夜をこめてとりのそらねははかるともよに逢坂の関は許さじ
Advent Calendar 2022 114日目1の記事です。
I'm looking forward to 12/25,2022 ![]()
![]()
![]()
![]()
![]()
![]()
私のAdvent Calendar 2022 一覧。
はじめに
Elixir を楽しんでいますか![]()
![]()
![]()
この記事は、「動的にJavaScriptで出力されるhtmlデータ」を取得することをやってみます。
Pythonの記事が多いです。
とても参考にさせてもらいました。
私はもちろん、Elixirを使います。
準備
まず準備を進めます。
私はmacOSを使っています。
スクレイピングする対象
ヨソサマにご迷惑をかけぬようにしたいとおもいます。
おもうだけでは駄目なので、簡易なものを手元に用意します。
スクレイピングする対象を用意するというわけです。
以下、一例を示します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>Vue.js App</title>
</head>
<body>
<div id="list-rendering">
<ol>
<li v-for="todo in todos">
{{ todo.text }}
</li>
</ol>
</div>
<script
src="https://unpkg.com/vue@next"></script>
<script src="main.js"></script>
</body>
</html>
const ListRendering = {
data() {
return {
todos: [
{ text: 'Learn JavaScript' },
{ text: 'Learn Vue' },
{ text: 'Build something awesome' }
]
}
}
}
Vue.createApp(ListRendering).mount('#list-rendering')
上記の2ファイルを同じディレクトリに置いておきます。
たとえばDockerをお使いの場合は以下のようにするとよいでしょう。
docker run --rm -v $(pwd):/usr/share/nginx/html:ro -p 8080:80 -d nginx
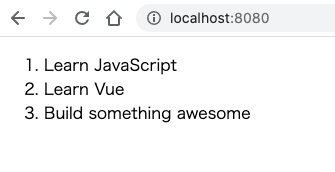
http://localhost:8080
に訪れると以下のようなページが表示されます。
ChromeブラウザとChromeDriverのインストール
雑な説明で恐縮ですが、今回は静的なページではなく、動的にJavaScriptで内容がかわるhtmlを解析したいので、スクレイピングプログラムの実行で、あたかもブラウザでアクセスしたかのようにアクセスをする必要があります。
それで、ChromeブラウザとChromeDriverのインストールが必要となります。
Chromeブラウザはリンク先のインストーラでインストールしました。
ChromeDriverは、Chromeブラウザのバージョンと近いものをインストールしておくことが吉のようです。
Chromeブラウザのバージョンは、右上の三点リーダ(︙)から確認できます。
私の場合は、ChromeDriverのページにあるLatest stable releaseがChromeブラウザとバージョンが近かったので、その.zipをダウンロードし、解凍して、下記のコマンドで/usr/local/bin/に配置しました。
sudo mv chromedriver /usr/local/bin/
あとで、スクレイピングを実行したときに、 「"chromedriver"は開発元を検証できないため開けません。」 と言われるかもしれません。
そのときはこちらの記事を参考にするとよいです。
この場をお借りして記事を書いてくださった方に感謝を申し上げます。
準備は以上です。
Elixirで楽しむ
wallabyを使います。
他に候補は、Houndがあります。
これらのライブラリの共通点は、テストのためというのを主眼に置いていることです。
つまりは自分のつくったアプリケーションのテストをしようね、と言うことを暗に言っているのだとおもいます。
テストの中にはふつうにElixirのプログラムが書けますので、テストの中でスクレイピングすることにします。
以下、wallabyのドキュメントに書いてある通りの手順です。
プロジェクトの作成
まずはプロジェクトを作っておきましょう。
mix new sample
wallabyの追加
mix.exsに、wallaby Hexを追加します。
defp deps do
[
{:wallaby, "~> 0.29.0", runtime: false, only: :test}
]
end
ファイルを変更後、mix deps.getで依存関係を解決します。
mix deps.get
test_helper.exs の変更
ExUnit.start()
{:ok, _} = Application.ensure_all_started(:wallaby) # add
Application.put_env(:wallaby, :base_url, "http://localhost:8080") # add
テストファイルを書く
defmodule ScrapingTest do
use ExUnit.Case, async: true
use Wallaby.Feature
feature "visit /index.html", %{session: session} do
page_source =
session
|> visit("/index.html")
|> page_source()
IO.puts(page_source)
end
end
Run
実行してみます。
mix test
結果![]()
![]()
![]()
<html lang="ja"><head>
<meta charset="utf-8">
<title>Vue.js App</title>
</head>
<body>
<div id="list-rendering" data-v-app=""><ol><li>Learn JavaScript</li><li>Learn Vue</li><li>Build something awesome</li></ol></div>
<script src="https://unpkg.com/vue@next"></script>
<script src="main.js"></script>
</body></html>
JavaScriptで動的に埋め込まれたデータが得られています!!!
main.jsの
todos: [
{ text: 'Learn JavaScript' },
{ text: 'Learn Vue' },
{ text: 'Build something awesome' }
]
この部分です。
- Learn JavaScript
- Learn Vue
- Build something awesome
(おまけ) テキストだけ取り出す ーー Flokiを簡単に紹介します
PythonのBeautiful Soupに相当するもとして、ElixirはFlokiがあります。
Flokiを利用して、動的に埋め込まれたテキストを取り出してみます。
mix.exsにFlokiを追加します。
defp deps do
[
{:wallaby, "~> 0.29.0", runtime: false, only: :test},
{:floki, "~> 0.32.0"}
]
end
mix.exsを変更したら、依存関係を解決します。
mix deps.get
test/scraping_test.exsを修正します。
Flokiの使い方はドキュメントをご参照ください ![]()
![]()
![]()
![]()
![]()
![]()
以下、使い方の一例を示します。
defmodule ScrapingTest do
use ExUnit.Case, async: true
use Wallaby.Feature
feature "visit /index.html", %{session: session} do
page_source =
session
|> visit("/index.html")
|> page_source()
IO.puts(page_source)
# add ここから
{:ok, document} = Floki.parse_document(page_source)
Floki.find(document, "li")
|> Enum.map(&Floki.text/1)
|> IO.inspect()
# add ここまで
end
end
実行してみます。
mix test
結果は、以下の通りテキストの値がしっかり取得できています! ![]()
![]()
![]()
["Learn JavaScript", "Learn Vue", "Build something awesome"]
本当にこんな面倒くさいことをしないといけないの?
ふつうにindex.htmlをHTTP GETしただけでは、ブラウザでのアクセスのようにJavaScriptが実行されず、本当にindex.htmlのみしか取得できません。
以下、実行例です。
iex
iex> Mix.install [:req]
:ok
iex> Req.get!("http://localhost:8080/index.html") |> Map.get(:body) |> IO.puts
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>Vue.js App</title>
</head>
<body>
<div id="list-rendering">
<ol>
<li v-for="todo in todos">
{{ todo.text }}
</li>
</ol>
</div>
<script
src="https://unpkg.com/vue@next"></script>
<script src="main.js"></script>
</body>
</html>
もちろん静的なページであれば、単純なHTTP GETでよいです。
今回のように、「動的にJavaScriptで出力されるデータ」がある場合には、ChromeDriverの力を借りると、あたかもブラウザでアクセスしている体となり、所望のhtmlが得られるわけです。
Wrapping up 
「動的にJavaScriptで出力されるhtmlデータ」をElixirを使って取得することを楽しんでみました。
久々に、AdventCalendar2022を書きました。
Enjoy Elixir![]()
![]()
![]()
$\huge{Enjoy\ Elixir🚀}$
参考記事
以下、参考にした記事です。
各記事の作者の方には、この場をお借りして御礼申し上げます。
Python
Pythonの記事です。
参考になるところがたくさんありました。
- Pythonスクレイピング:JavaScriptによる動的ページ、静的ページ、キャプチャ取得のそれぞれの手法をサンプルコード付きで解説
-
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12
- 注意事項はよく読みましょう
- seleniumを使用しようとしたら、「"chromedriver"は開発元を検証できないため開けません。」と言われた
- 【Python】ChromeDriverのエラーまとめ【selenium】
- Ubuntu + Python3 + Selenium + GoogleChrome でスクレイピング
Elixir
Elixirの記事です。
I organize autoracex.
And I take part in NervesJP, fukuoka.ex, EDI, tokyo.ex, Pelemay.
I hope someday you'll join us.
We Are The Alchemists, my friends!