みなさん、こんにちは
マイクロソフト佐々木です。
本日は、実装の相談でいただく、Copilot Studioでナレッジ(RAG)とツール(Connecter/Flow/MCP/API)の使い分けについてです。

はじめに
データを取得するという目的においては、ナレッジとツールどちらのアプローチでも可能です。
一方でなにを選択するかは、ナレッジやツールの制約 x データの特性や種類 x データの配置場所 x ユースケースなど複数要素で適切なアプローチを検討する必要があり、このブログではご説明していきたいと思います。
最初に述べると、これといった正解はございませんし、組み合わせて成り立つものも多数ございます。あくまでひとつの解として参考までにお役に立てばと思います。
2025年12月時点の情報をもとに独自解釈を加えて、まとめています。
最新情報をご確認ください。
AtoAやマルチエージェントでのアプローチを含めていません
前提:それぞれの特性について理解する
本題の前にCopilot Studioにおけるナレッジ(RAGの根底となる機能)とツールについて説明していきます。
Copilot Studioにおいては、まずはナレッジとツールの特性を理解することが重要かと思います。
ナレッジ(RAG/検索 → 回答生成)
こちらはいわゆるRAGです。
「人事規定について教えて」という質問に対して、設定されたデータソースに対して、インデクシングされたファイルを対象に検索をし、LLMが回答を生成します。

- 目的:作成済みのインデックス(検索用の索引)から関連情報を検索し、取得した根拠(抜粋・参照)をもとに “根拠付きの回答” を生成する
- ナレッジ例:Web / SharePoint / OneDrive / Dataverse / Azure AI Search など
- ユースケース例:FAQ / 規程 / 手順書 / 社内KB
- 特徴:各ナレッジソースから上位ヒット(例:上位3件)を取って回答を生成する
- 得意なシナリオ:『国内の出張経費の上限は?』『この規程の要点は?』など(要約 / 抽出 / 分類)
- 不向きなシナリオ:『全件を対象に集計して、前年差やランキングを出して』など(全件取得 / ランキング / 前年差 / 厳密集計)※最近は Agentic RAG で反復取得やツールと組み合わせることで精度も強化
ツール(外部呼び出し/クエリ/処理 → 結果を使って回答)
