$\huge{元氣ですかーーーーッ!!!}$
$\huge{元氣があればなんでもできる!}$
$\huge{闘魂とは己に打ち克つこと。}$
$\huge{そして闘いを通じて己の魂を磨いていく}$
$\huge{ことだと思います}$
はじめに
pandasのDataFrameに複数行の値をインプットにして新しい列の値を作ることをPythonで楽しみます。
なおかつElixirでも同じことを楽しんでみます。
例題
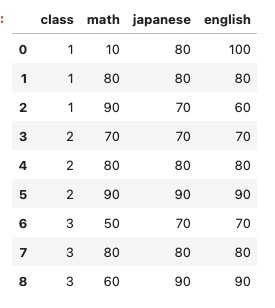
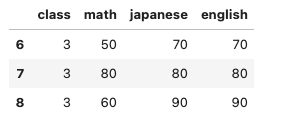
こういうデータがあったとします。
mark列を追加します。
- math、japanese、englishの得点が60点以上の場合の値は、
passとします - そうではない場合の値は、
failとします
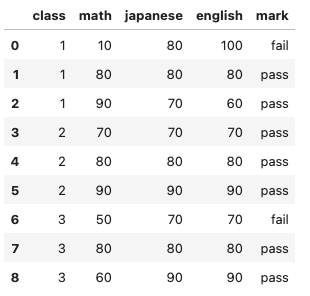
つまりこんな感じのDataFrameを得たいわけです。
実行環境
Jupyter Docker Stacksを使います。
こんな感じで使います。READMEの通りです。
docker run -it --rm -p 10000:8888 -v "${PWD}":/home/jovyan/work quay.io/jupyter/datascience-notebook:2024-02-13
pandasが同梱されているイメージです。
pandasのバージョンは、2.2.0を使いました。
結論
applyを使うとよさそうですね。
import pandas as pd
df = pd.DataFrame({
'class': [1, 1, 1, 2, 2, 2, 3, 3, 3],
'math': [10, 80, 90, 70, 80, 90, 50, 80, 60],
'japanese': [80, 80, 70, 70, 80, 90, 70, 80, 90],
'english': [100, 80, 60, 70, 80, 90, 70, 80, 90],
})
def new_column(row):
if row.math >= 60 and row.japanese >= 60 and row.english >= 60:
return 'pass'
else:
return 'fail'
df['mark'] = df.apply(new_column, axis = 1)
簡単ですね。
applyを知らずに困ったこと
この手前でこの記事は終わってもよいわけですが、pandas初心者の私が困ってしまった話を書きます。
classを3クラスだけに絞ることします。
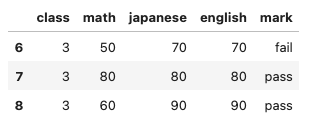
こんな感じのDataFrameが得られればOKです。
まずはapplyを使った例です。
df_class3 = df[df['class'] == 3]
df_class3.loc[:, ['mark']] = df_class3.apply(new_column, axis = 1)
applyを知らずに……
applyを知らずに書いたコードがこんな感じです。
l = []
for row in df_class3.itertuples():
print(row)
l.append('pass' if row.math >= 60 and row.japanese >= 60 and row.english >= 60 else 'fail')
df_marks_dummy = pd.DataFrame([l], index = ['mark']).T
T(転置)を使ってがんばって書いています。
df_class3.shape
# => (3, 4)
df_marks_dummy.shape
# => (3, 1)
ともに3行のDataFrameどうしだからぴったりくっつけられるだろう!
