はじめに
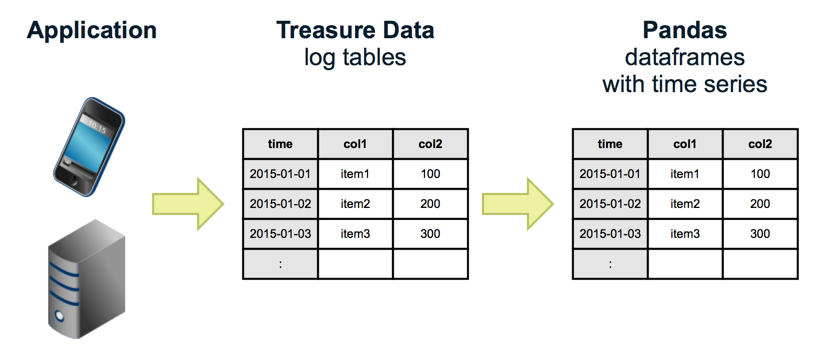
TreasureDataは、アプケーションログやセンサーデータなど時系列のデータを簡単に収集・保管・分析が行えるクラウドサービスです。
現在は、分析エンジンの一つとして、Prestoが利用できるようになり、収集したデータをインタラクティブにSQLで分析が行えるようになりました。
しかし、SQLでデータを分析したデータを元に可視化をするという機能自体はTreasureDataでは備えていないため、ExcelやTableauなどの外部ツールを使って、可視化を行う必要があります。
そこで今回は、Pythonのライブラリとして人気があるPandasと、WebブラウザでインタラクティブにPythonを実行できるJupyterを利用して、TreasureDataとインタラクティブにSQLを実行して集計・可視化を行っていきます。
セットアップ
利用環境
- Ubuntu 14.04
- Python 3.4
- Pandas
- Jupyterhub
TreasureData
サインアップ
こちらのページからサインアップを行います。現在のところ、14日間のトライアル期間があるため、その間はPrestoを利用することが可能です。
Pandas
Pandasは、公式から引用すると、下記みたいな感じのツールです。
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
Pythonのインストール
Ubuntu14.04ではPython3.4が入っているが、python3がエイリアスになっていたりして、面倒なので、pyenvで環境構築を行います。
参考: http://qiita.com/akito1986/items/be5dcd1a502aaf22010b
$ sudo apt-get install git gcc g++ make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev
$ cd /usr/local/
$ sudo git clone git://github.com/yyuu/pyenv.git ./pyenv
$ sudo mkdir -p ./pyenv/versions ./pyenv/shims
$ echo 'export PYENV_ROOT="/usr/local/pyenv"' | sudo tee -a /etc/profile.d/pyenv.sh
$ echo 'export PATH="${PYENV_ROOT}/shims:${PYENV_ROOT}/bin:${PATH}"' | sudo tee -a /etc/profile.d/pyenv.sh
$ source /etc/profile.d/pyenv.sh
$ pyenv -v
pyenv 20150601-1-g4198280
$ sudo visudo
# Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
Defaults env_keep += "PATH"
Defaults env_keep += "PYENV_ROOT"
$ sudo pyenv install -v 3.4.3
$ sudo pyenv global 3.4.3
$ sudo pyenv rehash
Pandasのインストール
$ sudo pip install --upgrade pip
$ sudo pip install pandas
Pandasをシェルから使ってみる
10 Minutes to pandasを参考にしてみてね。
Jupyter
Jupyterは元々、IPythonと呼ばれるPython用のWebブラウザのインタラクティブシェルだったのですが、現在は言語を問わず利用できるようにすることを目指して、名前を変えて開発が進められてます。
また、JuptyerHubは、複数ユーザでJupyterを使えるようにしたサーバ版Jupyterとなっており、簡単にJuypterで作成したnotebookを共有できるようになったりしてます。
JupyterHubのインストール
$ sudo apt-get install npm nodejs-legacy
$ sudo npm install -g configurable-http-proxy
# 関連ライブラリ
$ sudo pip install zmq jsonschema
# 可視化用ライブラリ
$ sudo apt-get build-dep python-matplotlib
$ sudo pip install matplotlib
$ git clone https://github.com/jupyter/jupyterhub.git
$ cd jupyterhub
$ sudo pip install -r requirements.txt
$ sudo pip install .
