追記 2025年9月11日)
このときはローカルでイメージを作ってそれをGoogle CloudのレジストリへPUSHするのに苦労してたりしてますが、最近サービスを構築してみようと久々触ってみると、Render等と同じようにGithubのレジストリから直接デプロイでき、とてもカンタンでした。ただし今回の場合はSQLやCloudStrageを繋いだりするので、そこの設定は変わってないんじゃないかな。最近やったのはmongoDB AtlasをDBとして、環境変数として証明書ファイルをアサインするのはこの投稿と同じようにあちこち必要な設定する必要がありました。
さて今回は、これまでherokuやpythonanywhereで動かしていたDjangoで作ったサービスをGoogle Cloud Platformで動かそうとしたときの苦労話を書いてみます。
世の中、Cloud RunやCloud SQL に関する情報は公式ドキュメントを始めとしてたくさん公開されているけれど、Djangoとの組み合わせなどというピンポイントの情報はなかなか見つからない。Qiitaで検索してもピッタリの情報がない。
ならば私が(ヨロヨロしながらもなんとか)動いたやり方を広く世に知らしめようというのが今回投稿した大きな目的というわけです。
今回書いたこと
今回のサービスはPython3.9+Django3.2.4で書いたイメージをCloud Runで動かしつつ、データベースはCloud SQL for postgreSQLを利用しようというものです。
そんな環境で今回は主に次の3つについて書いてますので、まずここを読んで自分の目的とする内容かどうか確認してみてください。
1. Cloud Run上で動くDjangoからCloud SQLを接続する
情報が少なく、こいつが一番の難関でした。
2. DjangoからCloud Strageにあるstaticファイルを参照する
こいつも情報が少ない。
3. ローカルで作成したイメージをARTIFACT REGISTRYにPushする
何度も書くけど、こいつも素人にわかりやすい情報がほぼない。
そんなGoogle Cloudを初めて使ってみたいという初心者にわかりやすい情報がないならば自分の知ってることを投稿しようってのが今回の強い動機でした。
あらかじめ注意事項を書いときます
今回はGoogle Cloudの基礎知識や利用方法などは書いてません。それをある程度基本はわかってることが前提としています。(などとエラそうに書いてるけど、私もよく知ってるわけじゃない)
Google Cloudについては、Qiitaを始め様々な方々が優れた解説記事を書かれているので、そちらを参考にしていただき、それ以外の今回の組み合わせの環境でなにかやろうとして煮詰まったときにはこの投稿を参考にして貰えれたと思います。
また今回の投稿内容にあるCloud Run上でサービスを実行させるためには、Dockerの知識が必須です。Dockerってよくわからんと心配の皆さんは、まず自分の環境(MacやWindowsならば)にDocker Desktopをインストールして、ローカルのデーターベース(sqlite3とか)で動くイメージを作ってから取り掛かってください。Dockerが全くわからない人はCloud Runは扱えませんと断言しておきます。
そんな私の場合、「動くことこが大切」が前提の個人的な趣味でやってることなので、細かい部分で「それは違う」という内容があってもそこは大目に見ていただきたい。
ただしこれは明らかに間違っているとか、シロウトでも理解できるもっと簡単な方法があるよとかいう内容のものがあれば、教えていただければ大変うれしく思います。
では、はじめに
まずやり始めてはみたものの、基本として「公式ドキュメントを読め」という掟を守らずに、ダラダラとググってみたりChatGPTってみたり、Bardってみたりしたら色んな情報が画面上に乱舞するだけで、かえって分からなくなってしまいました。
そんなわけで、Djangoを使ってPythonで書いたWEBサービスをCloud Runで動かしつつ、データベースはCloud SQL for progresSQLで動かすまでに苦労して探し当てたお宝情報を書き残して、これからやってみようとしている初心者が私みたいな苦労をしないことを望みます。
やってみて分かったのは、最初にCloud Run+Cloud SQLでサービスを構築したい場合には、公式のチュートリアル「Cloud SQL for PostgreSQL から Cloud Run にアプリをデプロイする」を一度実際にやってみるべきで、そいつを強くアドバイスしたいと思います。そいつでエラーなくサービスが動いたら、そこで設定したデータベースとかユーザとかパスワードをDATABASE記述に設定してサービス作成すればうまくいくはずですよ。しらんけど。
それではいよいよ Cloud Runにサービス登録するDjangoからCloud SQLへ接続するためのポイントを書いてみますよ
今回は特にCloud SQLへの接続に苦労しました。いろいろググってみたりChatGPTやBardに聞いてみても、中途半端な情報しか帰ってこない。
最近とみにAIだのLLMだのと持て囃されていますが、ヤツラって決して万能ではなく適切な質問をしなければほしい回答を示してくれず、曖昧な質問では曖昧な回答しか返ってきません。信用しすぎるのは禁物で、今回の一連の試行錯誤で思い知りました。
とか書いてみたあと、いきなりCloud Runで動くDjangoからCloud SQL forpostgreSQLと接続して利用するためのsetting.pyの記述を書いときます。(MySQLでもほぼ同じでつながるはず)
これを正しく記述しておかないと、Cloud Runでイメージからサービスを作成しようとした場合、途中で「データベースが見つからない」だの「接続でタイムアウト発生」などとエラーが発生して作成できません。
やっと探し当てて動いてくれたDATABASES記述。メモっとけ
こいつはpostgreSQL用ですが、MySQLでもSQL Serverでもほぼ同じだと思いますので、細かい部分は自分で調べてね。