ツールは、Copilot Studio に構成したコネクタ等を通じて、DB や業務システム(およびそれらの API)から必要なデータを取得し、その取得結果をもとに LLM が回答を生成します。取得のみにならず、検索、集計、更新、削除なども可能です。
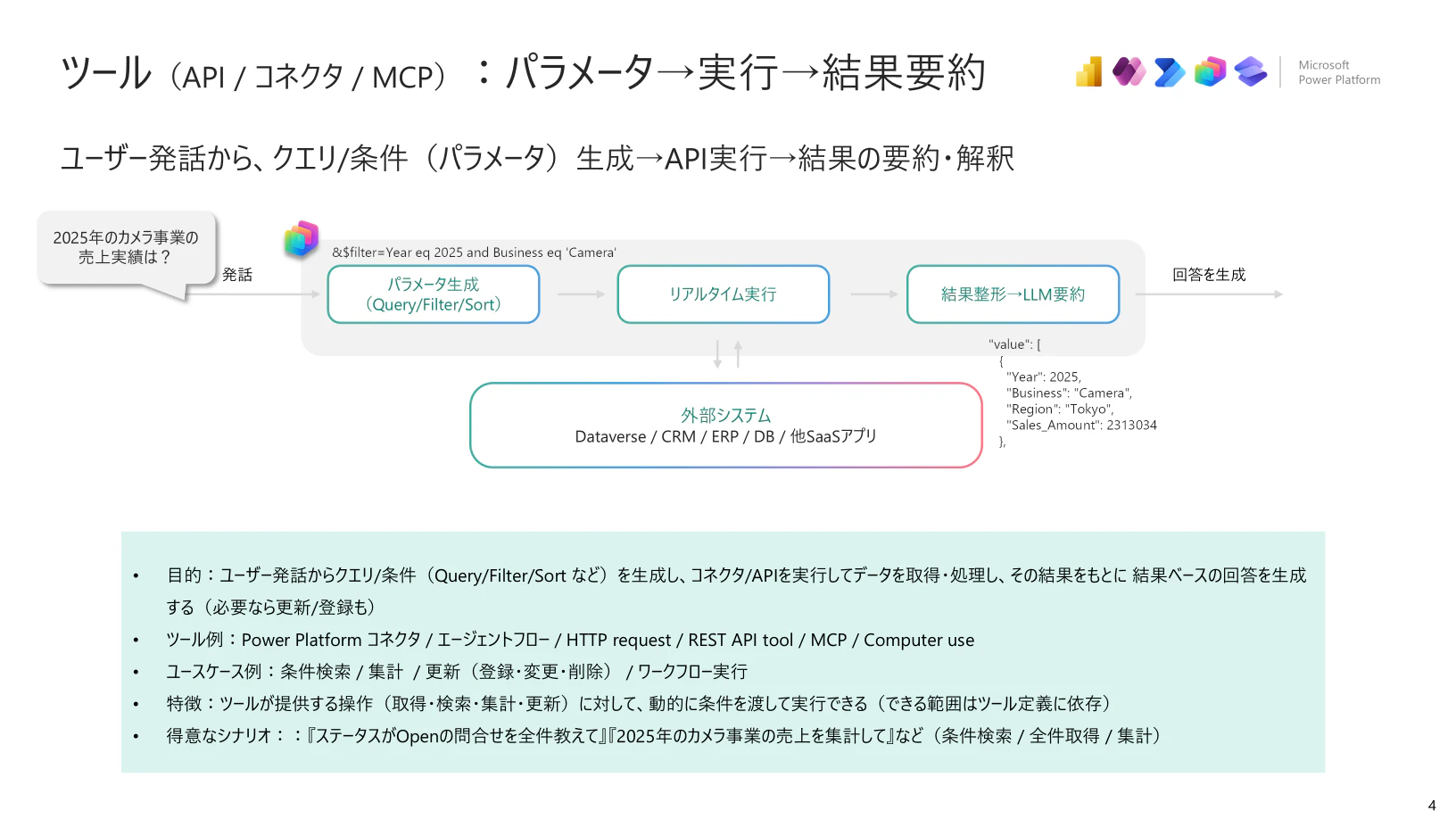
- 目的:ユーザー発話からクエリ/条件(Query/Filter/Sort など)を生成し、コネクタ/APIを実行してデータを取得・処理し、その結果をもとに 結果ベースの回答を生成する(必要なら更新/登録も)
- ツール例:Power Platform コネクタ / エージェントフロー / HTTP request / REST API tool / MCP / Computer use
- ユースケース例:条件検索 / 集計 / 更新(登録・変更・削除) / ワークフロー実行
- 特徴:ツールが提供する操作(取得・検索・集計・更新)に対して、動的に条件を渡して実行できる(できる範囲はツール定義に依存)
- 得意なシナリオ::『ステータスがOpenの問合せを全件教えて』『2025年のカメラ事業の売上を集計して』など(条件検索 / 全件取得 / 集計)
以上の特性からわかる原則
-
ナレッジ(RAG)は「検索で拾えた根拠」から回答生成するため、網羅処理/全件推論/数値分析は不得意になりやすい
- 向いている例:給与規定について教えて / 国内出張ルールについて教えて
-
一方で構造化データの条件検索・集計・更新はツール(コネクタ/ MCP / コードインタープリター 等)で実施する方が確実
- 向いている例:ステータスがオープンな問合せについて全件教えて / 男性からの全アンケート回答を要約して / XX年のカメラ事業の売上について集計して
- 大量データや厳密な数値は「取得(ツール)→整形/要約(LLM)」で処理
-
ほかにもドキュメントそのものの分析や比較などはLLMに直で指定して渡す方式を検討するかツール(AI Tools)などを用いて実装した方がシンプル・確実に実装できるかとは思います。
このあたりについては、下記のブログでも記載しています。
管理者側や開発者側で気にするべき共通点
Microsoftにおけるエージェントのソリューション全般にいえますが、基本的にはユーザーの権限を越えたデータアクセスはおこないません。
ですが、管理者側や開発者側で気にするべき内容もございますので、ベースラインは理解いただくといいかと思います。
