プログラミングゲームの解答コードを投稿しよう! に参加しました.
昨年のpaiza×Qiita記事投稿キャンペーンの続編ですね.
この記事では,キャンペーン対象問題の解答と簡単な解説を公開します.
言語はPythonを選択しました.
Pythonプログラムは,以下にも置いてあります.
Rank E: 街外れの戦場跡
4択問題.非常に簡単で,特に言うことはない.
Rank D:
ネオン街の裏路地
print(max(int(input()) for _ in range(int(input()))))
Pythonのリスト内包表記を使えば1行で書けます.簡単ですね.
カジノ
print(sum(i * int(input()) for i in [1, 5, 10]))
先ほどとは異なるfor文の使い方をします.こちらも難しくありません.
郊外のスラム街
print(int(input()) // 2 + 100)
割り算に/使うと数値がdouble型になるので,//を使います.
Rank C:
ネオン街のクラブ
キャンペーン対象外のため,解答が書けません.
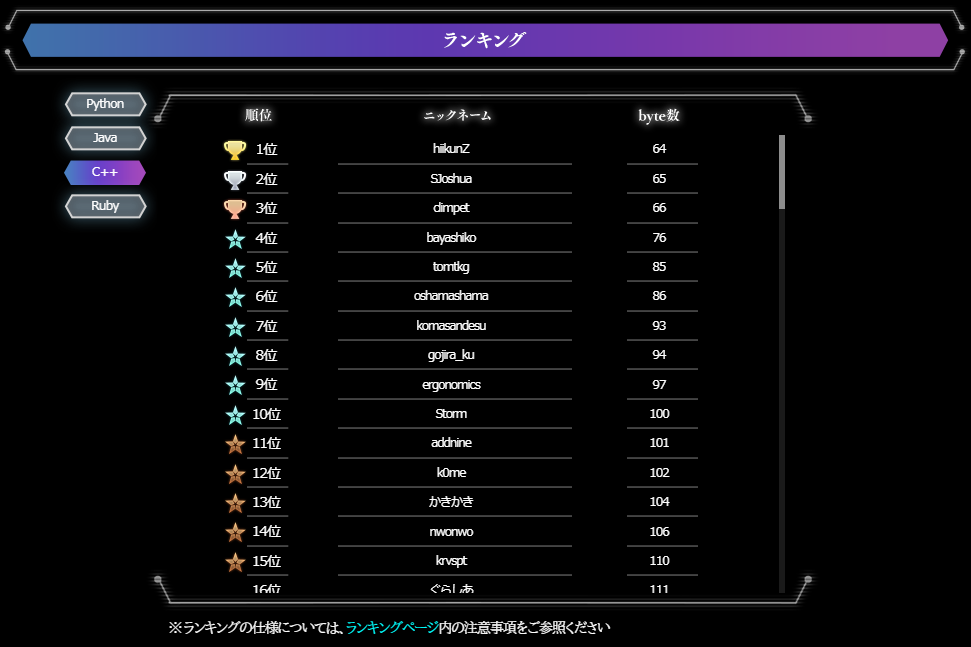
私の解答は,30byteでした.(挑戦するのが遅すぎました)
C++でも挑戦したところ,85byteで5位に入りました.Javaは189byteで,28位でした.
廃マンションの一室
n, a = int(input()), ""
while n != 0:
n, m = divmod(n, 3)
a = str(m) + a
if m == 2: n += 1
print(a or 0)
入力値$n$が0になるまで,whileでループさせます.
変換先が3進数なので$n$を3で割り,余りmを出力$a$に格納します.
$(2)_ {3}$を$(-1)_ {10}$として扱うので,m==2の時は,nに1を加えます.
出力はaですが,aが空文字列の時は,0を出力します.
結構難しめです.
自然の残る公園
import numpy as np
f = lambda: np.fromstring(input(), dtype=int, sep=' ')
s = f()
v = [np.linalg.norm(s[1:] - f()) for _ in range(s[0])]
print(np.argmin(v) + 1)
numpyを使います.
入力文字列からnumpyのndarray数値配列を作る処理は,関数化すると便利です.
距離の計算にはnp.linalg.norm,最小値となるデータを見つけるにはnp.argminを使います.
Rank B:
一番通りの繁華街
import numpy as np
n = int(input())
m = np.array([list(input()) for _ in range(n)]) == '.'
print(sum(np.sum(m[:-i, :-i] & m[:-i, i:] & m[i:, :-i] & m[i:, i:]) for i in range(1, n)))
入力から,要素がbool型のndarrayを作成します.
そして,1辺の長さが$1,2,\dots,n-1$である正方形を確認し,条件を満たす正方形の合計を出力します.
