初めに
本記事では
- Graphvizを使ったことがない筆者がjupyter-notebookでGraphvizを使う
という内容になっています。ちなみにネットにはGraphvizの使い方など色々載っています。例えば
とかです。上記の2つの記事のどちらで設定しても使えるようになります。サイトを見てみてこれでいいかなと感じたらそれでもぜんぜん大丈夫です。
今回は2つの記事を少しミックスして環境を作っていこうと思います。
Graphvizとは
初めにGraphvizについて軽く説明していきます。以下のサイトを要約した形になっていると思います。
GraphvizとはGraph Visualization Softwareの略語で、グラフを作成する用のツールです。
dot言語と呼ばれるデータ記述言語を使って記述したテキストファイルを画像ファイルとして変換し出力することが出来ます。
機械学習の決定木を描画する時とかにも使われ、「Windows、Mac、Linux」に対応しています。
ちなみにdotとは有向グラフを描画するプログラムのことらしいです。
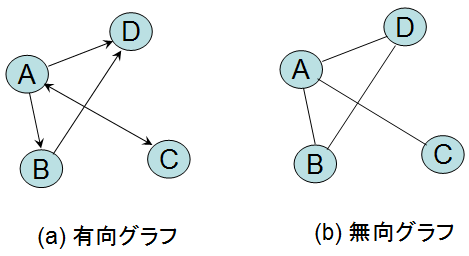
上の図が有向グラフと無向グラフの違いです。言葉で説明すると、ある頂点から別の頂点への特定の方向が決められているかいないかです。上の図の矢印があるかないかですね。
つまり、それぞれの頂点の関係性が固定されているかされていないかということです。
例を挙げるとするならば、有向グラフはハイパーリンク、無向グラフは電車の路線図などではないでしょうか。ハイパーリンクはクリックしたら元のページに戻ることができず(戻るボタンは考えないで下さい笑)、電車はそれぞれの隣り合った駅を自由に行き来することができます。
Graphvizインストール
今回試したインストール方法は2つあります。ちなみに公式サイトのダウンロードのページに行くと上記サイトで紹介されていたものとは違いました。
- 公式サイトからダウンロードする方法
-
zipファイルを落とす方法zipファイル先のリンクが死んでました
この2つの方法です。
公式サイトからダウンロード
まず、こちらの公式サイトのリンクをクリックしてください。
次にダウンロードをクリック
WindowsのところのGraphviz Windows packagesをクリック
githubのページに飛ぶので「2.38yaml」というファイルを選択し
Urlのところに貼ってあるリンクを検索したら勝手にダウンロードされます
あとはインストーラーを起動してインストールを開始してください。こちらのサイトを参考にしてもいいかもしれません。「everyone」のところにチェックを付けるかどうかはパソコンのアカウントの数で判断してみてください。
### zipファイルを落とす
zipファイルを落とすのはこちらのサイトから落とせます。落としたら、そのファイルを展開するだけで大丈夫です。
実装
今回はタイタニック号の生き残りのデータセットを使って決定木のグラフの可視化をしていきます。このコードはこちらの方のコードを参考にしています。jupyter風に分けて書いていこうと思います。
まずは必要ライブラリの読み込みです。(userの部分は各自のアカウント名です)
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc, accuracy_score
import pandas as pd
from sklearn.tree import export_graphviz
import pydotplus
from io import StringIO
from IPython.display import Image
# データの読み込み
train = pd.read_csv("/Users/user/jupyter/train.csv")
基本的に一般のデータセットは欠損値があるそうなので確認
train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