- スロットリングやSLA
- DLP/権限トリミング/索引更新を設計の前提に入れる
- ユーザーの認証をデフォルトで利用
1. Copilot Studioにおけるナレッジを深堀する
上記における前提を理解したうえで、Copilot Studioにおけるナレッジの仕様や制約等をまとめていきます。
1-1. サポートされる主要ナレッジと仕様
まずは主要ナレッジと仕様についてまとめます。あくまで執筆時点の仕様ですので、ご留意ください。
また、Learnの内容ご確認ください。
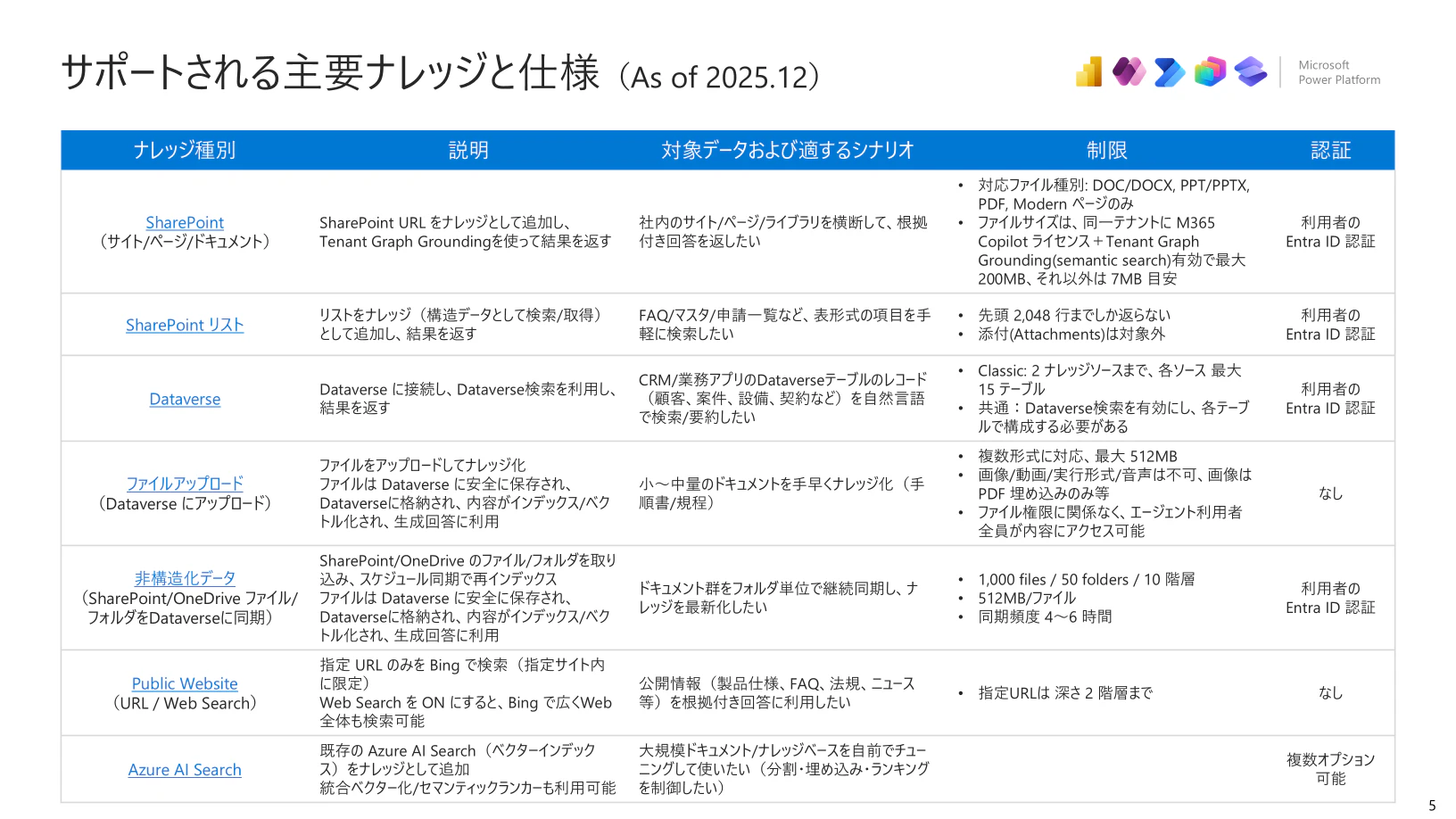
| ナレッジ種別 | 説明 | 対象データおよび適するシナリオ | 制限 | 認証 |
|---|---|---|---|---|
| SharePoint(サイト/ページ/ドキュメント) | SharePoint URL をナレッジとして追加し、 Tenant Graph Grounding を使って結果を返す |
社内のサイト/ページ/ライブラリを横断して、根拠付き回答を返したい | • 対応ファイル種別: DOC/DOCX, PPT/PPTX, PDF, Modern ページのみ • ファイルサイズは、同一テナントに M365 Copilot ライセンス + Tenant Graph Grounding(semantic search) 有効で最大 200MB、それ以外は 7MB 目安 |
利用者の Entra ID 認証 |
| SharePoint リスト | リストをナレッジ(構造データとして検索/取得)として追加し、結果を返す | FAQ/マスタ/申請一覧など、表形式の項目を手軽に検索したい | • 先頭 2,048 行までしか返らない • 添付(Attachments)は対象外 |
利用者の Entra ID 認証 |
| Dataverse | Dataverse に接続し、Dataverse検索を利用し、結果を返す | CRM/業務アプリのDataverseテーブルのレコード(顧客、案件、設備、契約など)を自然言語で検索/要約したい | • Classic: 2 ナレッジソースまで、各ソース最大 15 テーブル • 共通: Dataverse検索を有効にし、各テーブルで構成する必要がある |
利用者の Entra ID 認証 |
