個人的な理由でデータ分析する必要がありいろいろと試行錯誤した記録です。
ほんとうはもっとスマートな方法があるかもしれませんので参考程度に。
たとえば以下のデータがあったとします。
動物と動物に与えた食物を「開始日付」と「終了日付」で期間管理をしています。
飼育表A
| 動物 | 開始日付 | 終了日付 | 食物 |
|---|---|---|---|
| 2018/01/01 | 2018/01/15 | ||
| 2018/01/16 | 2018/03/31 | ||
| 2018/01/01 | 2018/03/31 |
諸々の理由により、猫については同じ食物なのに複数の期間に分かれて登録されてしまいました。実際のデータはめっっっっっっっっっっっっちゃ細かい期間にわかれています( ;∀;)
動物と食物の関係がいつ開始でいつ終了なのかすぐにわかりたい。
ということで今回は期間の無駄を省いて抽出する方法を考えます。
ほしい抽出結果
| 動物 | 開始日付 | 終了日付 | 食物 |
|---|---|---|---|
| 2018/01/01 | 2018/03/31 | ||
| 2018/01/01 | 2018/03/31 |
検討1:GROUP BY は使えるか?
集約と聞いて一番最初におもいつくのは、Group By です。
動物と食物の組み合わせを集約することはできますが
今回のような日付を扱う集約には使えません。
検討2:MIN・MAXは使えるか?
次に思いつくのは MIN・MAXです。
動物と食物で Group By しつつ、最小の開始日と最大の終了日を求める方法はどうでしょうか。
SELECT "動物", min("開始日付"), max("終了日付"), "食物"
FROM "飼育表A"
GROUP BY "動物", "食物"
| 動物 | 開始日付 | 終了日付 | 食物 |
|---|---|---|---|
| 2018/01/01 | 2018/03/31 | ||
| 2018/01/01 | 2018/03/31 |
うまくいきました!
・・・しかし、もしも飼育表Bのような場合はどうでしょうか。
![]() ではなく
ではなく ![]() を食物としている期間が間にあります。
を食物としている期間が間にあります。
飼育表B
| 動物 | 開始日付 | 終了日付 | 食物 |
|---|---|---|---|
| 2018/01/01 | 2018/01/15 | ||
