValue(int(round(value)))
1025行あたり
h_bar.setValue(int(round(new_h_bar_value)))
1026行あたり
v_bar.setValue(int(round(new_v_bar_value)))
画像の準備
今回は冒頭で説明した通り、Yolov8モデルの学習クラスに存在していない"ペン"が認識できるようにファインチューニングを行います。
ファインチューニングをするにあたり、データーを集める作業が一番大変かもしれません。
今回は、学習用のデータを500枚、検証用のデーターを50枚の計550枚の画像を集めました。

ディレクトリ構造
dataset/
├─ train/
│ ├─ images #学習用
│ └─ labels
└─ vaild/
├─ images # 検証用
└─labels
アノテーション時に必ず「学習用」と「検証用」を区別し、
それぞれのデータが混在しないよう、対応したlabelsフォルダーへ分けてラベルを保存してください。
アノテーションを行う
アノテーションツールや、画像の準備ができたらいよいよアノテーションを行います。
labelimgでディレクトリ選択する
ペンの画像が入っているディレクトリを選択する
ラベルを保存するディレクトリを選択する
YOLO・Create Reactboxを選択する
(YOLOが表示されていれば、選択できている)
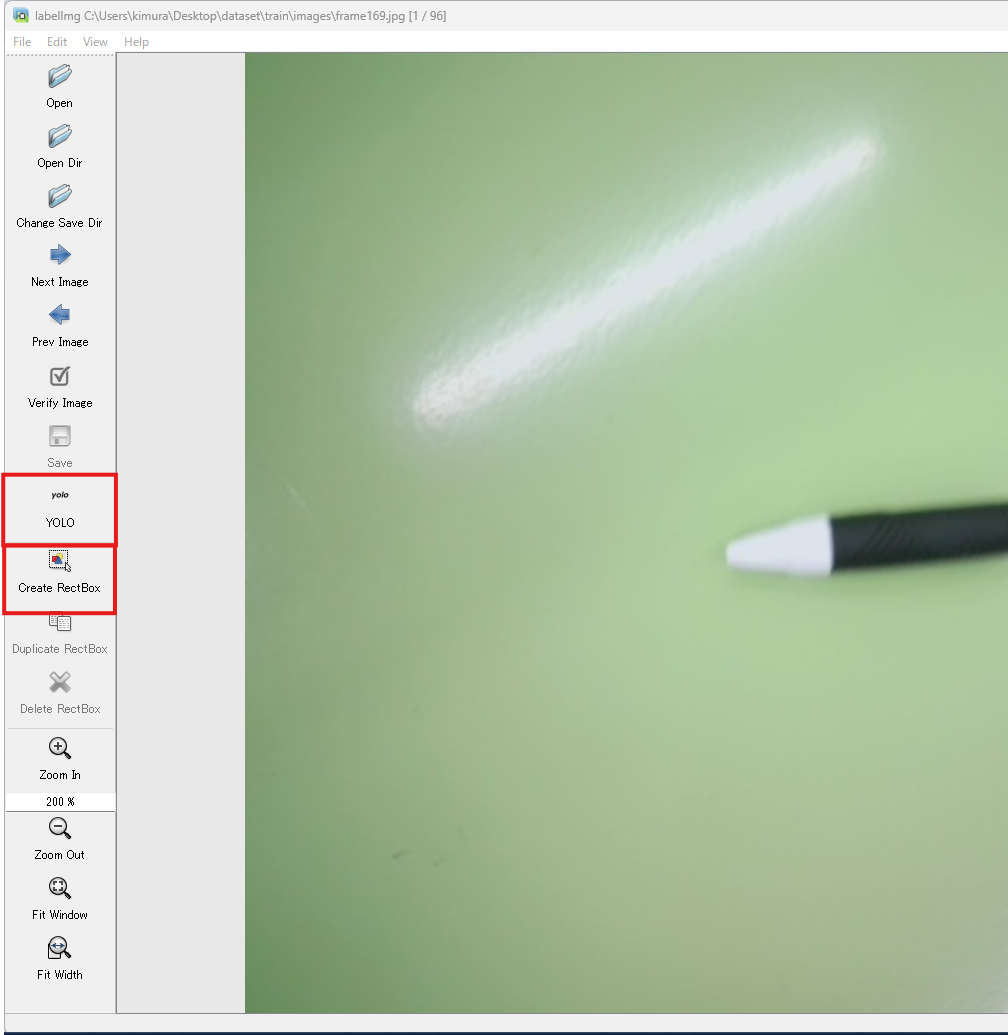
アノテーション
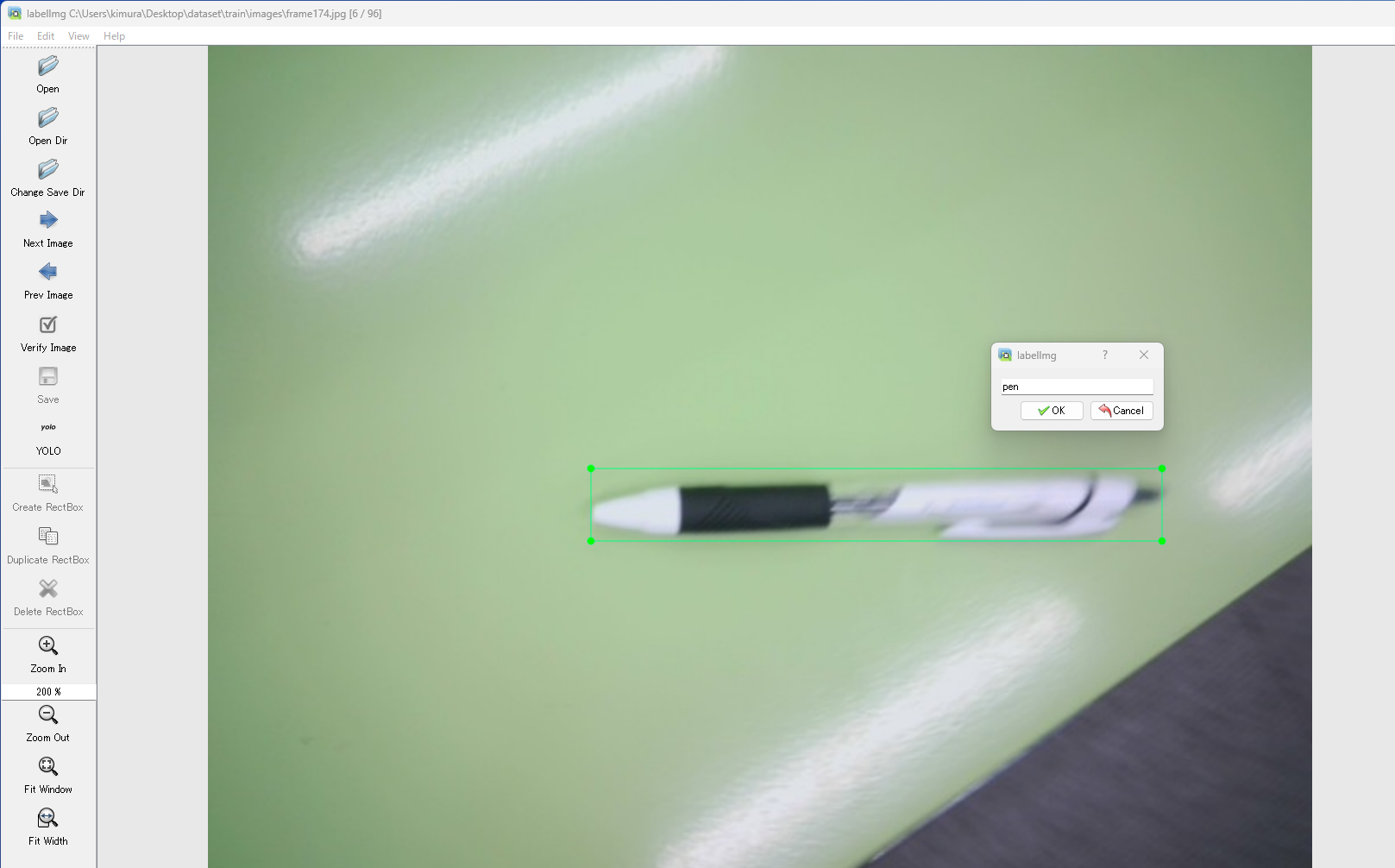
対象を矩形で囲っていきます。
文字が小さいですが、クラス名を"pen"としました。
これを、train・vaildに保存されている画像すべてに行います。
矩形を囲んだら、ラベルを保存するために指定したディレクトリにテキストファイルが
アノテーションが完了後のデータを準備
train/vaildフォルダーに入っている画像すべてにアノテーションが完了したらいよいよColabで学習を行っていきます。しかし、その前にいくつかの準備が必要です。
学習データの配置
学習に使用するデータは、Google Drive に保存しておきます。
Google Colab から Google Drive をマウントし、そこに保存した学習データを読み込んでモデルの学習を行います。マイドライブ直下に、アノテーションを行った学習データを設置しました。(学習データーの設置場所は任意)
yamlファイルを準備
YOLOv8 は、COCO というデータセットで事前学習されたモデルを使っています。
COCO データセットには、0 番から順に「person(人)」「car(車)」「dog(犬)」といったクラスがあらかじめ定義されています。
本来、クラス ID 0 には「person(人)」クラスが登録されていますが、
今回はこの 0 番クラスを「pen(ペン)」クラスとして再学習(ファインチューニング) しました。イメージとしては、「person クラスを上書きして pen クラスとして使う」 形です。
