データサイエンスや統計検定2級で必ず登場するキーワードを、レーシングシミュレータの実データを使って解説します。1記事1テーマで完結しています。
こんな人に役立ちます
- 長さが違う複数の時系列データを比較したい
- 基準となる1本に対して「残りがどれだけ似ているか」を定量化したい
- 距離軸アライメントやDTWを実データで動かしてみたい
問い:長さが違う時系列、どうやって比較する?
「100本の時系列データがある。基準となる1本に対して、残り99本がそれぞれどれだけ似ているかを定量化したい」
こういった問題はスポーツ分析・センサーデータ・音声認識など多くの場面で登場します。今回はレーシングシミュレータ GT7(グランツーリスモ7)のテレメトリデータを使って実装します。データは富士スピードウェイ1コーナーの速度プロファイル(速度の変化パターン)100ラップ分です。
レーシングシミュレータやテレメトリデータに馴染みのない方は、レーシングシミュレータとは? と どんなデータを記録しているのか を先にご覧ください。
課題はシンプルですが、1つ厄介な点があります。 データが時間ベースで記録されているため、ラップごとに時系列の長さが異なります。
使うのは2つの手法です。
- 距離軸アライメント:時間軸を距離軸に変換して長さを揃える(標準的なアプローチ)
- DTW(Dynamic Time Warping):長さが違う時系列の「パターンの類似度」を数値化する
Step 1:距離軸アライメント(標準的な手法)
なぜ距離軸か
テレメトリデータは60fps(1秒間に60回)の時間ベースで記録されています。ベストラップは5,921フレーム、平均的なラップは6,032フレームと長さが異なります。時間軸のままでは、コーナーの位置がズレて比較にならないのです。
プロの現場(MoTeCなどの解析ソフト)では「距離軸」にリサンプリングして合わせるのが標準です。pos_x, pos_y, pos_z から累積距離を計算すれば、コース上の同じ位置で速度を比較できます。
実装
import pandas as pd
import numpy as np
import glob, os
import matplotlib.pyplot as plt
DATA_DIR = "/path/to/TelemetryData"
# 1コーナー区間の定義(スタートラインからの距離)
T1_START_M = 530 # ブレーキング開始の手前
T1_END_M = 820 # 立ち上がり完了後
def load_t1_speed(filepath):
df = pd.read_csv(filepath)
# 累積距離を計算
dx = df['pos_x'].diff().fillna(0)
dy = df['pos_y'].diff().fillna(0)
dz = df['pos_z'].diff().fillna(0)
df['dist'] = np.sqrt(dx**2 + dy**2 + dz**2).cumsum()
# ※走行ライン(自車の軌跡)から累積距離を計算しているため、ラインの違いで数メートルの誤差が生じます
# 1コーナー区間を抽出
seg = df[(df['dist'] >= T1_START_M) & (df['dist'] <= T1_END_M)]
# 1mごとの距離グリッドに補間(サンプリング間隔が微妙に異なる複数ラップを同じ物差しに揃えるため)
dist_grid = np.arange(T1_START_M, T1_END_M, 1.0)
speed = np.interp(dist_grid, seg['dist'].values, seg['speed_kmh'].values)
return dist_grid, speed
# ベストラップ
best_file = "260415_220822_Live_Fuji_Supra18_RM_Dry_L07_1m38s676.csv"
dist_grid, best_speed = load_t1_speed(f"{DATA_DIR}/{best_file}")
# 全ラップを重ねて可視化
files = sorted(glob.glob(f"{DATA_DIR}/*Supra18_RM_Dry*.csv"))
dist_rel = dist_grid - T1_START_M # 区間先頭からの距離に変換
fig, ax = plt.subplots(figsize=(12, 5))
for f in files:
if os.path.basename(f) == best_file:
continue
_, spd = load_t1_speed(f)
ax.plot(dist_rel, spd, color='gray', alpha=0.15, linewidth=0.8)
ax.plot(dist_rel, best_speed, color='#2196F3', linewidth=2.5, label='Best lap (1m38s676)', zorder=5)