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'インスタンスで作成したデータベース名',
'HOST' : '/cloudsql/対象のデータベースインスタンス概要で表示される「接続」をコピーしたやつを貼り付ける',
'PORT': '5432',
'USER': 'インスタンスで登録したユーザ名',
'PASSWORD': 'インスタンスのパスワード',
}
}
それぞれどう設定していて最初はまったくどこの情報を記述すればいいのかよく分からなかったんですが、その中でいちばん苦労したのはHOSTの指定です。(公式ドキュメントも英語と日本語が混ざっているし、Bardは嘘の情報を教えてくれるし)
そんななか、ポイントはHOST記述の頭に"/cloudsql/"を付けて、その後に接続したデータベースインスタンスの概要画面のなかの「接続名」の文字列をコピーして貼り付けることです。
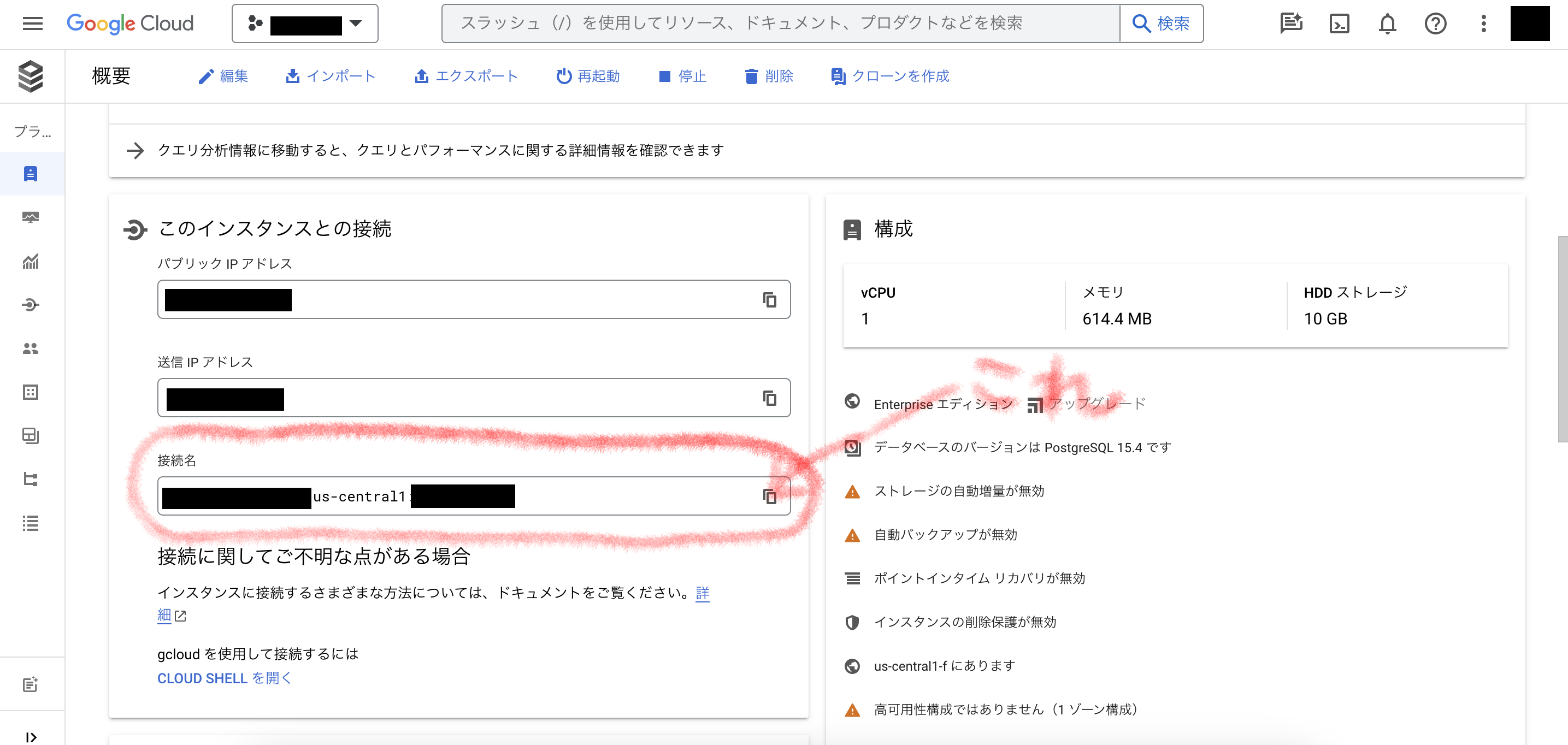
上の画面のまるく赤で囲った部分がHOSTに記述する部分ですよ。
ドキュメントを読んでもこの辺りをきちんと書かれているものはないんじゃないか。あるいは私が読み落としてたのかもしれんけど、いつになっても「アドレスが解決できないから接続できない」とか「こんな名前のデータベース無いんじゃない?」とか「接続しようとしたけどタイムアウトになっちゃった」とかエラーばかりが表示されて、私はこれで長いこと悩んでました。暗く悲しい気持ちを抱え、時間ばかりが過ぎていった日々でした。
Cloud SQL側の注意点
プロジェクトに登録されているユーザにcloud runとcloud sqlのアクセス権(実行権、登録権、参照権など)を付与することと合わせてここポイントです。
データベースインスタンスに関するアクセス権とかいろいろとわからないならば、チュートリアルとして提供されている「Cloud SQL for PostgreSQL から Cloud Run にアプリをデプロイする」にそって実際にやってみるのが一番理解しやすいかも。
そこで「こう指定しなさいよ」って言われている内容をそのまま新しいインスタンスを作るときにやってみること。そしてエラーなくチュートリアルのサービスが動いたら、そこで設定したデータベースとかユーザとかパスワードをDATABASE記述に設定してデプロイすればうまくいくと思います。私がそうでした。
Cloud Runサービス作成の注意点
サービス作成時に「コンテナ、ボリューム、ネットワーキング、セキュリティ」の必要項目の設定が必要ですが、このときの監視ポートのデフォルト値が"8080"となっています。Djangoの場合、何も指定していないとポート番号は"8000"だったと思います。そのため、"8080"以外のポートを指定している場合には、ここの変更も忘れずに。
よくわからんけど私の場合、DockerfileのCMD記述にポート番号を指定してます。してないと動かない気がして。動くかもしれんけど、おまじないです。
FROM python:3.9-alpine
COPY . .
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
CMD ["python", "manage.py","runserver","0.0.0.0:8000"]
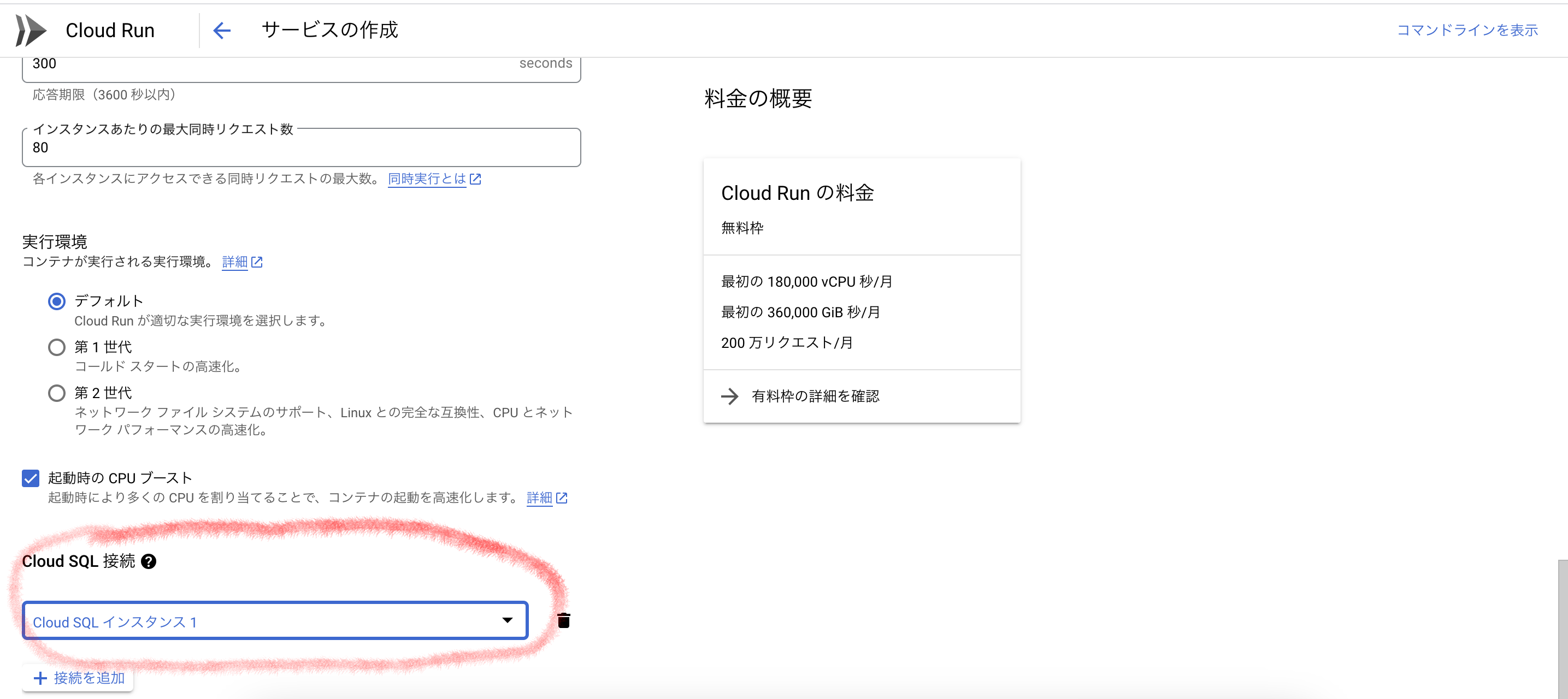
そのport番号指定は以下の画面で指定すべし。忘れるな。

接続先の自分で作ったSQLインスタンスの指定も忘れずに。
Django特有の問題解決方法(邪道)
サービス作成がうまくいっても、接続した先のデータベースにサービスで必要なテーブルがないので、そのままサービスは立ち上がるものの、データベースを参照しようとするとエラーが発生します。(あたりまえ)
DjangoではいちいちSQLを叩いたりしなくてもマイグレーションを実行すればmodels.pyで設定しているテーブルを自動的に作成してくれるのは御存知の通り。(合わせてDjango管理用テーブルも作られます)
なので利用に当たっては次のコマンドを実行させる必要があります。
models.pyで定義されているテーブル情報をデータベースへ反映させるための管理ファイルを作成するコマンド
python manage.py makemigrations
makemigrationsで作成された情報を実際にデータベースへ反映させるコマンド
python manage.py migrate
ところがそんな便利な機能もCloud Runは外部から簡単にコマンド入力ができないため、思わぬ障害となりました。Dockerならば実行できるので「できるだろう」と高を括ってたら、Cloud Runでは(いろいろとゴニュゴニョすればできるっぽいけど)それができないらしい。そこでなんとかならんかとない知恵を絞ってひねり出したのが、Cloud Runが提供するジョブ機能を使うことでした。
具体的には、マイグレーション用のイメージを作って、そいつをジョブ機能を使ってバッチ的に実行するという方法です。
イメージ作りは簡単で、ほんちゃんのイメージ作成用DockerfileのCMD部分(djangoを起動するコマンド)のを記述をマイグレーションするように書き換えるだけです。