| ファイルアップロード(Dataverse にアップロード) | ファイルをアップロードしてナレッジ化 ファイルは Dataverse に安全に保存され、Dataverseに格納され、内容がインデックス/ベクトル化され、生成回答に利用 |
小〜中量のドキュメントを手早くナレッジ化(手順書/規程) | • 複数形式に対応、最大 512MB • 画像/動画/実行形式/音声は不可、画像は PDF 埋め込みのみ等 • ファイル権限に関係なく、エージェント利用者全員が内容にアクセス可能 |
なし |
| 非構造化データ(SharePoint/OneDrive ファイル/フォルダをDataverseに同期) | SharePoint/OneDrive のファイル/フォルダを取り込み、スケジュール同期で再インデックス ファイルは Dataverse に安全に保存され、Dataverseに格納され、内容がインデックス/ベクトル化され、生成回答に利用 |
ドキュメント群をフォルダ単位で継続同期し、ナレッジを最新化したい | • 1,000 files / 50 folders / 10 階層 • 512MB/ファイル • 同期頻度 4〜6 時間 |
利用者の Entra ID 認証 |
| Public Website(URL / Web Search) | 指定 URL のみを Bing で検索(指定サイト内に限定) Web Search を ON にすると、Bing で広く Web 全体も検索可能 |
公開情報(製品仕様、FAQ、法規、ニュース等)を根拠付き回答に利用したい | • 指定URLは 深さ 2 階層まで | なし |
| Azure AI Search | 既存の Azure AI Search(ベクターインデックス)をナレッジとして追加 統合ベクター化/セマンティックランカーも利用可能 |
大規模ドキュメント/ナレッジベースを自前でチューニングして使いたい(分割・埋め込み・ランキングを制御したい) | 複数オプション 可能 |
1-2. ナレッジ x データ適合性マトリクス
上記のナレッジに対して、対象とするデータプロファイル(取得対象のデータ配置場所、種別)ごとの適合性をまとめました。主要どころとなりますので、雰囲気を抑えていただくきっかけになればと思います。

SharePointナレッジ / SharePointリスト
- SharePoint(サイト/ページ/ドキュメント) は、SharePoint上のページ/ドキュメント検索に強い(ただし 対応拡張子・サイズ等の制限あり)