| 2018/01/16 | 2018/01/31 | ||
| 2018/02/01 | 2018/02/28 | ||
| 2018/03/01 | 2018/03/31 | ||
| 2018/01/01 | 2018/03/31 |
↓
SQL抽出結果
| 動物 | 開始日付 | 終了日付 | 食物 |
|---|---|---|---|
| 2018/01/01 | 2018/03/31 | ||
| 2018/01/16 | 2018/02/28 | ||
| 2018/01/01 | 2018/03/31 |
MIN・MAXがダメな点
・![]() と
と ![]() の期間が重複した結果を作ってしまってウソの集約になる。
の期間が重複した結果を作ってしまってウソの集約になる。
・もし日付が不連続だった場合もウソの集約になる。
検討3 Window関数は使えるか?
PostgreSQL や Oracle には Window関数というのがあります。
Window関数 | Let's Postgres より引用
Window関数はテーブルを区間ごとに集計する機能です。集約関数 (GROUP BY) に似ていますが、Window関数では複数の行がまとめられることはなく、行それぞれが返却されます。また、処理中の行以外の行の値を読み取ることも可能です。
Window関数は以下の構文を使います。
関数(...) OVER (PARTITION BY ...) : 区間に分割
関数(...) OVER (ORDER BY ...) : 区間ごとに並び替え
つまり、Window関数を使うと以下の2つのことが同時にできます。
1)Partition By で Group By のように項目を複数指定するだけで、区間の分割位置を教えてくれる。
2)関数 LAG や LEAD を使うことで前後の行から好きな項目を取ってきて横並びにできる。
今回のケースにこのWindow関数を当てはめると以下のステップで実現できます。
・区間で区切る
・前後行から日付を取得
・日付が連続しているか判定する
・連続区間の最初と最後の行だけに集約する
・連続区間最初の開始日付と区間最後の終了日付だけにする
今回は「動物と食物」の組み合わせを区間として区切ります。
次に区間の中で、前後行から日付を取得して現在行と横並びにします。区間外の日付は取ってこないのでNULLになります。
横並びが実現出来るとWHERE句の中で、現在行の日付と前後行の日付が連続しているかを簡単に比較ができます。
・区間内で日付が連続している=集約できる
・区間内で日付が連続していない=集約できない
集約できなかった行から残すべき開始日付か終了日付を取り出せば集約完了です。
ではSQLと結果を示しながら順に説明します。
区間で区切る
飼育表B
| 動物 | 開始日付 | 終了日付 | 食物 |
|---|---|---|---|
| 2018/01/01 | 2018/01/15 | ||
| 2018/01/16 | 2018/01/31 | ||
| 2018/02/01 | 2018/02/28 | ||
| 2018/03/01 | 2018/03/31 | ||
| 2018/01/01 | 2018/03/31 |
以下のような区間で区切ることがイメージできます。
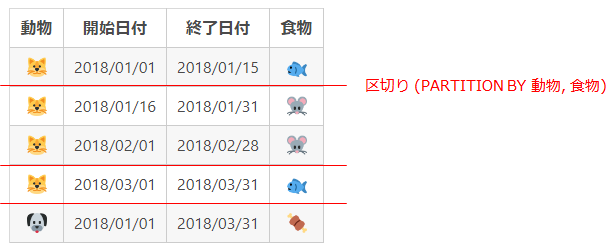
具体的には、OVER(PARTITION BY 動物,食物) です。
前後行から日付を取得
・前の行から終了日付を得る : LAG(終了日付)
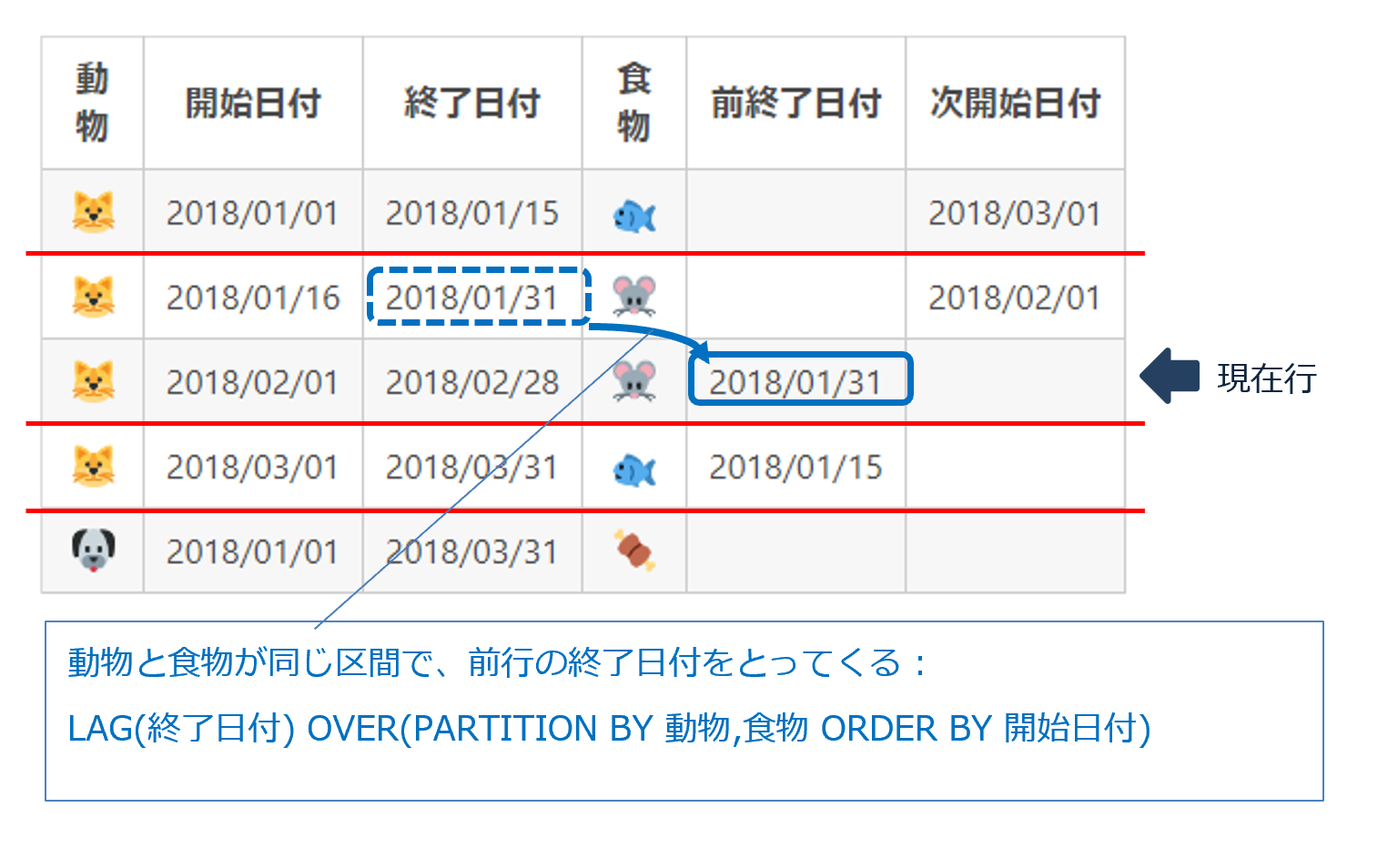
・後の行から開始日付を得る : LEAD(開始日付)
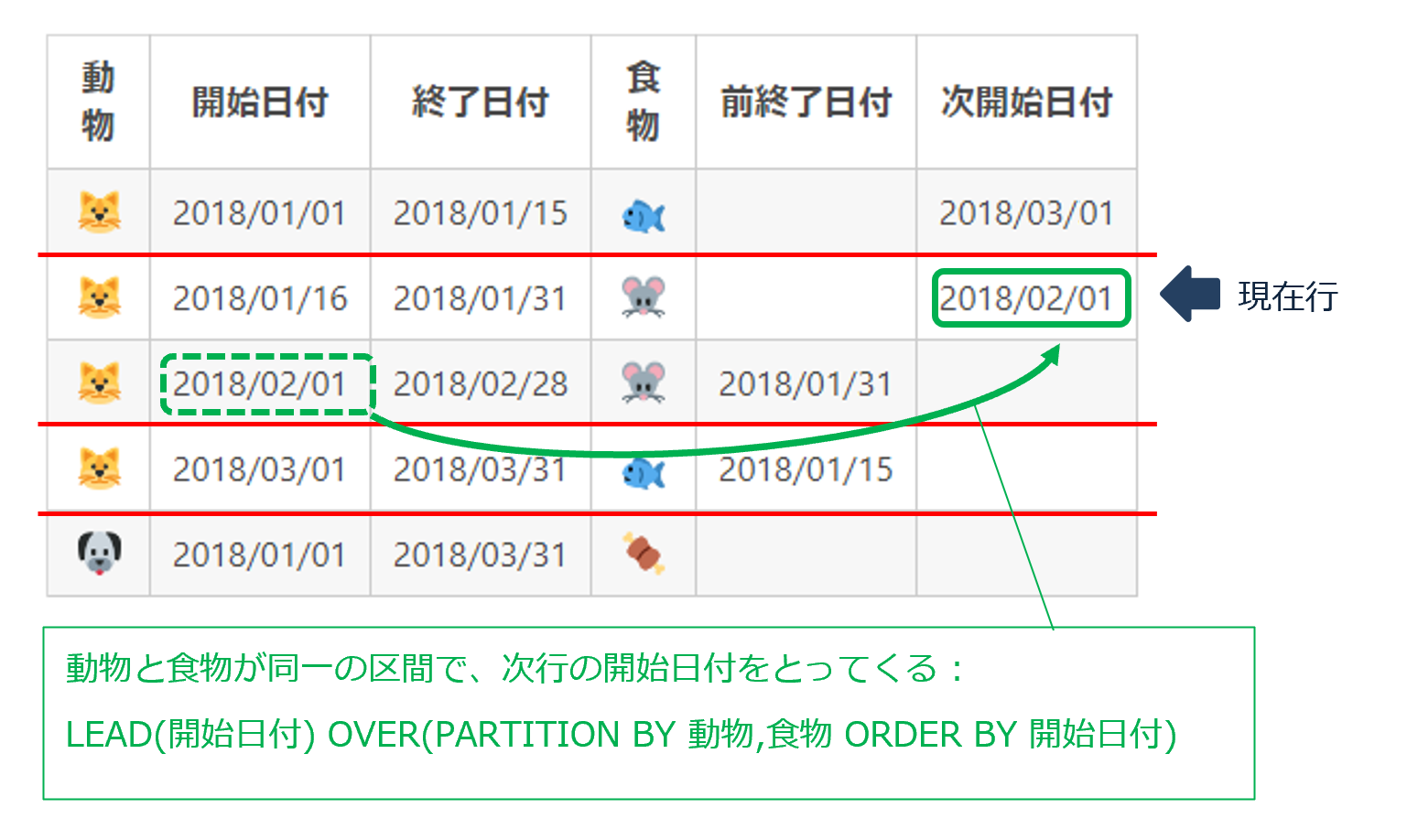
SELECT
"動物",
"開始日付",
"終了日付",
"食物",
LAG("終了日付") OVER(PARTITION BY "動物","食物" ORDER BY "開始日付") AS "前終了日付",
LEAD("開始日付") OVER(PARTITION BY "動物","食物" ORDER BY "開始日付") AS "次開始日付"
FROM "飼育表B"
ORDER BY "動物", "開始日付"
| 動物 | 開始日付 | 終了日付 | 食物 | 前終了日付 | 次開始日付 |
|---|---|---|---|---|---|
| 2018/01/01 | 2018/01/15 | 2018/03/01 | |||
| 2018/01/16 | 2018/01/31 | 2018/02/01 | |||
| 2018/02/01 | 2018/02/28 | 2018/01/31 | |||
| 2018/03/01 | 2018/03/31 | 2018/01/15 | |||
| 2018/01/01 | 2018/03/31 |
NULLとなっているところは区間の切れ目で間違いないので
次に日付が連続しているかを調べます。
日付が連続しているか判定する
・終了日付 = (次開始日付 - 1) であれば、次の行と連続していますので
区間の途中であり省略可能を意味します。
もしイコールでなければ、この終了日付でもって区間は終わりなので必要です。
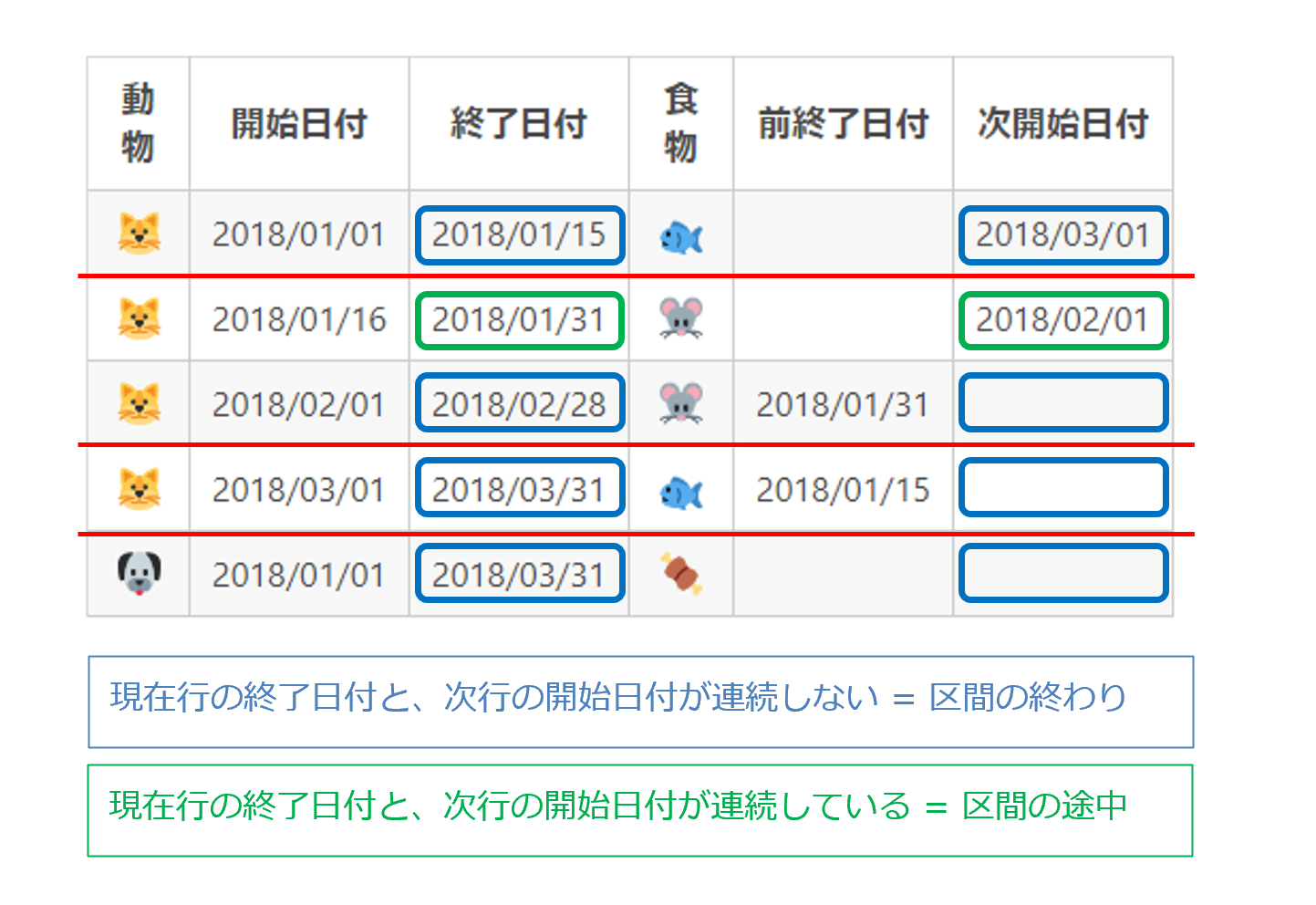
・開始日付 = (前終了日付 + 1) であれば、前の行と連続していますので
区間の途中であり省略可能を意味します。
もしイコールでなければ、この開始日付でもって区間が始まりますので必要です。
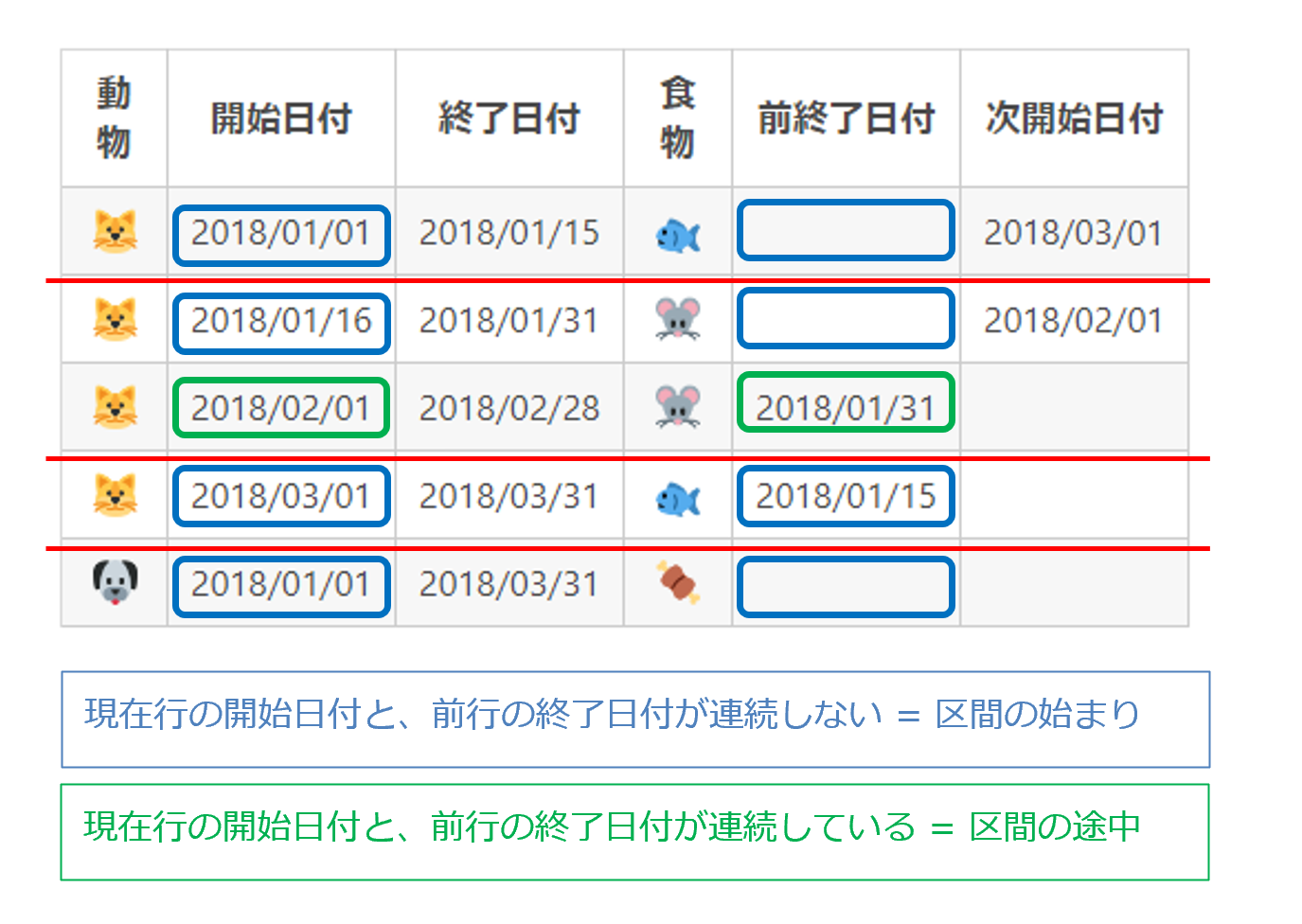
といった判定を行った結果をフラグ項目として付け加えることをします。
なおここからはWITH問い合わせを使います。
SQLの結果を一時テーブルとして扱うことで
SQLが見やすくなります。
WITH SB AS(
SELECT
"動物",
"開始日付",
"終了日付",
"食物",
LAG("終了日付") OVER(PARTITION BY "動物","食物" ORDER BY "開始日付") AS "前終了日付",
LEAD("開始日付") OVER(PARTITION BY "動物","食物" ORDER BY "開始日付") AS "次開始日付"
FROM "飼育表B"
ORDER BY "動物", "開始日付"
)
SELECT
SB.*
,CASE WHEN SB."前終了日付" + 1 <> SB."開始日付" THEN '1'
WHEN SB."前終了日付" + 1 = SB."開始日付" THEN '0'
WHEN SB."前終了日付" IS NULL THEN '1'
END AS "開始差有"
,CASE WHEN SB."次開始日付" - 1 <> SB."終了日付" THEN '1'
WHEN SB."次開始日付" - 1 = SB."終了日付" THEN '0'
WHEN SB."次開始日付" IS NULL THEN '1'
END AS "終了差有"
FROM SB
| 動物 | 開始日付 | 終了日付 | 食物 | 前終了日付 | 次開始日付 | 開始差有 | 終了差有 |
|---|---|---|---|---|---|---|---|
| 2018/01/01 | 2018/01/15 | 2018/03/01 | 1 | 1 | |||
| 2018/01/16 | 2018/01/31 | 2018/02/01 | 1 | 0 | |||
| 2018/02/01 | 2018/02/28 | 2018/01/31 | 0 | 1 | |||
| 2018/03/01 | 2018/03/31 | 2018/01/15 | 1 | 1 | |||
| 2018/01/01 | 2018/03/31 | 1 | 1 |
連続区間の最初と最後の行だけに集約する
開始差有と終了差有の両方とも0であれば不要な行です。(今回の例では該当なし。)
開始差有か終了差有のどちらかが1になっている行だけ残せば、区間の最初と最後の行だけになります。
最初と最後の行が並べば、LEAD関数で最後の終了日をとってくることができます。
WITH SB AS(
SELECT
"動物",
"開始日付",
"終了日付",
"食物",
LAG("終了日付") OVER(PARTITION BY "動物","食物" ORDER BY "開始日付") AS "前終了日付",
LEAD("開始日付") OVER(PARTITION BY "動物","食物" ORDER BY "開始日付") AS "次開始日付"
FROM "飼育表B"
ORDER BY "動物", "開始日付"
)
, C AS (
SELECT
SB.*
,CASE WHEN SB."前終了日付" + 1 <> SB."開始日付" THEN '1'
WHEN SB."前終了日付" + 1 = SB."開始日付" THEN '0'
WHEN SB."前終了日付" IS NULL THEN '1'
END AS "開始差有"
,CASE WHEN SB."次開始日付" - 1 <> SB."終了日付" THEN '1'
WHEN SB."次開始日付" - 1 = SB."終了日付" THEN '0'
WHEN SB."次開始日付" IS NULL THEN '1'
END AS "終了差有"
FROM SB
)
SELECT
C.*
,CASE WHEN C."開始差有" = '1' AND C."終了差有" = '0' THEN LEAD(C."終了日付") OVER(PARTITION BY C."動物" ORDER BY C."開始日付")
WHEN C."開始差有" = '1' AND C."終了差有" = '1' THEN C."終了日付"
WHEN C."開始差有" = '0' AND C."終了差有" = '1' THEN NULL
END AS "新終了日付"
FROM C
WHERE C."開始差有" = '1' OR C."終了差有" = '1'
| 動物 | 開始日付 | 終了日付 | 食物 | 前終了日付 | 次開始日付 | 開始差有 | 終了差有 | 新終了日付 |
|---|---|---|---|---|---|---|---|---|
| 2018/01/01 | 2018/01/15 | 2018/03/01 | 1 | 1 | 2018/01/15 | |||
| 2018/01/16 | 2018/01/31 | 2018/02/01 | 1 | 0 | 2018/02/28 | |||
| 2018/02/01 | 2018/02/28 | 2018/01/31 | 0 | 1 | ||||
| 2018/03/01 | 2018/03/31 | 2018/01/15 | 1 | 1 | 2018/03/31 | |||
| 2018/01/01 | 2018/03/31 | 1 | 1 | 2018/03/31 |
連続区間の最初の開始日付と区間最後の終了日付だけにする
ここまで来たら、区間最初の行に区間最後の終了日付が入っているので、ほぼ完成です。
最後の仕上げとして、新終了日付がNULLになっている不要な行を消します。
WITH SB AS(
SELECT
"動物",
"開始日付",
"終了日付",
"食物",
LAG("終了日付") OVER(PARTITION BY "動物","食物" ORDER BY "開始日付") AS "前終了日付",
LEAD("開始日付") OVER(PARTITION BY "動物","食物" ORDER BY "開始日付") AS "次開始日付"
FROM "飼育表B"
ORDER BY "動物", "開始日付"
)
, C AS (
SELECT
SB.*
,CASE WHEN SB."前終了日付" + 1 <> SB."開始日付" THEN '1'
WHEN SB."前終了日付" + 1 = SB."開始日付" THEN '0'
WHEN SB."前終了日付" IS NULL THEN '1'
END AS "開始差有"
,CASE WHEN SB."次開始日付" - 1 <> SB."終了日付" THEN '1'
WHEN SB."次開始日付" - 1 = SB."終了日付" THEN '0'
WHEN SB."次開始日付" IS NULL THEN '1'
END AS "終了差有"
FROM SB
)
, R AS (
SELECT
C.*
,CASE WHEN C."開始差有" = '1' AND C."終了差有" = '0' THEN LEAD(C."終了日付") OVER(PARTITION BY C."動物" ORDER BY C."開始日付")
WHEN C."開始差有" = '1' AND C."終了差有" = '1' THEN C."終了日付"
WHEN C."開始差有" = '0' AND C."終了差有" = '1' THEN NULL
END AS "新終了日付"
FROM C
WHERE C."開始差有" = '1' OR C."終了差有" = '1'
)
SELECT
R."動物",
R."開始日付",
R."新終了日付" AS "終了日付",
R."食物"
FROM R
WHERE R."新終了日付" IS NOT NULL
ということで
飼育表B(元データ)
| 動物 | 開始日付 | 終了日付 | 食物 |
|---|---|---|---|
| 2018/01/01 | 2018/01/15 | ||
| 2018/01/16 | 2018/01/31 | ||
| 2018/02/01 | 2018/02/28 | ||
| 2018/03/01 | 2018/03/31 | ||
| 2018/01/01 | 2018/03/31 |
SQL抽出結果↓
| 動物 | 開始日付 | 終了日付 | 食物 |
|---|---|---|---|
| 2018/01/01 | 2018/01/15 | ||
| 2018/01/16 | 2018/02/28 | ||
| 2018/03/01 | 2018/03/31 | ||
| 2018/01/01 | 2018/03/31 |
うまく抽出できました!
まとめ
・区間で区切る
・前後行から日付を取得
・日付が連続しているか判定する
・連続区間の最初と最後の行だけに集約する
・連続区間最初の開始日付と区間最後の終了日付だけにする
今回の例はたいしたことはないですが、期間がどんなに連続していてもおなじことなので問題ありません。
また区間を分割するカギとなる項目が増えたとしても、Partition By に並べるだけですみます。
これは何かしらのプログラムを書く場合より(たぶん)高速で応用が利きそうです。
Window関数は素晴らしいですね。