しかし、ここでまた一つ工夫が必要なんですが、Dockerfileで実行できるCMDはひとつだけなので(実際にはこれまた工夫すればできるっぽいんですが)、makemigrationsとmigrateを一連で流す事ができない。
そこでまたひねり出したのは、ローカル環境のDB(dbsqlite3など)でいちどmakemigrationsを実行しておいて、そこで作られたデータベース作成用管理ファイルごとmigrateを実行するイメージとしてbuildし、それをジョブ機能で実行するという方法。そうすれば、あら不思議(意図通りに) ちゃんとテーブルが作成されました。
migratsionを実行したい時に連続して2つのコマンド(makemigrationsとmigrate)を実行する方法を見つけましたので上については下の記述のとおり修正です。
記述は簡単
FROM python:3.9-alpine
COPY . .
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
CMD ["python","manage.py","makemigrations","&&","python","manage.py","migrate"]
問題は次々に発見される
と喜んでいたら、またまた問題発生。
Djangoでは管理用ユーザ作成は対話型で作成するのが一般的です。(初心者向けの情報ではそれしか書いてないし)
しかし先に書いた通りCloud Runのコンテナに入ってコマンド入力できないうえ、対話型ならば余計無理。
さてどうするかとまた色々と考えてググってみたりしたら、--noinputとオプション記述をすればバッチ的に管理ユーザ作成が可能だということがわかりました。(注:Django 3.0以降の機能らしいです)
具体的には以下をDockerfileに記述して、migrateと同じようにジョブ機能用のイメージを作ればオーケーです。
FROM python:3.9-alpine
COPY . .
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
CMD ["python","manage.py","createsuperuser","--noinput","--username=admin","--email=admin@email.com"]
ググったときには--noinputならばユーザ名やemailなどの指定は不要で、処理完了後にパスワードが画面に表示されると書かれていたけれどローカルで実際に試してみたら3.0以降でもユーザ名とemail指定は必須でしたので上のコマンドに記述してます。
さて、ここで気になるのがパスワードをどするのかですが、これは外部変数としてジョブ機能作成時に指定してあげればオーケーでした。
パスワードを与える外部変数名はこちら
DJANGO_SUPERUSER_PASSWORD
こいつをジョブ機能作成時に変数のキーとして値のパスワードと一緒に登録すれば反映されます。

とうことで、Cloud SQLとの接続は出来ましたが、それ以外にもDjangoではめんどくさい設定があります。
それは静的ファイル(staticファイル)をどうやって配信するかってことですね。
staticファイルをGoogle Cloud Strageに保存したい場合の設定方法
Djangoは御存知の通りSetting.pyでDEBUG=False(本番モード)にしていると本番環境として動き、そのときstaticファイルはDEBUG=True(デバッグモード)とは別の場所を参照しするため、HTMLにかっこよく散りばめていた画像ファイルが表示されません。
通常はnginxなどのいわゆるWEBサーバーで配信するのが一般的のようですが、Cloud Runはそういう構造ではないので、Cloud Run利用時のstaticファイルはCloud Storageに保存し、Djangoから参照させることにしました。
今回の目論見についても、その設定を色々調べても古い情報が出てきたりで、これまたよくわからんわけで、そんななかで調べた結果、Setting.pyに本番環境として以下の記述をすればstaticファイルを参照(配信)できるようになりましたので、合わせて書いときますね。
デフォルトのストレージをGoogle Cloud Storageに設定します。
GCPのプロジェクト名を設定
GS_PROJECT_ID = '自分のプロジェクトID'
自分のプロジェクトIDは、ダッシュボードの左側、プロジェクト情報に表示されるIDです。

Cloud Strageのバケット名を指定
GS_BUCKET_NAME = 'プロジェクトIDで作成したバケット名'
GCP認証情報ファイルの保存場所を指定
あらかじめプロジェクトの鍵情報を作成しダウンロードした鍵ファイルのPATHを設定。この場合はos.path.join(BASE_DIRで対象資源があるフォルダのルートに置いている。
GS_CREDENTIALS = service_account.Credentials.from_service_account_file(
os.path.join(BASE_DIR, 'Cloud Strageにアクセスするための制御ファイル.json'),
)
Google Cloud Storageの設定
DEFAULT_FILE_STORAGE = 'storages.backends.gcloud.GoogleCloudStorage'
staticファイルでGoogle Cloud Strageを使うことを宣言
STATICFILES_STORAGE = 'storages.backends.gcloud.GoogleCloudStorage'
STATIC_ROOTの設定(Google Cloud StrageバケットのPathを指定
名前の最初は"gs://"です。
STATIC_ROOT = 'gs://上のGS_BUCKET_NAMEと同じ名前'
追記)MEDIA_ROOTの設定(Google Cloud StrageバケットのPathを指定
名前の最初は"gs://"で、STATIC_ROOTと同じパスにするとDjangoでエラーが発生しますので注意が必要。
MEDIA_ROOTは設定しなくてもSTATIC_ROOTのパスの下の/media/フォルダが保存先になりますが、それではちょっと気持ち悪い場合には、MEDIA_ROOT指定しても動きます。ただし前に書いた通りSTATIC_ROOTと同じパスを指定するとエラーになります。
これであなたもCloud Storageを使えるぞ。
Cloud SQLはセキュリティ担保のため、外部からの接続はいろいろと手間がかかるようですが、staticファイルはDEBUG=True,Falseに関わらずこの記述をしておけば、ローカル環境からもアクセスできて便利ですよ。
Google Cloud Strageにアクセスするためにライブラリが必要なので、今回のrequirements.txtを参考として載せときます。直接関係ないライブラリもあるけれど、どれが必要でどれが関係ないかがよくわかってない部分があるのでその点は許してね。
Django==3.2.4
gunicorn==20.1.0
django-mathfilters==1.0.0
requests==2.25.1
google-cloud-storage==1.42.2
django-cleanup==5.2.0
django-googledrive-storage==1.5.2
django-storages==1.11.1
Pillow==10.1.0
psycopg2-binary==2.9.9
各ライブラリのバージョンは適当です。
よくわからんけれど、gunicornも必要らしいということでのっけてます。ヒマな人は外して動くかどうかやってみてくださいね。
ちなみにpsycopg2だとフルサイズのPython環境じゃないとインストールに失敗するので、psycopg2-binaryを指定しています。(今回作成したイメージはpython:3.9-alpineで作成してます)
ARTIFACT REGISTRYにローカルでbuildしたイメージをpushする呪文
こいつもまた初心者泣かせの作業で、色々と情報を検索しても「Cloud Runでサービス登録するには、まずARTIFACT REGISTRYにイメージをPushする」って簡単にかかれているけれど、それだけじゃわからんよね。
なので私も散々色々なやり方を試してみたけれど、全然Push出来ない。そんななか偶然見つけた情報を祈るような気持ちで試してみたらあっさりうまくいったってわけで、その秘密を皆さんにもお教えいたしましょう。
docker build -t us-central1-docker.pkg.dev/自分のプロジェクトID/ARTIFACT REGISTRYに予め作っておいたリポジトリ名/イメージ名 .