$ sudo passwd ubuntu
$ jupyterhub
これでJupterをWebブラウザから開いてアクセスすることが可能です。
http://(IP address):8000/
その他、JupyterHubの細かい設定はこちらを参照。
JupyterからPandasを使う
まずは、ログインをしてみます。すると、ログインユーザのユーザディレクトリが表示されます。ここに、Jupyterの作業用ディレクトリを作り、作業を記録するNotebookを作ります。
New -> Notebooks (Python3)を選択します。

このNotebookに、Pythonのコマンドの一連の流れを保存することができます。
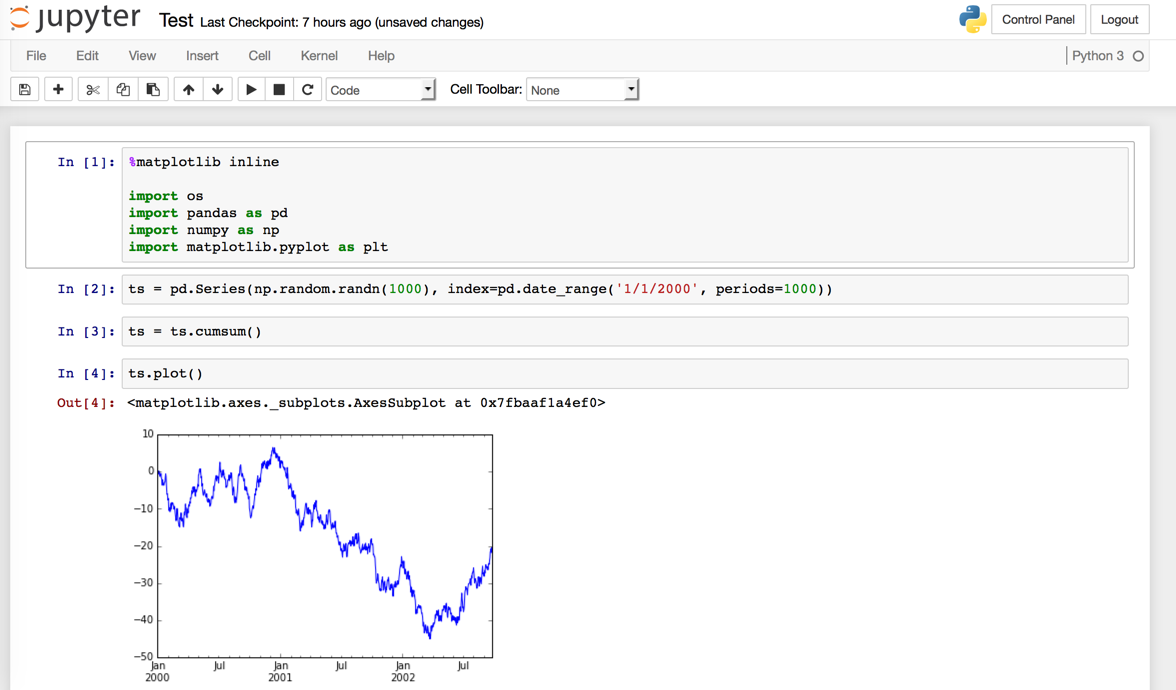
さて試しにこちらを元にテストをしてみましょう。
%matplotlib inline
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()
ToDo: 最初のimportとかを下記のconfigで省略できるっぽいのですが、まだうまくできていないので、確認中...
$ jupyterhub --generate-config
Writing default config to: jupyterhub_config.py
$ vi jupyterhub_config.py
c.IPKernelApp.matplotlib = 'inline'
c.InteractiveShellApp.exec_lines = [
'import pandas as pd',
'import numpy as np',
'import matplotlib.pyplot as plt',
]
$ mv jupyterhub_config.py .ipython/profile_default/
pandas-tdを使ってTreasureDataとPandasの連携
ここまでで一通りPandasとJupyterが使えるようになっているはずなので、さらにTreasureDataへアクセスしたいと思います。
ここでは、pandas-tdというライブラリを利用します。
これを用いることで3つのことができるようになります。
- TreasureDataのテーブルにデータを入れる
- TreasureDataのテーブルからデータを取り出す
- TreasureDataでクエリを実行して結果を得る
インストール
$ sudo pip install pandas-td
接続設定
%matplotlib inline
import os
import pandas as pd
import pandas_td as td
# 環境変数に入れておけば、便利
# con = td.connect(apikey="os.environ['TD_API_KEY']", endpoint='https://api.treasuredata.com/')
con = td.connect(apikey="TD API KEY", endpoint='https://api.treasuredata.com/')
クエリを発行する
engine = con.query_engine(database='sample_datasets', type='presto')
# Read Treasure Data query into a DataFrame.
df = td.read_td('select * from www_access', engine)
df
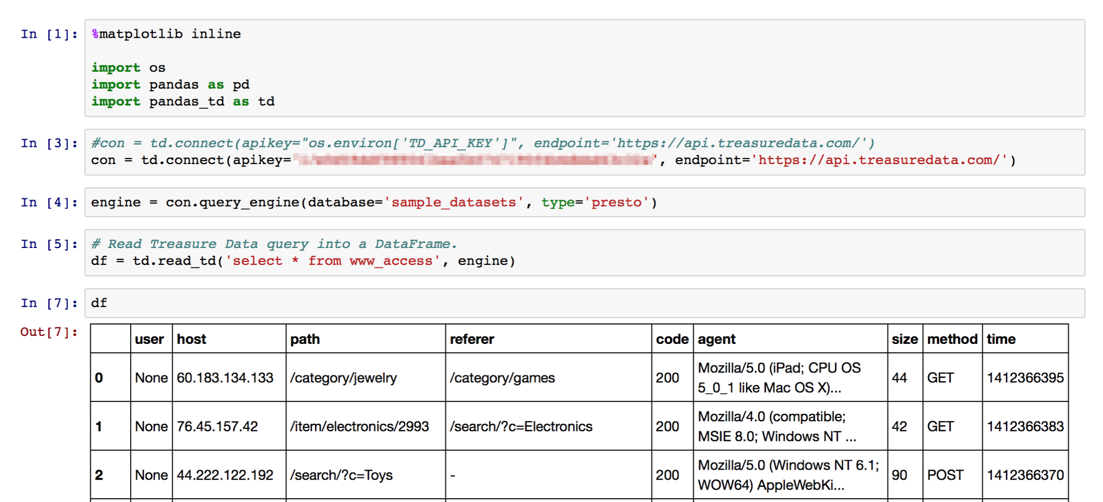
データを一部見てみる
engine = con.query_engine(database='sample_datasets', type='presto')
con.tables('sample_datasets')
td.read_td_table('nasdaq', engine, limit=3, index_col='time', parse_dates={'time': 's'})
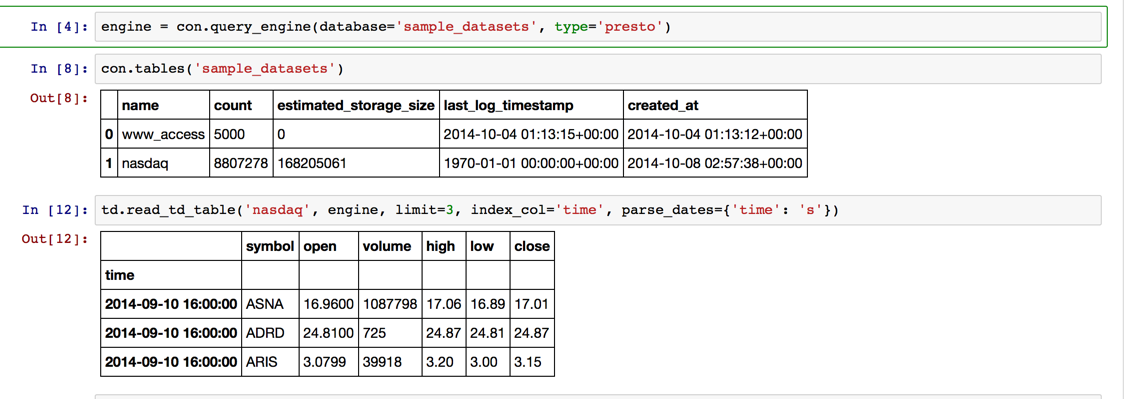
期間を絞って取得して、日付ごとの集計を行って、可視化する
df = td.read_td_table('nasdaq', engine, limit=None, time_range=('2010-01-01', '2010-02-01'), index_col='time', parse_dates={'time': 's'})
df.groupby(level=0).volume.sum().plot()
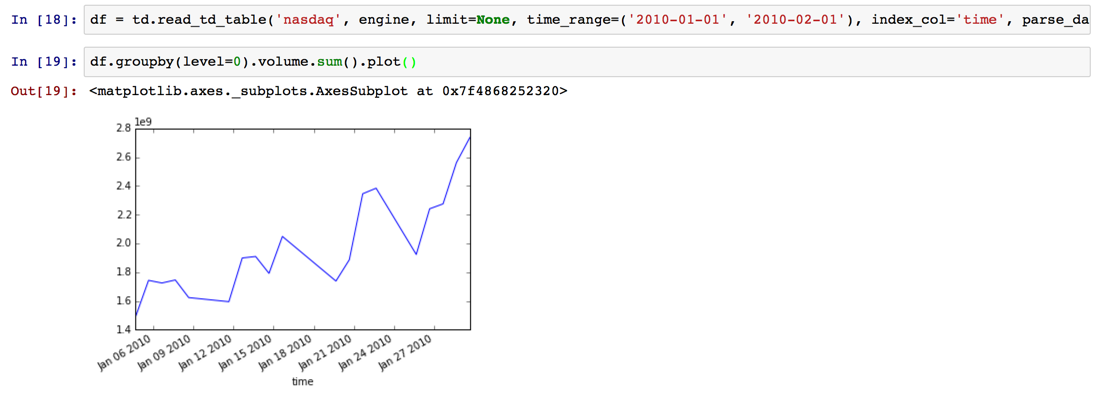
何が便利か
途中処理を簡単に書き直してリトライができる。
数百万件程度ならダウンロードした結果を元にメモリ上で処理が行える。
MySQLやCSVファイルからもデータを持ってこれる。
などなど。
おわりに
途中で力尽きた感が否めないので、そのうちちゃんともっと書く。