はじめに
研究の関係で時系列異常検知手法について調べる機会があったので、今回は時系列異常検知手法であるAnomalyTransoformerの論文について紹介させていただきます。
Anomaly Transformer
Anomaly Transformerは2022年に発表されました。Transfoemerは自然言語処理や音声処理、コンピュータビジョンなどの順序データ処理において強力な性能を示していることから、その性能を異常検知タスクにも活用したものがAnomaly Transformerになります。当時、教師なし時系列異常検知はLSTMを用いた手法が主流でしたが、Transformerを使用することで長期的な時間的依存関係を学習することができ、6つの教師なし時系列異常検出ベンチマークにおいて、最新の成果を達成しています。
参照論文:Anomaly Transformer
構成
Anomaly Transformer は、Anomaly-Attention ブロックとフィードフォワード層を交互に積み重ねて構成されます。これは従来のTransformerの構成とは異なり、Anomaly TransformerはAttention機構をAnomaly Attentionに改良しています。これにより、Anomaly Attentionでは系列関連性と事前関連性を学習し、学習された関連性の不一致に基づき異常検知が行えます。
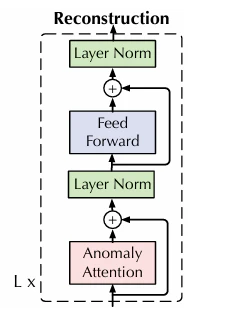
引用:Anomaly Transformer (https://arxiv.org/pdf/2110.02642)
Anomaly Attention
Anomaly Attentionでは系列関連性と事前関連性の両方を学習するために、2分岐構造となっています。
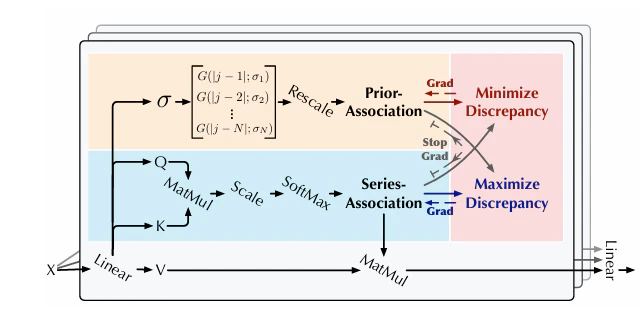
引用:Anomaly Transformer (https://arxiv.org/pdf/2110.02642)
- 系列関連性
系列関連性はAttention機構の関連性確率から求まります。
\displaylines{
Q = Xˡ⁻¹ × W_Qˡ\\
K = Xˡ⁻¹ × W_Kˡ\\
V = Xˡ⁻¹ × W_Vˡ\\
}
$$
S^{(l)} = \mathrm{Softmax}\left(\frac{QK^{\mathrm{T}}}{\sqrt{d_{\mathrm{model}}}}\right)
$$
- 事前関連性
事前関連性は相対的な時間距離に基づいて、学習可能なガウスカーネルを使用して計算されます。シーケンス内の各要素(i,j)の関連重みより求めます。
$$
\sigma = X^{(l-1)} \times W_{\sigma}^{(l)}
$$
$$
P_{ij}^{(l)} = \frac{1}{\sqrt{2\pi \sigma_i}} \times \exp\left(-\frac{(j - i)^2}{2\sigma_i^2}\right)
$$
異常度算出
Anomaly Transformerは関連性差異から異常スコアを算出します。異常はまれであるという特性から、異常点の関連性は主にその近傍に集中する傾向があります。一方、正常箇所は、近傍に限らず時系列全体と多い関連性があります。そこで、事前関連性で局所的な関連を学習し、系列関連性で大局的な関連性を学習することで2つの関連性を比較し関連性差異から異常度を求めます。関連性差異は事前関連性と系列関連性の対称的なKLダイバージェンスとして関連性の類似度が高い箇所を正常、低い箇所を異常としています。そのため、異常点ではこの AssDis 値が通常より小さくなる傾向があり、異常と正常を区別するのに有効です。
$$
\mathrm{AssDis}(P,S; X) = \frac{1}{L} \sum_{l=1}^{L} \left[ \mathrm{KL}(P_i^{(l)} \parallel S_i^{(l)}) + \mathrm{KL}(S_i^{(l)} \parallel P_i^{(l)}) \right]
$$
$$
\mathrm{AnomalyScore}(X) = \mathrm{Softmax} \big( \mathrm{-AssDis}(P,S; X) ) \odot [| X - \hat{X} |_F^2] \quad i=1,\ldots,N
\tag{6}
$$
関連性学習
Anomaly Transformerは教師なし学習モデルであるため再構成誤差に基づいてモデルの最適化を行います。この損失により、系列関連性を学習します。また、正常と異常の違いを拡大するために関連性差異を強調する損失AssDis(P, S; X)を追加し、事前関連性と系列関連性の両方を加味した学習が行えます。
- 損失関数
$$
\mathcal{L}_{\text{Total}}(\hat{X}, P, S, \lambda; X) = | X - \hat{X} |_F^2 - \lambda \cdot | \mathrm{AssDis}(P, S; X) |_1
$$
実装方法
Anomaly Transformerはgithubで公開されています。
データセットはgithubで説明されているようにgoogle cloudから指定のディレクトリにダウンロードしてください。
その後、データセットに対応した.sh拡張子のシェルスクリプトファイルを実行することで簡単に動かしてみることができます。その際、シェルスクリプトファイルファイル内の
CUDA_VISIBLE_DEVICESを自分のGPU番号に指定する必要があります。
おわり
今回は時系列異常検知手法のなかで優れた性能を達成したAnomaly Transformerについて紹介させていただきまいた。このモデルは時系列処理に優れるTransformerを異常検知タスクに活用し関連差異を求めることで、これまでの教師なし異常検知手法とは異なるアプローチで異常スコアを算出しています。
2024年にはこちらの手法をもとにDual TFと呼ばれるより優れた異常検知手法も提案されているので、いつか読んでみようと思います。