この記事は Aizu Advent Calendar の9日目の記事です。
Neural Network Consoleで株価を予想するアルゴリズムを作成する
- 割りと最近は、時系列系のDeep Learingを使った予測例が充実してきてるように思います。今回は、(使うユーザーが増えてほしいと願いを込めて)Neural Network Console(NNC)を使って時系列の予測したいと思います。様々なフレームワークの中でNNCは、GUIかつ直感的にモデルの作成ができます。また、最適化モデルの作成自動もできる優れものです。(使い方は、ドキュメントをご参照下さい。)
考え方
- 株価の1週間分のデータ(5個)いれたら次点の値(終値)を予測する。
- 2016年のデータで学習データ、2017年のデータを評価データとする。
- 1~7の手順で作成していきます。
1. Neural Network Console(NNC)のダウンロード
- 今回は、ダウンロード版を使います
- ここから会員登録してダウンロードしましょう
- サポートページ
- ダウンロードして解凍したneural_network_console_110は以下の構成になっていると思います。
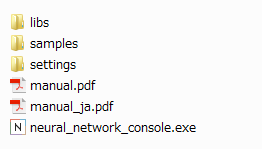
2. 株式データのダウンロード
- こちらからダウンロードしました
-
株式投資メモ
- 皆さんよく使っているものです。今回以下のデータを使いました。
- 6502_2016.csv(2016年のデータ)
- 6502_2017.csv(2017年のデータ)
- 皆さんよく使っているものです。今回以下のデータを使いました。
-
株式投資メモ
3. 前処理
データ・セットの作成
- エクセルで作成することも出来ますが、大変なのでpythonファイルで簡単に作成できるようにしました。詳しい解説は、省略させて下さい。
- stock_dataとフォルダを作成して、株価のデータをその中に入れて下さい。
- そのフォルダでこちらのpythonコードを入れて、実行して下さい。
generate_data.py
# -*- coding: utf_8 -*-
import os
import argparse
import shutil
import csv
import numpy as np
import pandas as pd
def generate_train_data(training_file, divide_value):
dir_name = './training_data/'
if os.path.exists(dir_name):
shutil.rmtree(dir_name)
os.mkdir(dir_name)
input_file = training_file
df_stock = pd.read_csv(input_file, encoding="shift-jis", header=1)
df_stock_2 = df_stock[['始値', '高値', '安値', '終値', '出来高', '終値調整値']].apply(np.log) / 100
divide_value = divide_value
loop_range = int(df_stock_2.shape[0] / divide_value)
validate = int(loop_range * 0.1)
files_name = []
labels = []
for i in range(loop_range):
start = i * divide_value
end = (i + 1) * divide_value
write_file_name = dir_name + 'data_' + str(i) + '.csv'
if ((end+1) < df_stock['終値'].shape[0]):
df_stock_2[start:end].to_csv(write_file_name, header=None, index=None)
files_name.append(write_file_name)
labels.append(int(df_stock['終値'].iloc[(end+1)]) / 1000)
# print (labels)
# print (files_name)
f_train = open('stock_train.csv', 'w')
writer_train = csv.writer(f_train, lineterminator='\n')
f_validation = open('stock_validation.csv', 'w')
writer_validation = csv.writer(f_validation, lineterminator='\n')
header = ['x:data', 'y:label']
writer_train.writerow(header)
writer_validation.writerow(header)
for i, (file, label) in enumerate(zip(files_name, labels)):
# print (i, file, label)
if (i < (len(files_name) - validate)):
writer_train.writerow((file, label))
if (i >= (len(files_name) - validate)):
writer_validation.writerow((file, label))
f_train.close()
f_validation.close()
print("Complete !")
def gererate_evaluation_data(evaluation_file, divide_value):
dir_name = './evaluation_data/'
if os.path.exists(dir_name):
shutil.rmtree(dir_name)
os.mkdir(dir_name)
input_file = evaluation_file
df_stock = pd.read_csv(input_file, encoding="shift-jis", header=1)
df_stock_2 = df_stock[['始値', '高値', '安値', '終値', '出来高', '終値調整値']].apply(np.log) / 100
divide_value = divide_value
loop_range = int(df_stock_2.shape[0])
files_name = []
labels = []
for i in range(loop_range):
start = i * divide_value
end = (i + 1) * divide_value
write_file_name = dir_name + 'data_' + str(i) + '.csv'
if ((end+1) < df_stock['終値'].shape[0]):
df_stock_2[start:end].to_csv(write_file_name, header=None, index=None)
files_name.append(write_file_name)
labels.append(int(df_stock['終値'].iloc[(end+1)]) / 1000)
# print (labels)
# print (files_name)
f_evaluation = open('stock_evaluation.csv', 'w')
writer_evaluation = csv.writer(f_evaluation, lineterminator='\n')
header = ['x:data', 'y:label']
writer_evaluation.writerow(header)
for i, (file, label) in enumerate(zip(files_name, labels)):
writer_evaluation.writerow((file, label))
f_evaluation.close()
print("Complete !")
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--training_file', '-t', type=str)
parser.add_argument('--evaluation_file', '-e', type=str)
parser.add_argument('--divide_value', '-d', type=int)
args = parser.parse_args()
if args.training_file is None:
training_file = '6502_2016.csv'
if args.evaluation_file is None:
evaluation_file = '6502_2017.csv'
if args.divide_value is None:
divide_value = 5
generate_train_data(training_file, divide_value)
gererate_evaluation_data(evaluation_file, divide_value)
if __name__ == '__main__':
main()
-
以下のようなフォルダ構造になります。
- stock_data
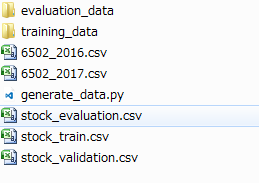
- stock_data
-
このstock_dataをneural_network_console_110フォルダの中に入れて以下のような構成にして下さい。
- neural_network_console_110
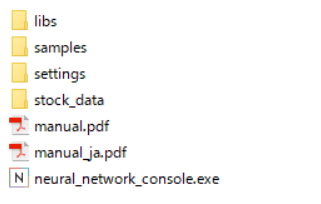
- neural_network_console_110
4. モデルの作成
- 保存ディレクトリは、stock_dataにして、以下のようなネットワークを作って下さい。
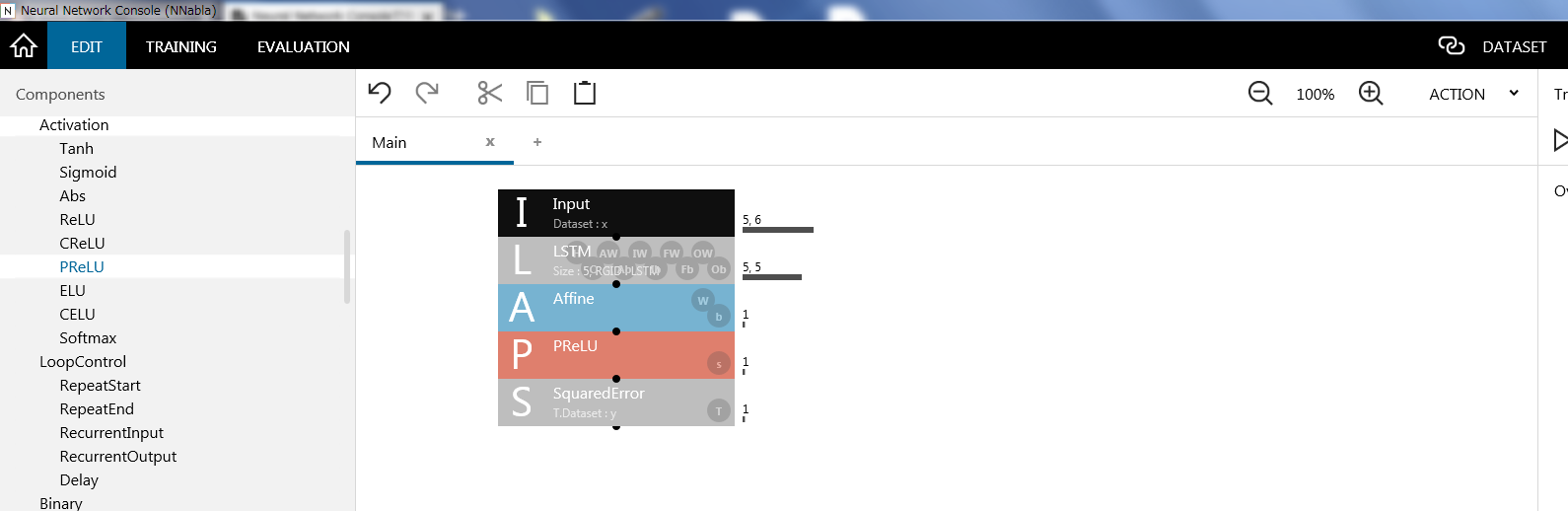
5. 学習用データセットの設定
-
5-1. DATASETタブをクリックして以下の画面になったところで赤丸をクリックします。
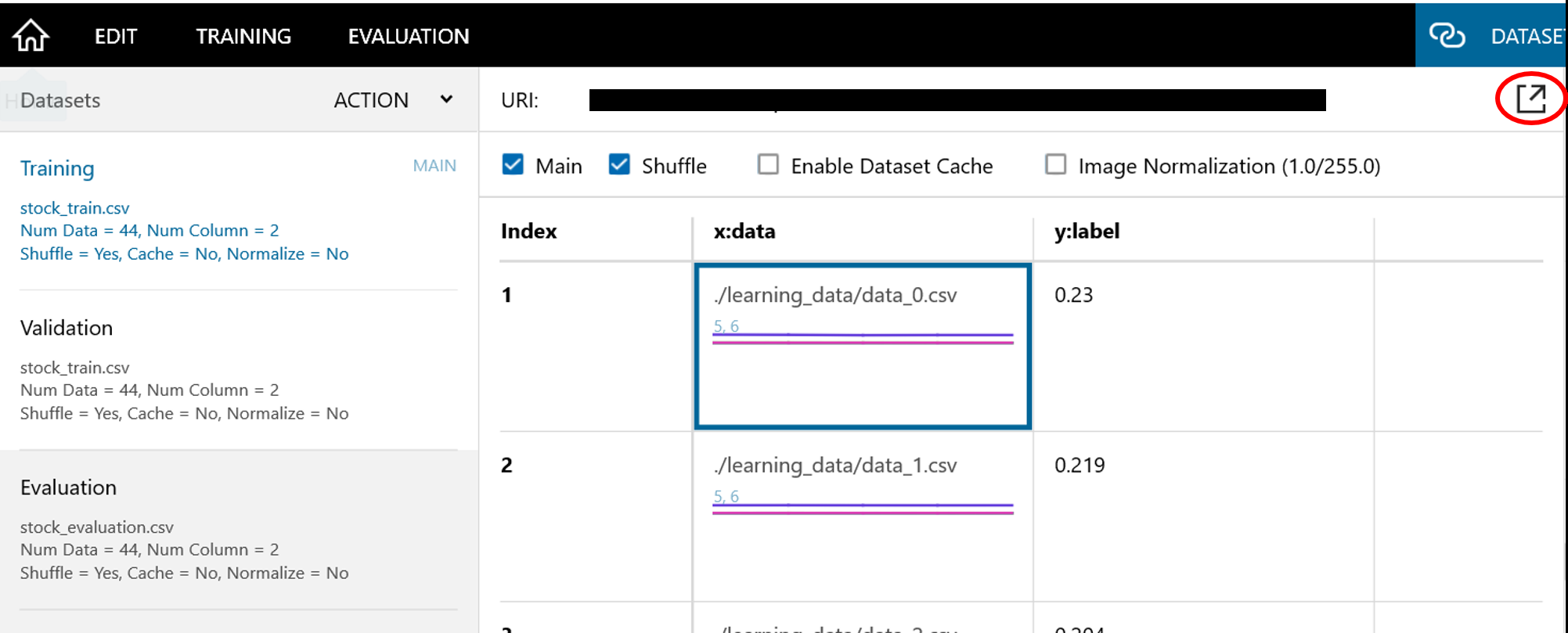
-
5-2. 以下の画面でOpen Datasetをクリックして、それぞれのCSVファイルを以下の画面から追加します。
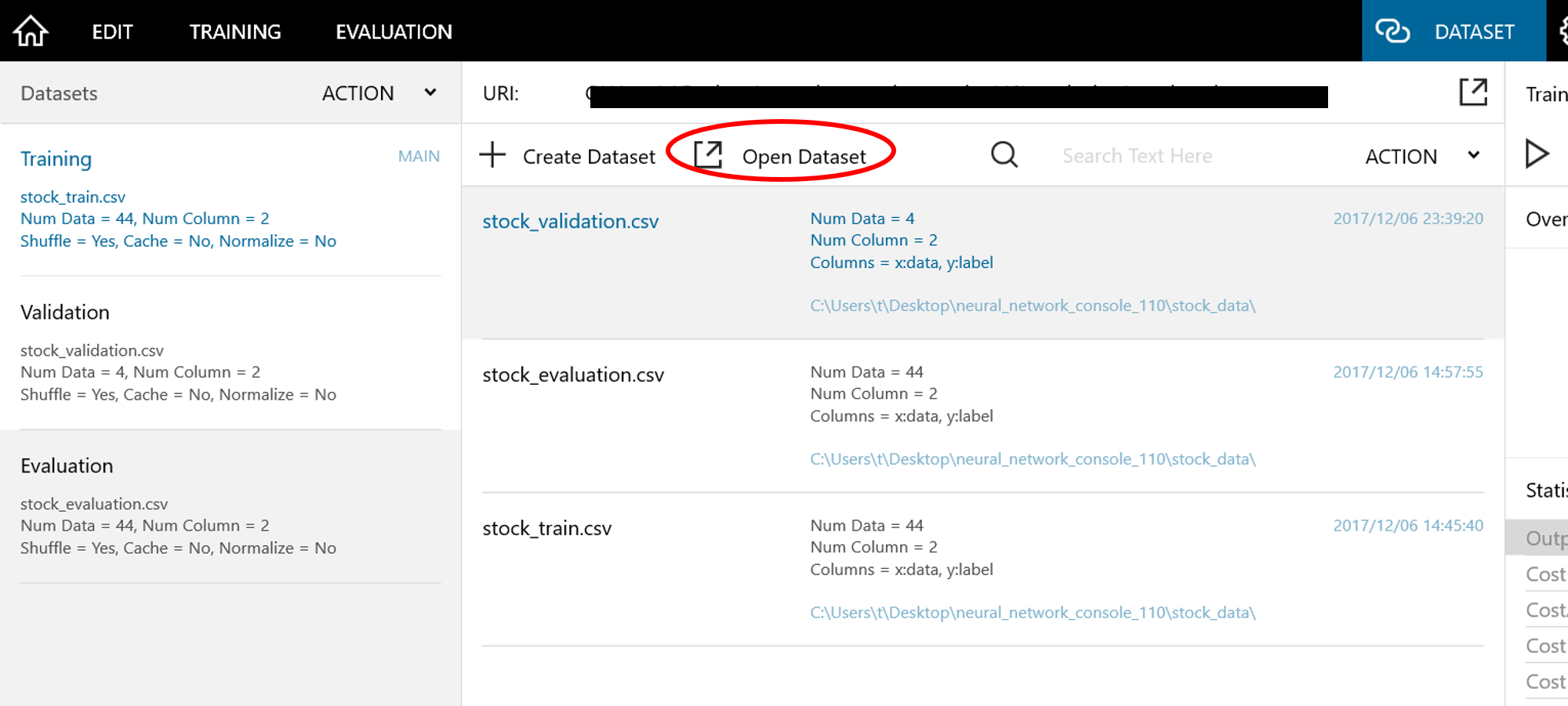
-
5-3. Training、Validation、Evaluationに5-1、5-2を繰り返して該当するデータセットをセットして下さい。
- Trainingデータ
- stock_training.csv
- Validationデータのセット
- stock_validation.csv
- Evaluationデータのセット
- stock_evaluation.csv
- Evaluationは、5-1でActionをクリックしてAddで追加して下さい。
- Trainingデータ
-
5-4. Configタブをクリックして以下のような設定にします。
-
Global Config ※Batch Sizeは、1~4、Max Epochは、1000~10000で設定して下さい。
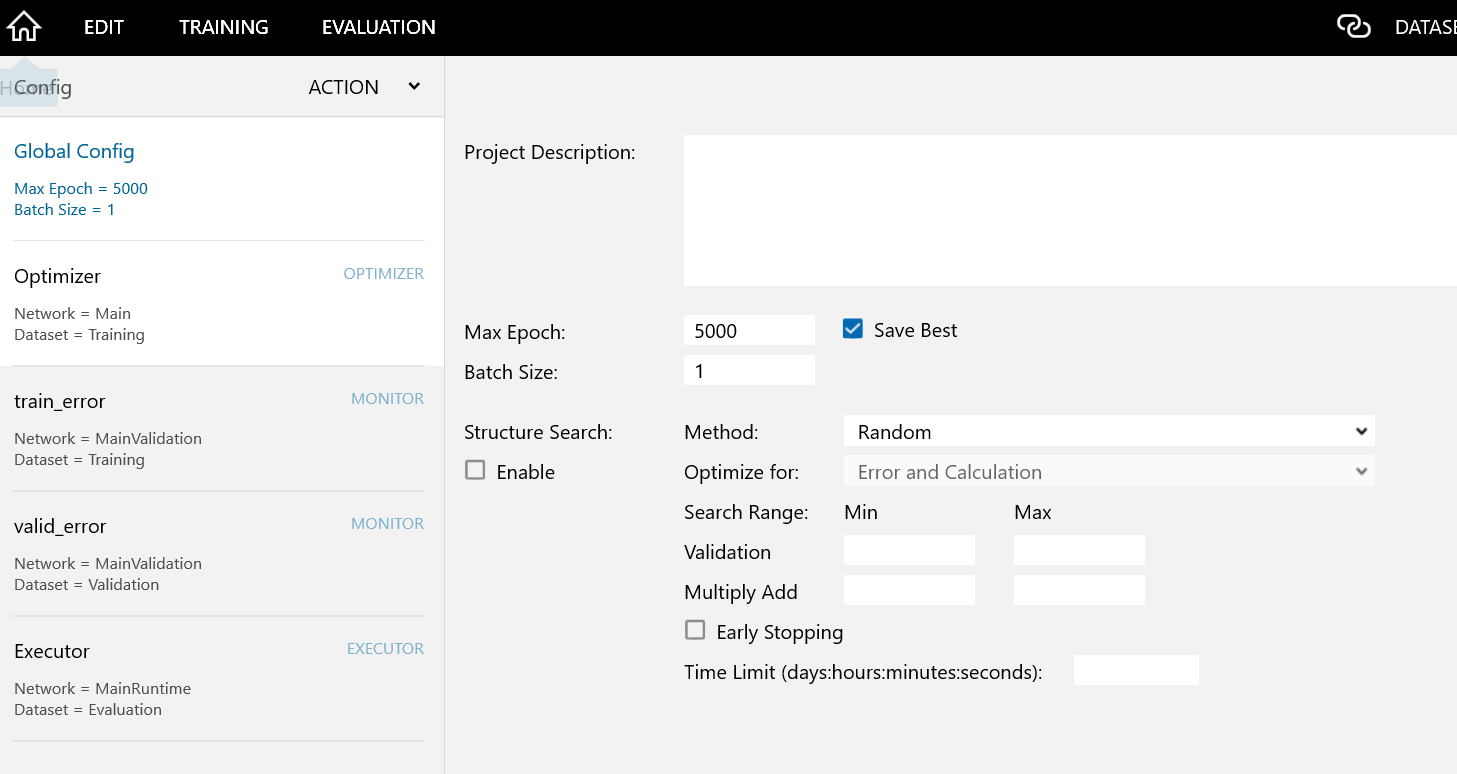
-
Excutor
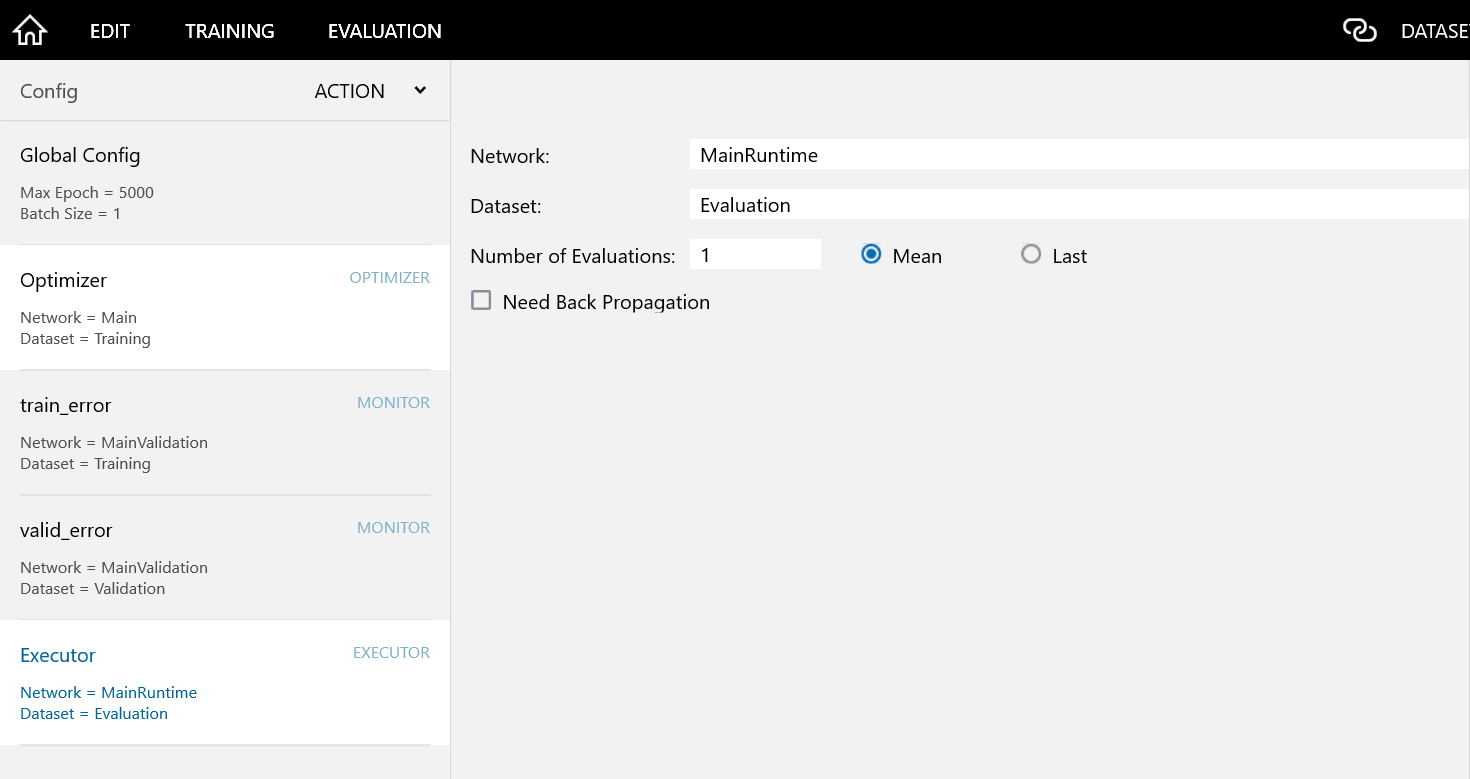
-
7. モデルの評価
-
Trainingの▶を押して、学習が終わると以下のような画面になります。
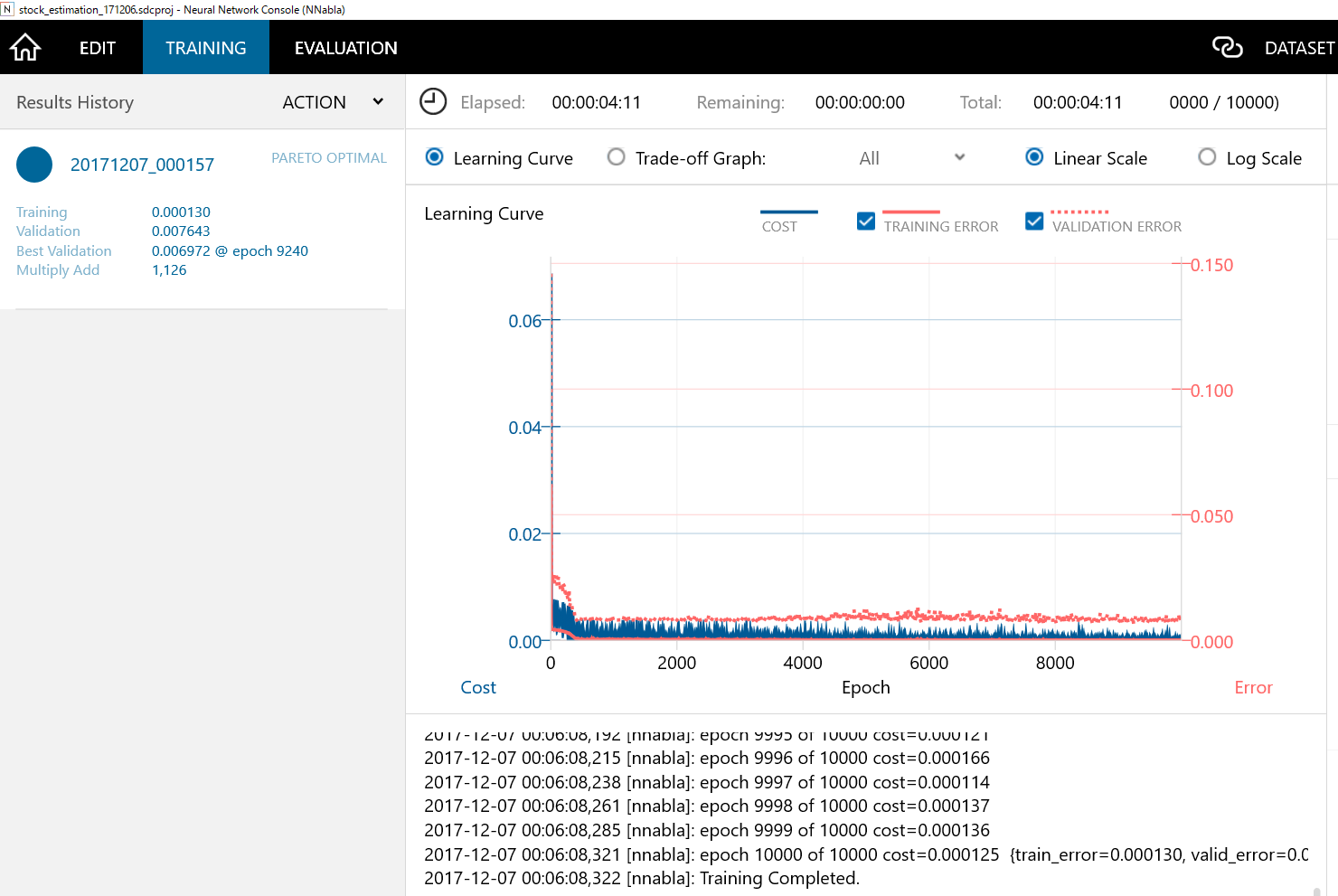
- Training ErrorとValidation Errorに多少の開きがありますが、Evaluationで確認してみます。
-
Evaluationの▶を押して、しばらく待つと以下のような画面になります。
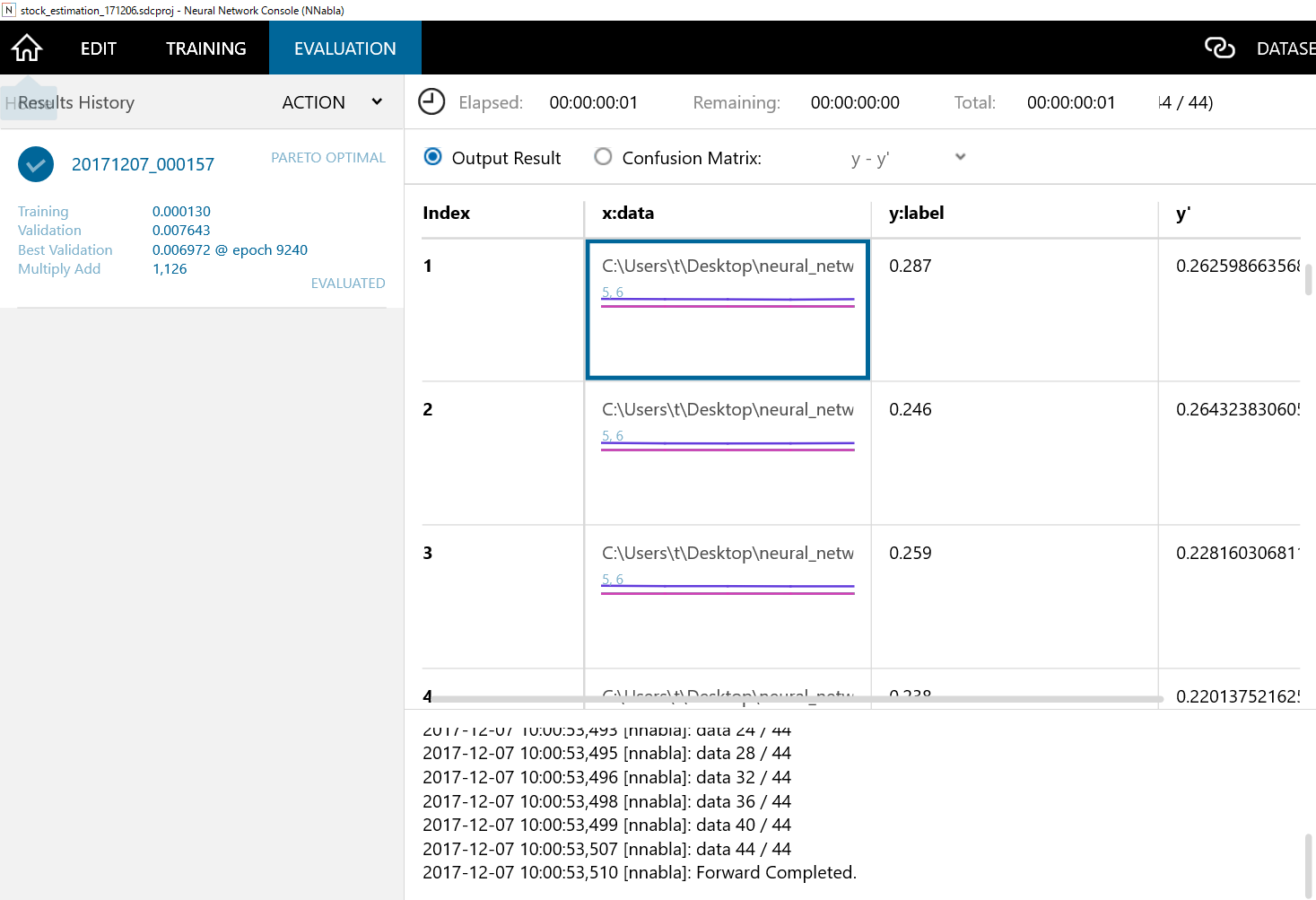
- 見た限りだとどうだかわかりづらいので、Excelなどでy(正解値),y'(推定値)をグラフ化してみましょう。グラフにするファイルは、stock_dataフォルダの中にある、~.filesのフォルダの中のoutput_result.csvです。
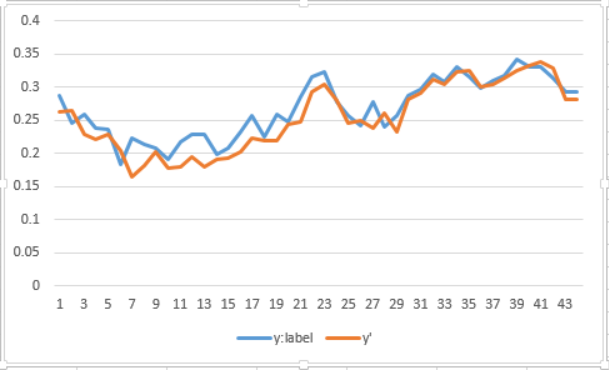
- まだ、改善の余地はありますが、割りとよくできている感じがしますね。
- 見た限りだとどうだかわかりづらいので、Excelなどでy(正解値),y'(推定値)をグラフ化してみましょう。グラフにするファイルは、stock_dataフォルダの中にある、~.filesのフォルダの中のoutput_result.csvです。
おわりに
- 今回は、NNCを使って株価を予測するモデルの作成までなってしまいましたが、次回は、学習モデルを使ったアプリケーションを作成まで紹介できたらと思います。
参考
http://cedro3.com/ai/future-prediction-dl/
http://arakan-pgm-ai.hatenablog.com/entry/2017/10/17/080000
http://cedro3.com/ai/nikkei-stock-dl/