Age、Cabin、Embarkedに欠損値があるようです。今回はCabinは使わないので無視します。
Ageの欠損値にはAge全体の平均を補完し、Embarkedには最頻値の"S"を補完します。
train["Age"] = train["Age"].fillna(train["Age"].median())
train["Embarked"] = train["Embarked"].fillna("S")
学習する際には、int型にしないといけないので文字列の'Sex'と'Embarked'を数字に変換します。今回は手作業で数字を割り当てていますが、ダミー変数を使っても変換可能です。
#カテゴリ変数の変換
train['Sex'] = train['Sex'].apply(lambda x: 1 if x == 'male' else 0)
train['Embarked'] = train['Embarked'].map( {'S': 0 , 'C':1 , 'Q':2}).astype(int)
使わないクラスを消します。
train = train.drop(['Cabin','Name','PassengerId','Ticket'],axis =1)
データの前処理が終わったので一旦欠損値がないか確認します。
train.isnull().sum()
Survived 0
Pclass 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
欠損値をなくすことができました。次にtrain用のデータセットとtest用のデータセットを分けていきます。テストの画像の振り分けは全体の3割にしました。
#学習データとテストデータに分割
train_X = train.drop('Survived',axis = 1)
train_y = train.Survived
(train_X , test_X , train_y , test_y) = train_test_split(train_X, train_y , test_size = 0.3 , random_state = 0)
モデルを構築し、学習を行います。深さは3層にしました。
#train
model = DecisionTreeClassifier(max_depth=3,random_state = 0)
model.fit(train_X , train_y)
#accuracy
pred = model.predict(test_X)
fpr, tpr, thresholds = roc_curve(test_y , pred,pos_label = 1)
auc(fpr,tpr)
print("accuracy=",accuracy_score(pred,test_y)
accuracy=0.8208955223880597
ここからGraphvizで描画していきます。
# 文字列をファイルオブジェクトのように扱うための処理をする
dot_data = StringIO()
export_graphviz(
model, out_file=dot_data,
feature_names=train_X.columns,
class_names=["Death", "Survival"]
)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
#graphvizをダウンロードしたディレクトリの絶対パスを指定
graph.progs = {'dot': u"C:\\Users\\user\\anaconda3\\bin\\release\\bin\\dot.exe"}
# ノートブックに可視化
Image(graph.create_png())
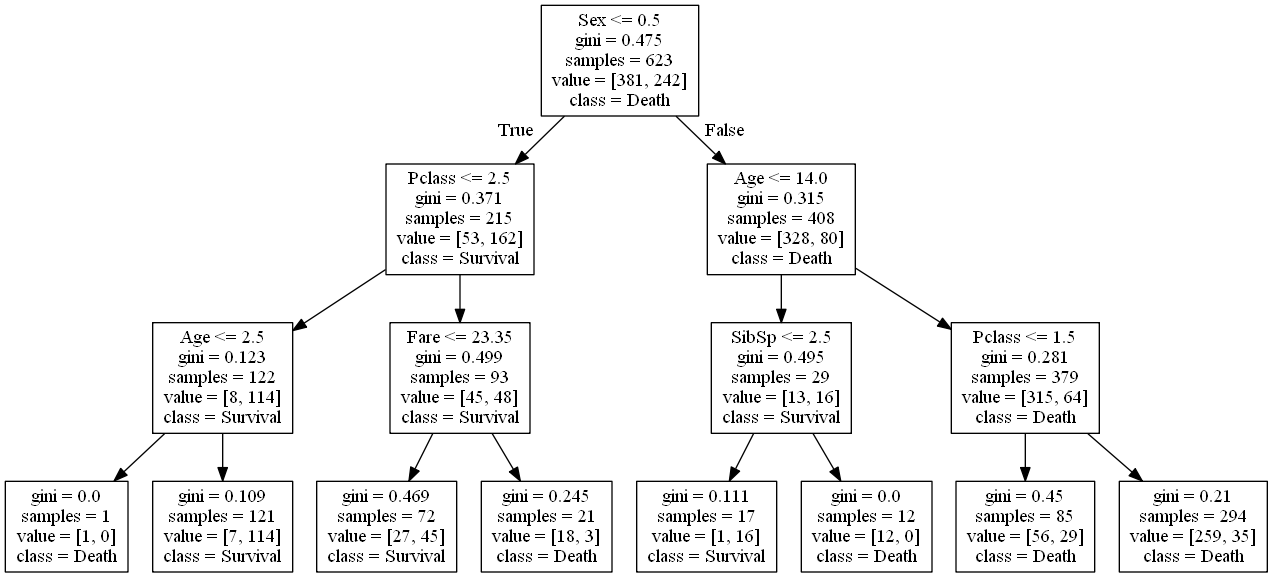
決定木を描画することができました。
最後に
今回はjupyterを使って行いましたが、もちろん他のIDEでも可能です。ちなみに、一番苦労したのは公式サイトからインストールファイルを見つけることでした。