ax.set_xlabel('Distance from T1 entry (m)')
ax.set_ylabel('Speed (km/h)')
ax.set_title('Turn 1 speed profiles — 100 laps (distance-aligned)')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('t1_all_laps.png', dpi=120)
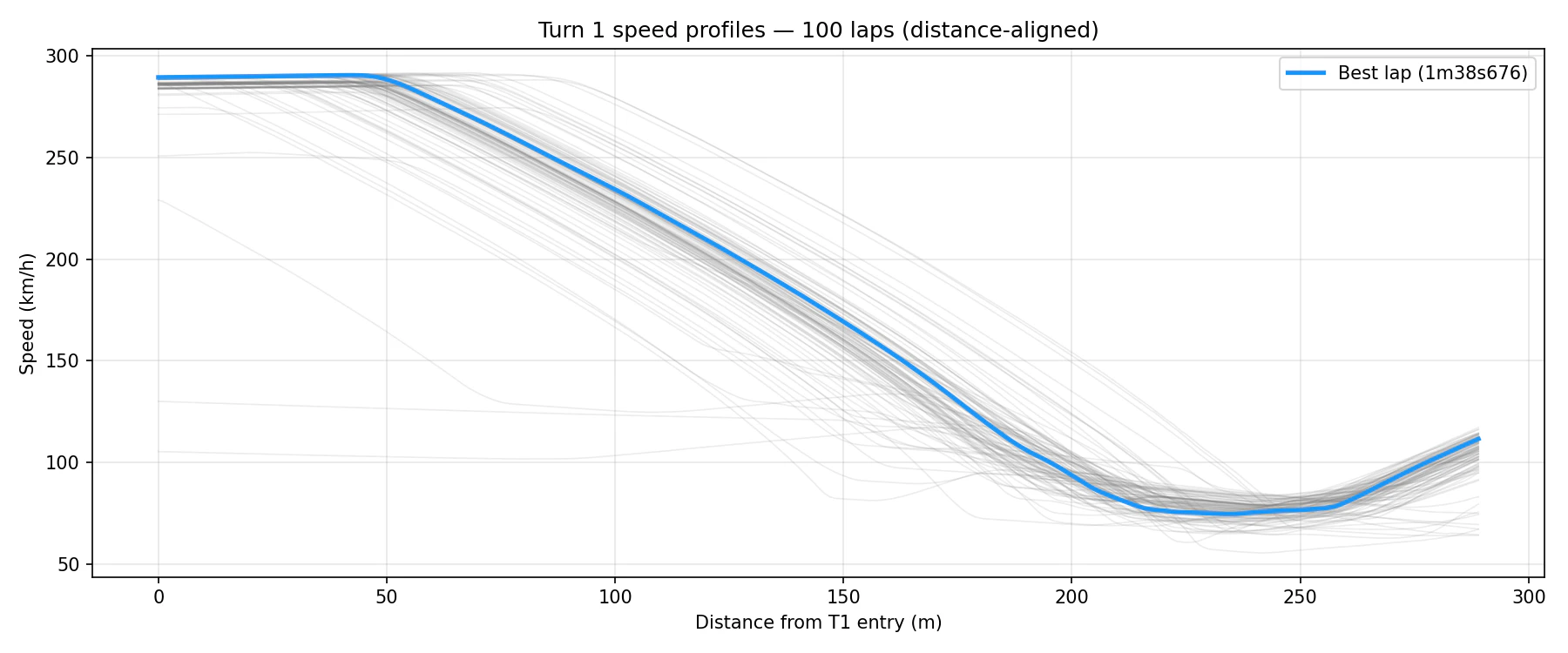
距離軸で揃えると、コーナー入口(0m付近)・ボトム(約230m付近)・立ち上がりのどの位置でバラつきが大きいかが一目でわかります。ベストラップが常に上側にいるわけではなく、ブレーキング中盤あたりで大きく分かれています。
Note: 距離軸での比較がプロの標準手法です。次のStepで使うDTWは「似ているか・違うか」を数値化するための別の道具であり、用途が異なります。
Step 2:DTWで「似ているラップ」を定量化する
DTWとは
DTW(Dynamic Time Warping) は、2つの時系列の「形の類似度」を計算する手法です。「速度変化のパターン全体がどれだけ似ているか」を1つの数値で表します。
- 値が小さい → パターンが似ている(同じタイミング・強さでブレーキングしている)
- 値が大きい → パターンが違う(別の走り方をしている)
Step 1で距離軸に揃えた後は、RMSEや相関係数でも同じ目的を達成できます。 DTWの本来の強みは「長さが違う時系列の伸縮を吸収する」点にあり、時間軸データのまま比較する場面で真価を発揮します。今回は距離軸リサンプリング後のデータに適用していますが、DTWは局所的なズレ(ブレーキ開始タイミングのわずかな違いなど)を吸収しながら類似度を評価するため、単純なRMSEよりも「操作パターン」の違いに敏感です。同一車・同一コースのためスケールが揃っており、あえて正規化はしていません。
100ラップ全部をベストと比較する
from fastdtw import fastdtw
dist_grid = np.arange(T1_START_M, T1_END_M, 1.0)
results = []
for f in files:
if os.path.basename(f) == best_file:
continue
_, spd = load_t1_speed(f)
# DTW距離を計算(ベストとの類似度)
dtw_dist, _ = fastdtw(best_speed.tolist(), spd.tolist(), dist=lambda a, b: abs(a - b))
results.append({
'file': os.path.basename(f),
'dtw_dist': dtw_dist,
'speed': spd
})
results.sort(key=lambda x: x['dtw_dist'])
print("ベストに最も近い Top3:")
for r in results[:3]:
print(f" DTW={r['dtw_dist']:8.1f} {r['file']}")
print("\nベストから最も遠い Top3:")
for r in results[-3:]:
print(f" DTW={r['dtw_dist']:8.1f} {r['file']}")
実行結果:
ベストに最も近い Top3:
DTW= 54.4 260415_221001_Live_Fuji_Supra18_RM_Dry_L08_2m03s555.csv
DTW= 80.5 260407_232633_Live_Fuji_Supra18_RM_Dry_L04_1m40s782.csv
DTW= 83.0 260418_130410_Live_Fuji_Supra18_RM_Dry_L08_1m49s868.csv
ベストから最も遠い Top3:
DTW= 5197.0 260409_220737_Live_Fuji_Supra18_RM_Dry_L02_1m42s545.csv
DTW= 19581.9 260412_221403_Live_Fuji_Supra18_RM_Dry_L10_1m46s979.csv
DTW= 23489.0 260412_222234_Live_Fuji_Supra18_RM_Dry_L02_1m50s784.csv
可視化
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 左:ベスト・最も似たラップ・最も違うラップを重ねる
for r in results:
axes[0].plot(dist_rel, r['speed'], color='gray', alpha=0.1, linewidth=0.8)
axes[0].plot(dist_rel, best_speed, color='#2196F3', linewidth=2.5,
label=f'Best (1m38s676)', zorder=5)
axes[0].plot(dist_rel, results[0]['speed'], color='#4CAF50', linewidth=2,
label=f'Most similar DTW={results[0]["dtw_dist"]:.0f}', zorder=4)
axes[0].plot(dist_rel, results[-1]['speed'], color='#FF5722', linewidth=2,
label=f'Most different DTW={results[-1]["dtw_dist"]:.0f}', zorder=4)
axes[0].set_xlabel('Distance from T1 entry (m)')
axes[0].set_ylabel('Speed (km/h)')
axes[0].set_title('Turn 1: Best vs Most similar / Most different')
axes[0].legend(fontsize=8)
axes[0].grid(True, alpha=0.3)
# 右:DTW距離の分布
dtw_vals = [r['dtw_dist'] for r in results]
axes[1].hist(dtw_vals, bins=20, color='#2196F3', alpha=0.7, edgecolor='white')
axes[1].axvline(results[0]['dtw_dist'], color='#4CAF50', linewidth=2,
label=f'Most similar: {results[0]["dtw_dist"]:.0f}')
axes[1].axvline(results[-1]['dtw_dist'], color='#FF5722', linewidth=2,
label=f'Most different: {results[-1]["dtw_dist"]:.0f}')
axes[1].set_xlabel('DTW distance from best lap')
axes[1].set_ylabel('Count')
axes[1].set_title('Distribution of T1 similarity (99 laps)')
axes[1].legend(fontsize=8)
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('t1_dtw.png', dpi=120)

結果が語ること
DTW距離が示すもの
DTW距離は「1コーナーのブレーキングパターンがベストにどれだけ近いか」を表しています。
- DTW距離が小さい:ブレーキングの動作パターンがベストに近い。具体的には、ブレーキ開始位置・減速の強さ・立ち上がりのタイミングがベストとほぼ一致していることを意味します
- DTW距離が極端に大きい(DTW=23,489):スピン・大きなブレーキミス・ライン逸脱など、通常の走行と異なるイベントが含まれている可能性が高い
DTW距離はデータの長さ・スケール・サンプリング密度によって値が変わるため、絶対値に意味はなく、同一データセット内での相対評価に使います。今回のデータでは54〜23,000という広い分布になりました。大多数は100〜2,000の範囲に収まっており、少数の外れ値ラップだけが桁違いの値になっています。
2つの手法の使い分け
| 手法 | 答えられる問い |
|---|---|
| 距離軸アライメント | 時系列のどの区間で値に差があるか |
| DTW | 時系列全体のパターンがどれだけ似ているか |
「どこで差がついたか」を知りたければ距離軸アライメント。「100本の中でどれが最も似ているか」を定量化したければDTW。目的に応じて使い分けます。
まとめ
- 距離軸アライメントで、1コーナーの100ラップを同じ軸で比較しました
- DTWで99ラップとベストの「ブレーキングパターンの類似度」を定量化しました
- DTW距離が極端に高いラップ(DTW=23489)はコーナーでのミスが疑われます
今回はレーシングデータを使いましたが、同じロジックは心拍データや歩行パターンの個人差分析・株価の類似チャート探索など、「長さが違う時系列の比較」が必要な場面であれば分野を問わず適用できます。
次のステップとして、各ラップのDTW距離をそのまま特徴量として使い、100ラップをクラスタリングすると「ブレーキングスタイルの傾向」を分類できます。また、DTWのパス(対応表)を深掘りすれば「どのタイミングで操作がズレたか」も解析可能です。
最後まで読んでいただきありがとうございました。
参考
- データ:GT7テレメトリ(富士スピードウェイ、Supra18、RM、Dry、100ラップ)
- ライブラリ:fastdtw
- この記事の概要は後日noteで解説予定です