&でつないでいる4要素は,それぞれ正方形の四隅(=左上,右上,左下,右下)を表します.
i=1の時は,$(n-1)\times(n-1)$個の正方形について,四隅がtrueであるか確認します.
最終的にi=n-1になった時は,1個の正方形だけ,四隅がtrueであるか確認します.
ギャングのアジト
f = lambda x: x == x[::-1]
tf = all(f(list(input())) for _ in range(int(input())))
print("Yes" if tf else "No")
あるリストとその反転リストが一致するか確認する処理を関数化しています.
この問題は,Rank Bにしては簡単だと思います.
Rank A: 新都心のハイウェイ
import numpy as np
def is_finish(m, a, b) -> bool: # 終了条件を満たしているか
f = lambda i: range(min(a[i], b[i]) + 1, max(a[i], b[i]))
if a[0] == b[0]: # 同じ行の場合
return all(m[a[0], j] == '.' for j in f(1))
if a[1] == b[1]: # 同じ列の場合
return all(m[i, a[1]] == '.' for i in f(0))
return False
def highway():
H, _ = map(int, input().split())
m = np.array([list(input()) for _ in range(H)]) # マップ
a = np.argwhere(m == "A")[0] # "A"の位置
b = np.argwhere(m == "B")[0] # "B"の位置
movable = set(map(tuple, np.argwhere(m != "#"))) # 訪問可能な位置の集合
queue = [[a, 0]] # BFSのキュー: [位置, 距離]
while queue: # Breadth-First Search
a, dist = queue.pop(0) # キューの先頭を取得
if is_finish(m, a, b): # 終了条件を満たしている
print(dist) # 距離を出力
return
for d in [(-1, 0), (1, 0), (0, -1), (0, 1)]: # 4方向の確認
pos = (a[0] + d[0], a[1] + d[1]) # 位置の更新
if pos in movable: # 訪問可能
queue.append([pos, dist + 1]) # 現在位置と距離をキューに追加
movable.remove(pos) # 訪問済みとして削除
print(-1) # AからBを見つけることができない
highway()
まず,与えられたマップm,"A"の位置a,"B"の位置bを変数として持ちます.
そして,この3つを入力として,終了条件を満たしているか確認する関数is_finishを作成します.
aとbが同じ行か同じ列にあり,かつ,その間には'.'しかないとき,プログラムを終了します.
mとbを固定し,aを移動させることで,終了条件を満たす最小移動回数を探索します.
終了条件を満たす位置aの探索には,幅優先探索を用います.
訪問可能な位置を集合movableに記録し,探索後に削除していきます.
探索位置とその位置から"A"までの距離は,queueで管理します.
まず,queueから取り出した位置aを確認します.
aが終了条件を満たす場合,距離distを出力します.
aが終了条件を満たさない場合,その位置の上下左右4方向を確認します.
新しい位置posが訪問可能な場合,queueに[位置, 距離]を記録し,movableから削除します.
以上の処理をqueueが無くなるか,終了条件を満たすまで,無限に繰り返します.
queueが無くなった場合,-1を出力します.
Rank S: 思い出の屋上
import numpy as np
from scipy.spatial import distance
H, W, M = map(int, input().split())
m = np.zeros([H, W], bool) # マップ
rc = np.array([[r, c] for r in range(H) for c in range(W)])
f = lambda r, c, s: s >= distance.cdist(
np.array([[r, c]]), rc, "cityblock"
).reshape(H, W)
for _ in range(M):
r, c, s = map(int, input().split())
m[f(r - 1, c - 1, s)] = True # r, c, sでマップを更新
max_s = 0 # 他の縄張りとギリギリで重なる,最大のs
for r, c in rc: # マップを全探索
for s in range(max_s, max(H, W)): # s = max_sから探索
if np.any(m & (f(r, c, s))): # 他の縄張りと重なる
max_s = max(max_s, s) # max_sを更新
break
print(max_s - 1) # 他の縄張りと重ならないsを出力
まず,$H\times W$でbool型のマップmを作成し,その全要素アクセス用の配列rcも作成します.
次に,r,c,sを入力として受け取る,関数fを作成します.
関数fの出力は,mと同じ$H\times W$のbool型のマップで,中心$(r,c)$からのマンハッタン距離がs以下の範囲のみTrueになっています.
そして,与えられた$M$行の入力で,マップmを更新します.
他の縄張りと重ならない最大のsの探索ですが,マップの全箇所を確認します.
すべての地点$(r,c)$について,最大のsで縄張りを持てるかチェックします.
知りたいのは最大のsのため,s = max_sから探索をスタートすることで,効率化を図ります.