YOLOv8 では、どのクラスを何として扱うか や データセットの場所 などを
yaml ファイルに設定し、この yaml ファイルを起点として学習を行います。
そのため、COCO のクラス定義をベースにしつつ、0 番クラスを「pen」に書き換えた yaml を用意して学習させています。
それぞれの定義が完了したら、yamlファイルもGoogleDrive上に設置します。
設置場所も任意です。
train: /content/drive/My Drive/dataset/train # /content/drive/My Drive/までは共通
val: /content/drive/My Drive/dataset/valid # /content/drive/My Drive/までは共通
# クラス総数
nc: 80
# class names
names:
0: pen #penに変更
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
学習を行う
学習の前準備が完了したらいよいよ、学習を実行する段階です。
実行コード
たったこれだけのコード数で学習が行えたのは驚きました。
今回は、Yoloのモデルの種類の解説や、epoch(学習回数)の数値はどれくらいにするべきかのような解説は割愛します。
from google.colab import drive
from ultralytics import YOLO
#GoogleDriveに接続(マウント)
drive.mount('/content/drive')
model = YOLO("yolov8n.pt")
#googledriveに設定したyamlファイルを指定してください
model.train(data="/content/drive/My Drive/yolo-yaml/my-data-set.yaml", epochs=50, batch=8, workers=4, degrees=90.0,imgsz=640)
ColabでGPUをオンにする
一応CPUでも学習が行えますが、あまりに時間がかかります。Colabでは無料で制限付きですがGPUを使える事が出来ます。デフォルトではGPUは使えないので、設定からGPUを使えるように設定します。
無料枠として2つのハードウェアを使う事が出来ますが、T4 GPUを選択してください。
TPU(google製)を使って学習を行おうとしましたが、Yoloの学習においては学習の根幹にPyTorchベースでNvidiaCUDAを使った計算を行っているため、デフォルトではGPUを使わないとエラーになります。TPUを使う場合は別途工夫が必要になるらしいです。

学習開始
GPUをオンにすることができら、学習の準備が完了しているので実行できる状態にあります。
学習がスタートすると設定したepochの回数だけ学習が行われます。
ログを確認することで学習の進捗がわかります。
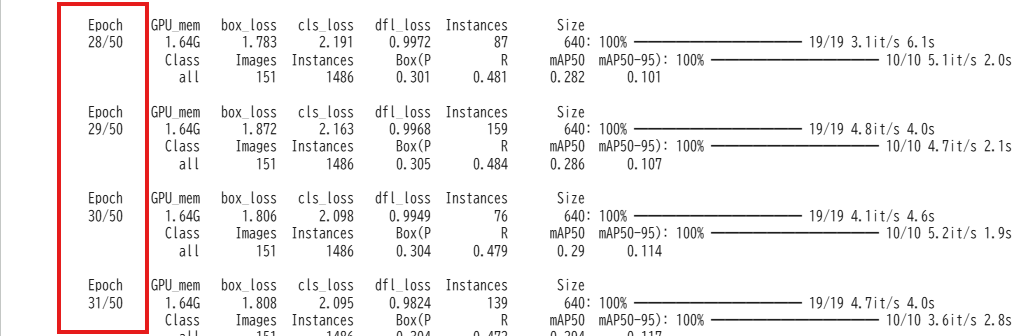
学習が完了
ログを見て学習が完了したことを確認したら、いよいよモデルをダウンロードします。
ファインチューニングを行ったモデルを取り出す
メニューバーから、フォルダーマークを選択して、画像のようなルートでディレクトリを開いてください。best.pt・last.ptが今回のファインチューニングで出力されたモデルです。
性能がベストだった時の、best.ptの方をダウンロードします。
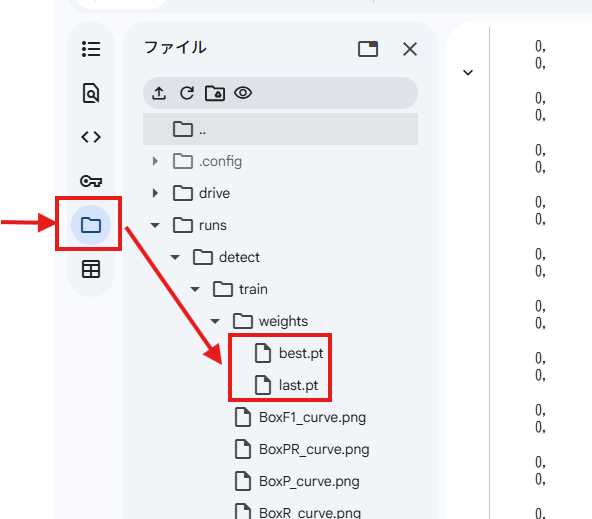
モデルの違い
best.pt:その学習の中で「性能がベストだった状態のスナップショット」
last.pt:学習を続けた結果の「最終形(良くなってるか悪くなってるかは別)」
学習を行ったモデルを使ってみる
学習を行ったモデルを使って画像を読み取ってみましょう。
ローカルモデルを使います。
実行コード
import cv2
from os.path import join
from ultralytics import YOLO
# モデル
modelpath = "/your/model/path"
model = YOLO(modelpath)
# 入力画像
input_image = "/your/input/image.jpg"
# 保存先フォルダ
savepath = "/your/save/path"
filename = "result.jpg"
savefile = join(savepath, filename)
# 画像読み込み
img = cv2.imread(input_image)
# YOLO 推論
results = model(img)
# 結果を描画(bbox 付き)
annotated = results[0].plot()
# 結果を保存
cv2.imwrite(savefile, annotated)
print("保存しました:", savefile)
読み取り結果
こんなに簡単な手順で、ペンを検出できるようになりました!

補足・注意点
GoogleColabのセッションについて
Google Colab にはセッションの時間制限があり、無料版では
「無操作90分」「最大12時間」で自動的にセッションが切断されます。(2025年12月現在)
学習が長時間に及ぶ場合、途中で強制終了される可能性があります。
再実行を避けるため、学習データやモデルファイルは必ず Google Drive 側に保存してください。特に大きなモデルや長時間学習では時間切れに注意が必要です。
モデルの保存場所指定
model.train()の引数に、保存場所を指定してください。
from google.colab import drive
from ultralytics import YOLO
drive.mount('/content/drive')#GoogleDriveをマウントは必須
model.train(
data="/content/drive/My Drive/yolo-yaml/my-data-set.yaml",
epochs=50,
batch=8,
workers=4,
degrees=90.0,
imgsz=640,
# ▼ 保存先(事前に Drive をマウントしておけば使える)▼
project="/content/drive/My Drive/yolo-output", # Drive 内のフォルダ
name="pen-model-v1" # 出力サブフォルダ
)
/content/drive/My Drive/yolo-output/pen-model-v1/
├── weights/
│ ├── best.pt
│ └── last.pt
├── results.csv
└── その他ログファイル
GoogleDriveとライブラリ
せっかくインストールしたライブラリもセッションが終了されると同時に、消えてしまいます。YOLOv8のような必ず使うライブラリはセッション開始時に都度ダウンロードするのでなくGoogleDrive上に保存して、importできる状態にしておいたほうがいいと思います。
GoogleDriveにライブラリを保存
from google.colab import drive
drive.mount('/content/drive')#GoogleDriveをマウントは必須
pip install --target="/content/drive/My Drive/colab-libs" ultralytics
#pip install --target="Googledrive/path" ライブラリ名
GoogleDriveからライブラリをインポート
import sys
from google.colab import drive
drive.mount('/content/drive')#GoogleDriveをマウントは必須
sys.path.append('/content/drive/My Drive/colab-libs/my-site-package')
from ultralytics import YOLO #インポートすることができる
まとめ
今回の手順では、Google Colab を活用することで、GPU がない環境でも YOLOv8 のファインチューニングを手軽に実行できることを確認できました。
学習精度を左右するのはアノテーションの質であり、train/valid を分けて丁寧に作業することが最も重要です。
また、yaml ファイルが学習全体の「設計図」となるため、クラス定義やデータパスを正しく設定することで、COCO のクラスを簡単に上書きしてカスタムモデルを作成できます。
学習後は best.pt をローカルにダウンロードするだけで、すぐに推論用モデルとして利用可能です。
またセッションという考え方を、積極的に使っていた時に気が付かなかったので、なぜ学習したモデルがなくなってしまうのかというところでつまずきました😢