自分のプロジェクトIDの確認は上に書いた通りです。
Docker Desktop画面を見てみると、buildしたイメージが表示されてます。
登録先のパス名(?)がそのままイメージ名になってますね。

続いてARTIFACT REGISTRYにbuildしたイメージをPushします。
docker push us-central1-docker.pkg.dev/自分のプロジェクトID/ARTIFACT REGISTRYに予め作っておいたリポジトリ名/イメージ名
さっき実行したコマンドのbuild -tをpushに変えて、最後のピリオドを消した後に実行するだけで、ARTIFACT REGISTRYにイメージがpushされますよ。
tagをつけることもできますが、上のように無しで実行すれば勝手にlatestと付きますので、ARTIFACT REGISTRYを開いてみて自分が登録していたリポジトリにちゃんとpushされているか確認してください。

さいごに
Google Cloud Platformは様々なサービスが提供されていて活用できれば非常に便利であることはわかっているけれど、機能がありすぎるかつ多様な利用方法が想定されているために、サービス間の関連やらIAM関連の相互設定など理解していないとさっぱり動きません。わたしも散々VPCネットワークなどを触ってみたりしましたが、そこら辺はチュートリアルでは特に設定の指示がないので、Cloud Run+Cloud SQL環境では必要がないのかもしれません。しらんけど。
これまで書いてきた内容を実行するには、事前にGoogle Cloud CLIをインストールするとか、そいつを使ってgcloudで認証を実行するとか、指定のプロジェクトIDを設定するとかいろいろとありますが、そちらのやり方は比較的容易に見つかるので、自分で探してやってみてください。
そんな高機能・多機能なサービスを利用するに当たり、今回の投稿内容ではIAM関連でゆるゆるな部分があるとは思いますが、まずはサンドボックス環境で動くものを作ってみるというのが大切じゃないかと。その成功体験をもってより高度なものへチャレンジしてみようという意欲をもつ人が出てくれば、その手助けが少しでも出来たとすれば、それはとても嬉しいことだと思います。
追加情報
Google Cloud SQLはインスタンスを作成しているとサービス停止中でもエリア分を課金されますので、しばらく使わないと思い削除しました。
で、ちょっと動かしてみようとおもってインスタンスを動作実績があるものと全く同じとして作成したけれども、先に動いた実績のあるサービスを実行しようとしたらエラーになりました。これってサービス登録時にその時点のSQLインスタンスの内部情報をキーに接続するみたいなので、それが変わったら接続出来ませんでした。
うまいやり方があるかもしれないけれど、だめでしたね。まあこれも知ってる方々であれば常識なんでしょうが、初心者はやってみて「あれ?」って思う点でした。
エクスポートとインポートも正常終了するけれど、うまく情報が反映されてなさっぽくて残念無念。これもなにかコツがあるんでしょうし、それはドキュメントを読んだら書いてあるでしょうが、今回はこれまで。