また,他の縄張りと重なってしまったら,すぐにその地点$(r,c)$での探索をストップします.
最後,max_sは他の縄張りとギリギリで重なる最大のsなので,他の縄張りと重ならないs = max_s -1を出力します.
縄張りを作成できない場合は,-1を出力します.
SQL(解答のみ)
SQLは不得意なので,解答だけ載せます.Rank CとDの解答は,こちらの解答例と同じです.
SELECT
id, name
FROM
person;
SELECT
id, talk
FROM
memory
ORDER BY
id ASC
LIMIT 10;
SELECT
memory.id, memory.talk
FROM
memory
INNER JOIN
category ON memory.category_id = category.id
WHERE
category.name = "悲しみ" AND memory.importance >= 3;
SELECT
memory.id AS memory_id,
memory.talk AS memory_talk,
battle.result AS battle_result
FROM
log
INNER JOIN
memory ON log.memory_id = memory.id
INNER JOIN
battle ON log.battle_id = battle.id
WHERE
log.created_at >= "2085-08-01" AND log.created_at <= "2087-10-20"
SELECT
memory.id AS id,
memory.talk AS talk,
person.name AS name,
battle.created_at AS created_at
FROM
person
INNER JOIN
battle ON person.id = battle.person_id
INNER JOIN
log ON log.person_id = person.id
INNER JOIN
memory ON log.memory_id = memory.id
WHERE
person.importance = 5 AND person.deleted_at = battle.created_at;
終わりに
paizaに久しぶりに取り組んだのですが,楽しいですね.
なんとか休みの間にキャンペーン問題をすべて解くことが出来て,よかったです.
Rank Sはscipyを使えたこともあり,それなりの苦労で解けました.
今回の問題では,個人的にRank Aが一番難しかったです.
掲載したRank Aの解答も,好きではありません.
これだけ,どうしても別関数を作成しないと色々面倒でした.
また,movableはtupleのsetにせざるを得ませんでした.
tupleはpos = a + dというベクトルの足し算が不可能なんですが,listやndarrayにすると型変換いちいち必要だったり,if pos in movableが複雑な記述になるデメリットが大きかったので,妥協しました.
切実に,paizaでMATLABが使えるようになって欲しいですね.
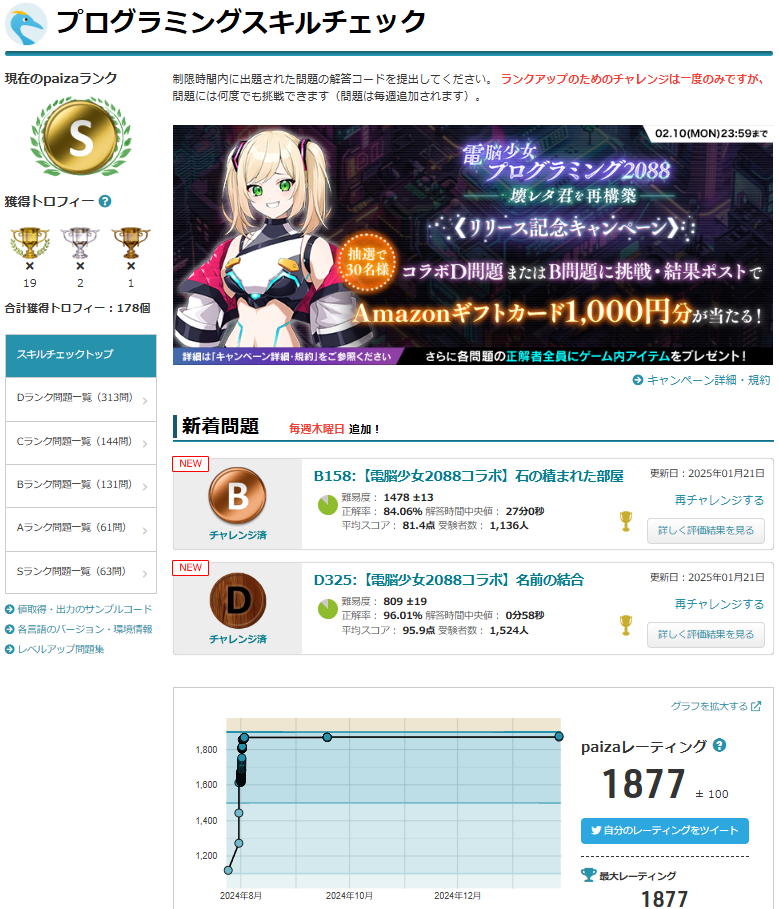
ちなみに,私の現在のpaizaレーティングは1877で,合計獲得トロフィーは178個でした.
過去のpaiza関連記事: