Introducing Kafka Quotas in Aiven for Apache Kafka®の翻訳です。
2023年7月11日
Aiven for Apache Kafka®におけるKafkaクォータの導入
Aiven for Apache Kafka®はKafkaクォータを導入し、クライアントアプリケーションがKafkaクラスタで使用できるリソースを制御できるようにします。
Aiven for Apache Kafka®は、基盤となるインフラや管理オーバーヘッドを気にすることなく、ストリーミングデータのニーズに対してApache Kafka®のパワーとスケーラビリティを活用することを支援します。プロダクショングレードのKafka環境では、データが生成、消費、エンリッチ、変換される専用のトピックを持つことで、複数のチームがクラスタリソースを共有することがよくあります。
共有Kafkaクラスタには、Kafka環境のパフォーマンスの安定性や運用の容易さなど、組織にとって多くのメリットがありますが、それを実行するプラットフォーム・チームにとっては、ガバナンスや標準化に関する課題もあります。複数のチームが1つのクラスタを使用する場合、特定のアプリケーションがクラスタを過剰に使用し、他のトピックのパフォーマンスに悪影響を与える「ノイジー・ネイバー問題」が発生する可能性があります。このような状況を避けるために、データプラットフォームチームとエンジニアリングマネージャは、特定のクラスタ内のクライアントアプリケーションによる使用リソースを制御する方法として、Quotas in Apache Kafkaを活用しています。
本日は、Aiven for Apache KafkaでKafkaクォータが利用可能になったことを発表します。Aivenのお客様は、AivenコンソールやAivenのAPI、CLIから直接、各アプリケーションの使用リソースを定義、更新、検証することができます。以下の段落では、Apache Kafkaにおけるクォータとは何か、共有Kafkaセットアップにおけるその利点、そしてAivenプラットフォームで活用できるようになったサポートされているクォータタイプについてご紹介します。詳細はこちらをご覧ください!
Kafka クォータの簡単な説明
Apache Kafkaのクォータは、Kafkaクライアントが使用するブローカーリソースの数を管理・制限するメカニズムを提供します。Kafkaのクォータを定義することで、Apache Kafkaの管理者はデフォルトを設定し、指定されたクラスタのリソースが異なる生産または消費アプリケーションによってどのように利用されているかを監督することができます。プロデュース/コンシューマー・アプリケーションがクォータの上限に達している場合、クラスタは関連するイベントのインジェスト/プロダクションをスローダウンし、クラスタの安定したパフォーマンスを維持します。Kafkaクォータは、異なるチーム、アプリケーション、またはユースケースが同じKafkaクラスタリソースに対してイベントを消費/生成する共有Kafkaクラスタに最適です。このようなシナリオでは、各アプリケーションがクラスタで使用できるリソースを制御することで、クラスタのパフォーマンスが一貫性を保ち、潜在的な劣化がないことを保証します。
Kafkaでクォータが必要な理由
本番グレードのワークロードには、主に2つのデプロイオプションがある。まず、Kafka管理者はアプリケーションのグループ化、使用シナリオ、コンプライアンス要件を定義し、それらに基づいてアプリケーション固有のニーズを満たす専用の単一目的のKafkaクラスタをデプロイすることができます。あるいは、Kafkaユーザーは組織全体に対して共有の多目的Kafkaクラスタをデプロイし、このメインKafkaクラスタから複数のアプリケーションや社内アプリケーションチームのユースケースに対してストリーミングデータへのアクセスを提供することができる。
どのようなデプロイを選択するにしても、単一のアプリケーション専用の孤立したKafkaクラスタを持つことはまれです。ほとんどの場合、クラスタは複数のデータフローやユースケースのバックエンドを表している。そのため、アプリケーションによって使用パターンが異なり、変動するデータトラフィックや変動するパフォーマンスが、使用中のアプリケーションだけでなく、同じクラスタリソースを共有する他のすべての使用クライアントに影響を与える可能性があります。
Apache Kafkaのクォータは、クラスタリソースの事前定義された使用制限を強制することで、このような状況を防ぎ、パフォーマンスの低下やクラスタの完全な停止を防ぐことができます。例えば、ロンドン市内の交通信号機からのセンサーデータを使用するIoTプロバイダーは、日中の交通量が多く、夜間の交通量が少なくなる可能性があります(ほとんどのバスとロンドンの地下鉄は午前0時頃に停止するため)。すべてのアプリケーションが1日中Kafkaクラスタに読み書きできるようにする代わりに、あまりタイムクリティカルでないアプリケーションは、クラスタの劣化や停止を防ぐために、日中はトピックへのデータ書き込み量を少なくすることができます。
Apache Kafkaのクォータは、ユースケースとアプリケーションの間にリソースの境界を作り、Kafka管理者がクラスタ内のKafkaブローカーごとに各クライアントアプリケーションの生成/消費トラフィックを設定できるようにすることで、すべてのユースケースが効率的に動作するための適切なリソースを確保するセキュリティ方法を提供します。割り当てられたリソースに応じて、Kafkaブローカーはクライアントアプリケーションのリクエストをスロットルすることで、潜在的なリソースの飽和や、設定全体のパフォーマンスを低下させるような少数の不正なクライアントによるクラスタの停止を回避します。Kafkaのクォータは、Kafka運用の健全性を維持し、管理するために不可欠なコンポーネントです。特に、複数のチームが一元化されたKafkaインスタンスからストリーミングデータにアクセス、生成、または消費するような、共有されたプロダクショングレードのKafkaワークロードでは重要です。
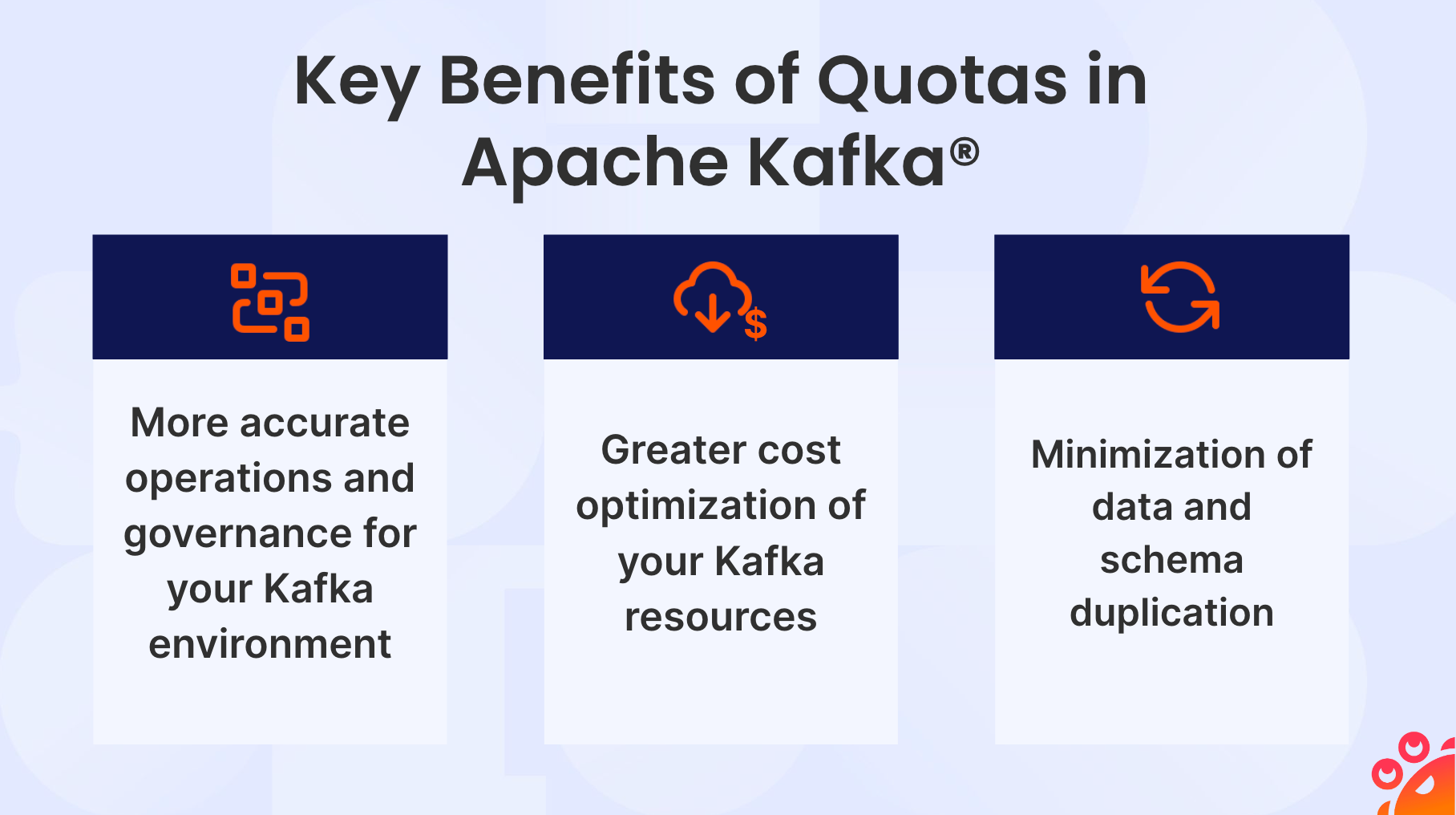
Apache Kafkaにおけるクォータの主な利点
Apache Kafkaでクォータを使用すると、組織にとって複数の利点があり、企業のKafkaユーザーにとってより多くのユースケースが可能になります。これらの利点のいくつかは以下の通りです:
1.Kafka環境のより正確な運用とガバナンス。
Apache Kafkaの利用が増えれば増えるほど、数十(あるいは数百)のKafkaクラスタを運用することが、リアルタイムデータをさらに活用する上でのボトルネックになりがちです。そこで、KlawやConduktorのような技術を利用したApache Kafkaのデータガバナンスが、組織全体のApache Kafkaガバナンスの向上に役立ちます。さらに、データのスキーマを効率的に管理することは、Kafkaのセットアップにおいて必須となります。
Apache Kafkaのクォータを活用することで、データプラットフォームチームやApache Kafkaのオペレータは、Kafkaクラスタを使用するユーザー、彼らがアクセスできるもの(KafkaトピックとACLの観点から)、および彼らに許可されるリソースの消費量(クォータ制限)をより適切に制御することができます。
2.**Kafkaリソースのコストを最適化します。
ストリーミングの世界、特に多目的シナリオではスループットが変化するため、リソースの使用量を予測するのは複雑です。そのため、多くの場合、アプリケーションチームが最終的な目標を達成できるよう、リソースを過剰にプロビジョニングしています。Kafkaのクォータは必要に応じて調整できるため、データプラットフォームチームは必要に応じてワークロードの優先順位を変更することができます。そのため、データプラットフォームチームは、ピーク時に上限を高く設定し、不要なときには他のアプリケーションに解放することができます。
Kafkaのクォータは、Kafkaクラスタのパフォーマンスの安定性をさらに向上させると同時に、ユースケース全体で単一のKafkaインスタンスを共有し、関連する支出を組織内のチームに分散させることで、固定費を最適化するのに役立ちます。特に、企業がクラウドインフラストラクチャのコストを削減し、コスト最適化戦略を利用しようとしている時代には、Kafkaリソースを効率的に使用する能力を持つことは、データプラットフォームチームだけでなく、FinOpsやテクノロジーエグゼクティブにとっても重要な鍵となります。
3.データとスキーマの重複を最小化する。
最近の技術系組織で多目的Apache Kafkaクラスタを採用する際の最大の障害の1つは、パフォーマンスの予測可能性です。利害関係者が必要としているのは、プロデューサーからコンシューマーへのデータストリーミングだけではありません。Apache Kafkaのクォータは、アプリケーションごとにカスタマイズされたリソース制限を保証するメカニズムを提供し、Kafkaクラスタの全体的なパフォーマンスの予測可能性を高めます。
以前は専用の単一目的のKafkaクラスタで処理されていたほとんどのユースケースは、現在では共有の多目的クラスタでも同じように管理でき、データとスキーマの統合という追加的なメリットも提供します。
Apache Kafkaでクォータを設定することで、データプラットフォームチームが異なるKafkaトピック用の新しいデータスキーマを見つけ出すのに費やす時間を最小限に抑えることができます。これにより、クラスタ間でのスキーマの重複に費やす時間が大幅に削減されるとともに、価値創造に取り組むチームのスピードが上がり、市場投入までの時間が短縮されます。
Aiven for Apache Kafkaでサポートされるクォータタイプ
Aiven for Apache Kafkaには、リソースを効率的に管理するためのさまざまなクォータが用意されています。これらのクォータは、ネットワーク帯域幅とCPU使用量の管理方法をより柔軟にします:
- コンシューマスロットル(ネットワーク帯域幅クォータ)***:このクォータにより、コンシューマーが1秒間にKafkaクラスターから取得できるデータ量を制限できます。最大ネットワークスループットを設定することで、単一のコンシューマーが過剰なネットワーク帯域幅を使用することを防ぎます。
Producer throttle (Network bandwidth quota):コンシューマスロットルと同様に、このクォータは、プロデューサーが1秒間にKafkaクラスターに送信できるデータ量を制限します。プロデューサが過剰なデータを送信してシステムに負荷をかけないようにし、システムの安定性を維持します。 - CPUスロットル**:このクォータはCPU使用量の管理に関するものです。総 CPU 時間のパーセンテージを設定することで CPU 使用量を管理できます。特定のクライアントIDやユーザーのCPUリソースを制限することで、個人がCPUリソースを独占することを防ぎ、公平で効率的なリソース利用を促進します。
Quotas におけるクライアント ID とユーザー、および Quotas の実施に関する詳細は、関連する ドキュメント を参照してください。
はじめに
AivenコンソールまたはAiven APIを使用して、Aiven for Apache Kafka®サービスのクォータを簡単に追加および管理できます。Aiven for Apache Kafkaインスタンスでクォータを追加、設定、変更する方法の詳細については、ドキュメントの手順に従ってください。
まだAivenのお客様ではありませんか?デモを予約してAiven for Apache Kafkaを直接お試しいただくか、無料の30日間こちらからご利用いただけます!