前回までのお話
twitter APIで遊んでみる #1(環境作り)
twitter APIで遊んでみる #2(ユーザータイムラインの取得)
twitter APIで遊んでみる #3(検索結果の取得)
twitter APIで遊んでみる #4(形態素解析してみる(MeCabの環境作り))
twitter APIで遊んでみる #5(twitterの検索結果を形態素解析してみる)
はじめに
前回まででtwitterの検索結果をMeCabで形態素解析できるようになりました。形態素解析をしたデータで遊んでみたいと思います。単語の出現頻度を可視化できるwordcloudというものがあるそうなので、まずは使ってみようと思います。
wordcloudとは
WordCloudはテキストデータを頻度の高い単語ほど大きな文字で表示した単語頻度図を生成するライブラリです。

こんなやつですね。
テキストデータをWordCloudに投入するだけではうまくいきません、WordCloudでテキストの単語頻度図を作成するには、テキストのわかちがきをする必要があります。要は半角スペースで区切られていればそれでよさそうです。
前回まででMeCabで文章のわかちがきはできているので、データをぶっこむだけでよさそうです。
今回はそこまでせず、適当な英文を拾ってきて投入しようと思います。英文だったらそのままでも単語毎に半角スペースで区切られてますからね。
環境作り
前回までの環境作りは実施済みのうえで、以下を実施します。
# 必要なモジュールのインストール
sudo pip3 install matplotlib wordcloud pandas
# 元画像の取得
wget https://github.com/amueller/word_cloud/raw/master/examples/alice_mask.png
wordcloudモジュールの詳細は、以下のgithubに書かれています。
https://github.com/amueller/word_cloud
元画像は、上記githubのexamplesから取得しました。文字を記載する型のような画像です。
ダウンロードした画像はこんな画像です。

この黒い部分に、解析した単語が描かれていくようです。
とりあえずwordcloudを使ってみる。
まずは単純にwordcloudを使ってみます。コードは上記githubのexamplesに入っているコードを参考にしました。
ちなみにプログラムのファイル名をwordcloud.pyとすると以下のようなエラーになるので注意してください。僕はこれで15分ぐらい時間を無駄にしました。
そのときのエラー
root@localhost:twitter$ ./wordcloud.py
Traceback (most recent call last):
File "./wordcloud.py", line 5, in <module>
from wordcloud import WordCloud, STOPWORDS
File "/root/twitter/wordcloud.py", line 5, in <module>
from wordcloud import WordCloud, STOPWORDS
ImportError: cannot import name 'WordCloud'
コード(wc.py)
wordcloudに渡す文章は、英語wikipediaのHamburgerの冒頭をコピってきました。
# !/usr/bin/env python3
# -*- coding:utf-8 -*-
from os import path
from PIL import Image
from wordcloud import WordCloud, STOPWORDS
import numpy as np
import matplotlib.pyplot as plt
# カレントディレクトリの設定
d = path.dirname(__file__)
# WordCloudに渡す文章
text = "This article is about the sandwich. For the meat served as part of such a sandwich, see Patty. For other uses, see Hamburger (disambiguation).Hamburger RedDot Burger.jpg Hamburger with french fries and a beer Course Main course Place of origin United States or Germany disputed Created by Multiple claims (see text) Serving temperature Hot Main ingredients Ground meat, bread Cookbook: Hamburger Media: Hamburger A hamburger, beefburger or burger is a sandwich consisting of one or more cooked patties of ground meat, usually beef, placed inside a sliced bread roll or bun. The patty may be pan fried, grilled, or flame broiled. Hamburgers are often served with cheese, lettuce, tomato, onion, pickles, bacon, or chiles; condiments such as ketchup, mayonnaise, mustard, relish, or special sauce and are frequently placed on sesame seed buns. A hamburger topped with cheese is called a cheeseburger. The term burger can also be applied to the meat patty on its own, especially in the United Kingdom, where the term patty is rarely used, or the term can even refer simply to ground beef. The term may be prefixed with the type of meat or meat substitute used, as in turkey burger, bison burger, or veggie burger Hamburgers are sold at fast-food restaurants, diners, and specialty and high-end restaurants (where burgers may sell for several times the cost of a fast-food burger, but may be one of the cheaper options on the menu). There are many international and regional variations of the hamburger."
# 元画像の指定
alice_mask = np.array(Image.open(path.join(d, "alice_mask.png")))
# WordCloudのパラメーター設定
wc = WordCloud(
background_color = "white",
max_words = 2000,
mask = alice_mask,
)
# WordCloudの実行
wc.generate(text)
# 生成した画像をファイルとして出力
wc.to_file(path.join(d, "alice.png"))
実行結果
alice.png が出力されました。
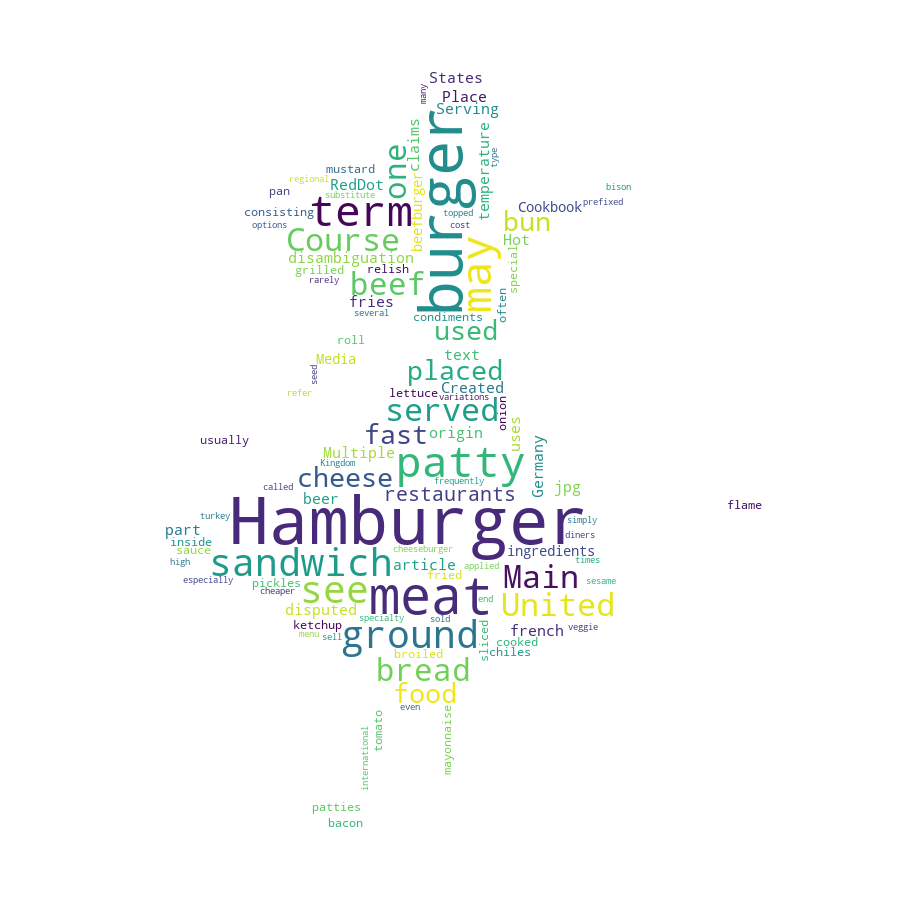
できてるっぽいですね!
終わりに
これでwordcloudの簡単な使い方がわかりました。単語頻度図って面白いですね。
次回は形態素解析した(半角スペースで分割された)日本語の文章データをwordcloudに投入したいと思います。