pd.concat([df_class3, df_marks_dummy], axis = 1)
おっと……、へんてこりんなデータが得られました。pandas.concatをaxis = 1で使ったら、行が増えたあー、ぎゃー![]()
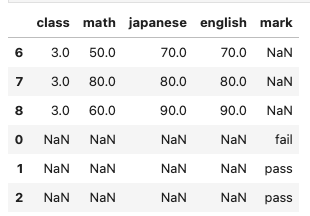
知っている方からするとこの結果が得られるのは当たり前のことなのでしょうね。
Indexがずれているわけですね。
applyを使えば悩まずに済んだのでしょうが、こういう思った通りにならないときに、アレコレ試してみることで理解が深まることもあります。
ちなみにdf_marks_dummy = pd.DataFrame([l], index = ['mark'], columns = df_class3.index).Tと無理やり、Indexを指定しておけば辻褄はあいます。Tで転置しているので、columnsに与えています。
とにかくapplyを使えば悩むことはありません。
ちなみに初見でdf[df['class'] == 3]が理解できなかった
ちなみにはじめてdf[df['class'] == 3]を見たとき私は、なんだかちっともわかりませんでした。
ちょっとずつ分割してみると理解しやすいです。一番内側のdf['class'] == 3だけ実行してみます。
df['class'] == 3
0 False
1 False
2 False
3 False
4 False
5 False
6 True
7 True
8 True
Name: class, dtype: bool
IndexとBool値のpandas.core.series.Seriesです。
df[df['class'] == 3]
こう書くと、Trueのところの行が取り出せるわけですね。
Elixirでは
Elixirで同じことをやってみます。
Livebookを使います。
こちらもREADMEに書いてあるDockerコンテナで動かす方法で試します。
READMEの通りです。
docker run -p 8080:8080 -p 8081:8081 --pull always ghcr.io/livebook-dev/livebook
Elixirでは、explorerがpandasに相当します。
Mix.install([
:explorer
])
require Explorer.DataFrame, as: DF
df = DF.new(%{
class: [1, 1, 1, 2, 2, 2, 3, 3, 3],
math: [10, 80, 90, 70, 80, 90, 50, 80, 60],
japanese: [80, 80, 70, 70, 80, 90, 70, 80, 90],
english: [100, 80, 60, 70, 80, 90, 70, 80, 90]
})
df_class3 = DF.filter(df, class == 3)
df_class3_with_mark = DF.mutate(df_class3, mark:
cond do
math >= 60 and japanese >= 60 and english >= 60 -> "pass"
true -> "fail"
end
)
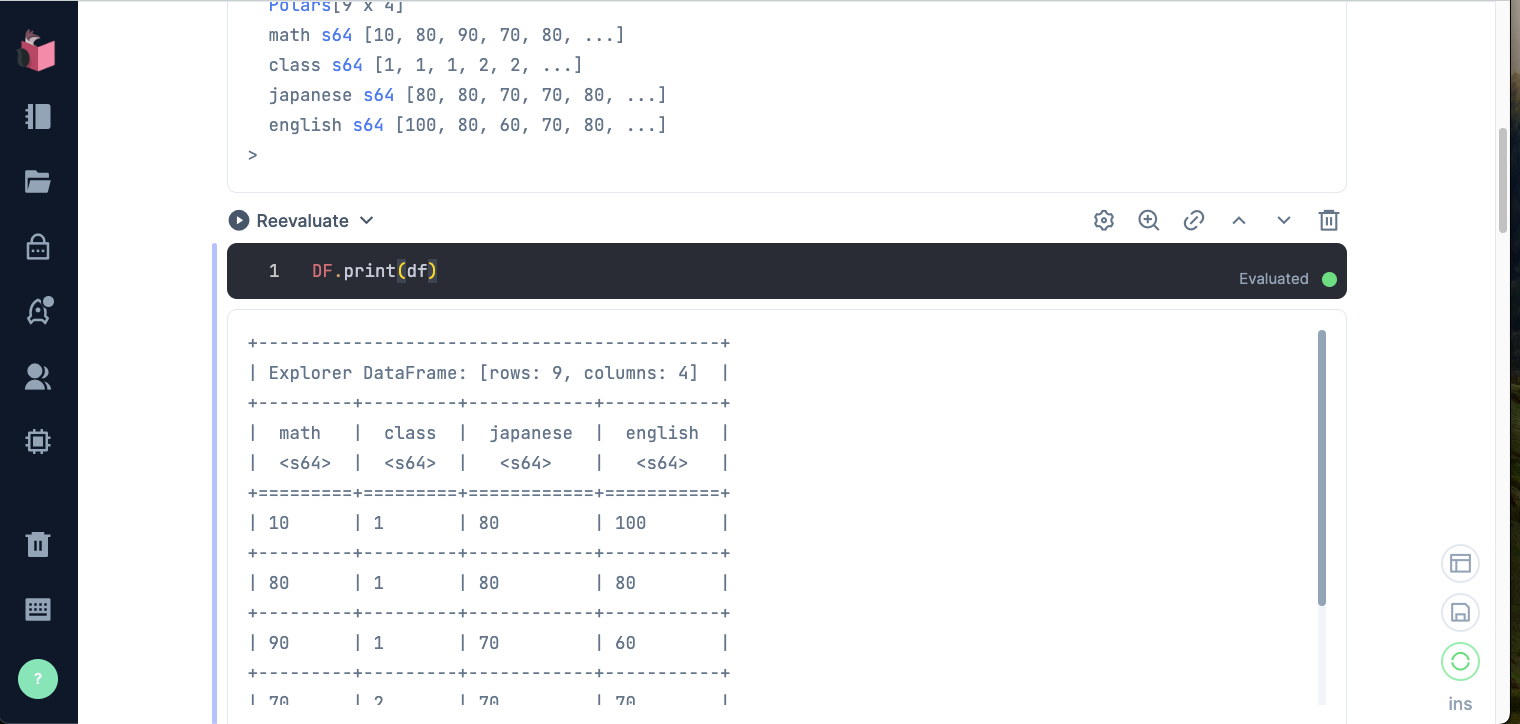
DF.print(df_class3_with_mark)
実行結果です。
+-----------------------------------------------+
| Explorer DataFrame: [rows: 3, columns: 5] |
+-------+-------+----------+---------+----------+
| math | class | japanese | english | mark |
| <s64> | <s64> | <s64> | <s64> | <string> |
+=======+=======+==========+=========+==========+
| 50 | 3 | 70 | 70 | fail |
+-------+-------+----------+---------+----------+
| 80 | 3 | 80 | 80 | pass |
+-------+-------+----------+---------+----------+
| 60 | 3 | 90 | 90 | pass |
+-------+-------+----------+---------+----------+
やったね![]()
![]()
![]()
pandasのDataFrameで理解を深めたあとでしたのですんなり書けました。
慣れの問題かもしれませんが、私はElixirのほうが書きやすい、読みやすい、止まらないです。
人それぞれ、人生いろいろでしょう。
さいごに
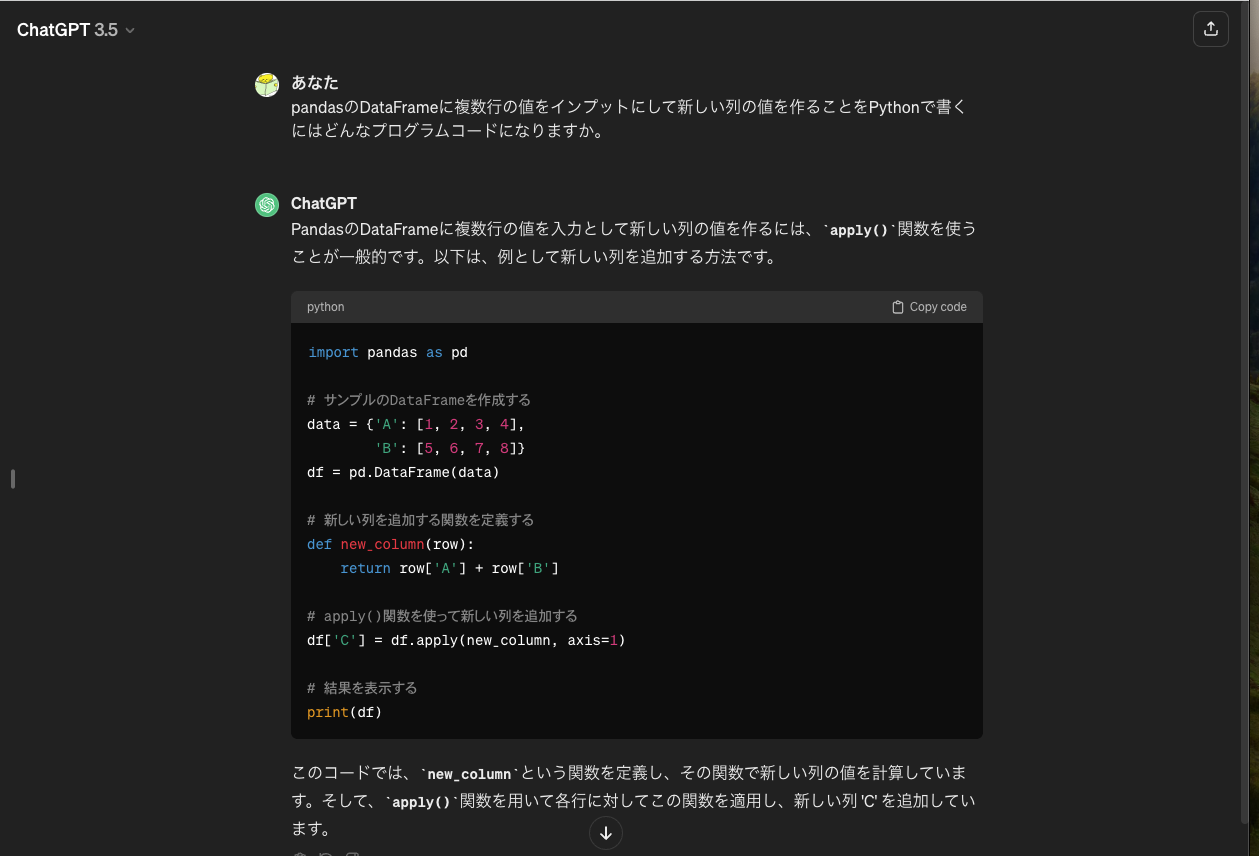
ChatGPTに聞いてみたら、applyを勧めてくれました。
まわり道かもしれませんが、あれこれ試行錯誤したほうが私は理解が深まるので無駄ではなかったとおもいます。
「pandas.concatしたら、行数が増えた。困った」みたいな方は私と同じようにいらっしゃるとおもうので、その方のお役にきっと立つだろうということで記録を残しておきます。
$\huge{元氣ですかーーーーッ!!!}$
$\huge{元氣があればなんでもできる!}$
$\huge{1、2、3 ぁっダァー!}$