-
Excel/CSV 等の表データはそのまま 扱いにくいケースが多い
→ SharePoint リスト化または Dataverse 取り込みもしくは後段で説明するツールと連携してから検索・要約する方が現実的
→リストの場合はAgent 365 MCPなどのツール利用を検討
Dataverse
- 構造化されたデータかつDataverseに保存された(移行できる)データであれば、有効
- Excel/CSV/SharePoint Listなどの移行先として検討
ファイルアップロード/非構造化データ同期
- ファイルアップロード/非構造化データ同期(Dataverse 集約) は、ドキュメントを素早くナレッジ化する手段として有効
- SharePointナレッジより比較的制約が緩い傾向にある
- ただし、Dataverseの容量を消費することになるので、その点もケアしてあげる必要
2. Copilot Studioにおけるツールを深堀する
さらに、Copilot Studioにおけるツールの仕様や制約等をまとめていきます。
2-1. サポートされる主要ツールと仕様
まずは主要ツールと仕様についてまとめます。あくまで執筆時点の仕様ですので、ご留意ください。
また、Learnの内容ご確認ください。

| ツール種別 | 説明 | 対象データおよび適するシナリオ | 制限 | 認証 |
|---|---|---|---|---|
| コネクタ(Connector) | Power Platform の標準/カスタムコネクタのアクションをツール化して呼び出す | M365 / Dynamics / 外部SaaS など、APIで取れる・更新できるもの全般 | • マネージドコネクタの場合、定義された操作のみ • コネクタ応答ペイロード上限 |
接続(コネクション)に基づく |
| エージェントフロー(Agent flow / Power Automate) | “When an agent calls the flow” トリガーで起動し “Respond to the agent” で応答(実行ロジックをフローで実装) | 複数システム横断、条件分岐、承認、更新、通知など業務プロセス自動化(コネクタを束ねたい時) | • 100秒以内に応答 • コネクタ応答ペイロード上限 |
接続(コネクション)に基づく |
| MCP(Model Context Protocol) | MCPサーバーをツールとして追加。サーバーが提供する Tools / Resources をエージェントから利用 | 提供済みのMCPサーバーおよび既存の社内MCPサーバーをCopilot Studioに接続して、取得+操作を統合したい | • MCPサーバー側の制約、設計による | MCP側の認証方式に依存 |
| AI Tools(AI Prompt / AI Builder) | プロンプトをツール化し、分類/抽出/整形などのAI処理を実行 | AI Tools内でのデータ取得はDataverseが主となり、前段でコネクタ等を利用し、データ取得が必要 | • 利用できるモデルによりトークンの上限があり | 接続(コネクション)に基づく |
| Computer Use | Web/デスクトップアプリを、Windows 上で仮想マウス/キーボード操作して実行するツール(APIが無い業務でも自動化) | API 連携できないレガシー/業務Web/管理画面での入力代行・画面遷移・転記・簡易抽出 | • 現時点ではプレビュー • 利用可能な環境リージョンが限定 |
対向システムに依存 |
| Code Interpreter | エージェントが取得したデータをもとに集計/変換/可視化/ファイル生成を実行 | Excel/CSV/PDF/Word/PowerPoint 等のデータ全体を見た分析・統計・グラフ化・加工・レポート生成(ナレッジの取得結果などを利用) | • 現時点ではプレビュー | - |
| REST API | Open API 仕様から REST API をツール化し、外部システムを呼び出して取得/更新する | コネクタが無い外部/社内 API への接続、独自業務システム連携、CRUD、検索API呼び出し、社内データサービス統合 | • 現時点ではプレビュー | API の方式に依存 |
2-2. ツール x データ適合性マトリクス
ナレッジに引き続きツールに対しても、対象とするデータプロファイル(取得対象のデータ配置場所、種別)ごとの適合性をまとめました。
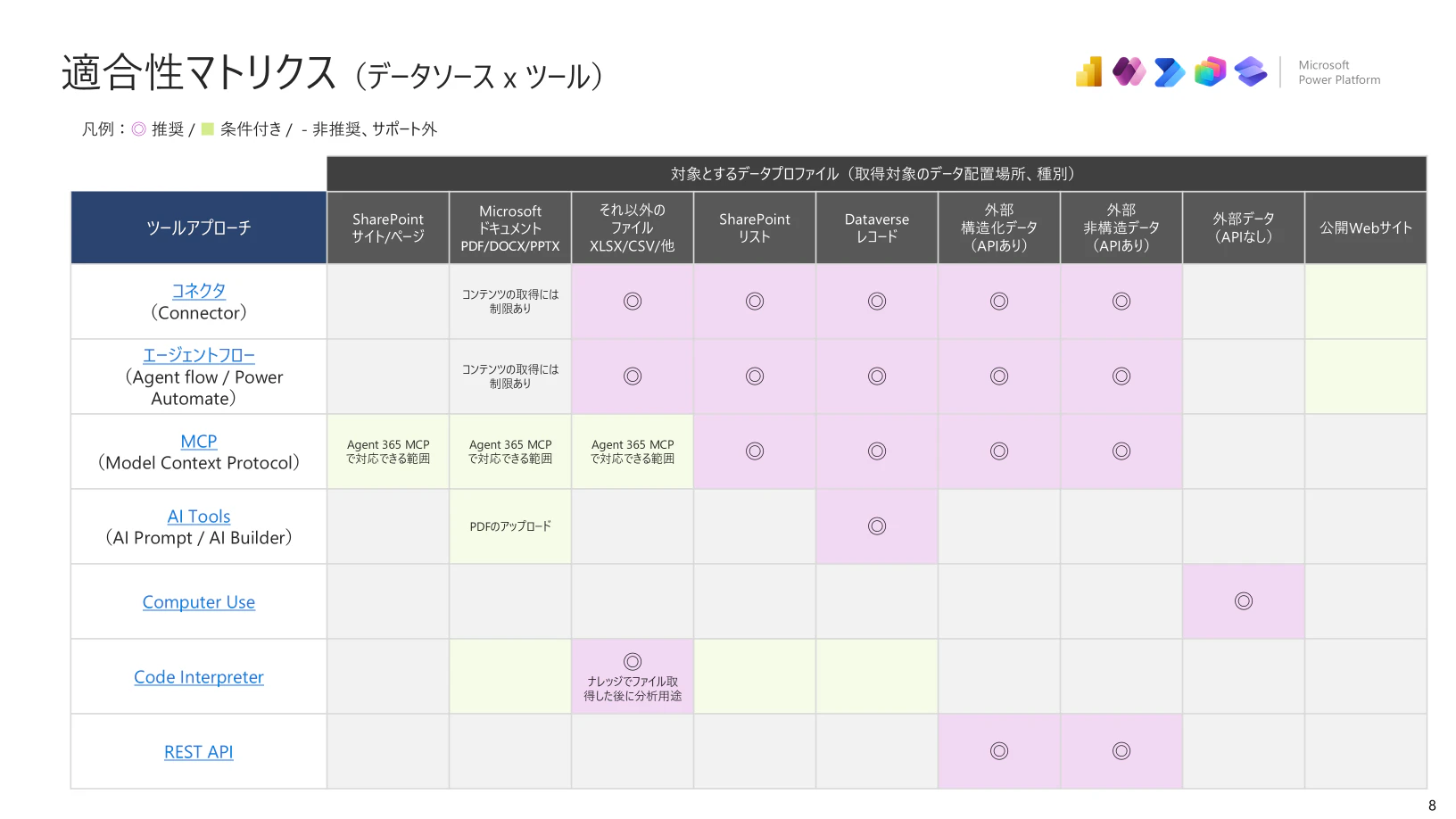
コネクタ(Connector)
- APIで取得/更新できるデータ(SharePoint リスト、Dataverse レコード、外部データ(APIあり:構造/非構造))はコネクタで定義された操作をおこないデータ取得、操作可能
- ただし、ドキュメント(PDF/DOCX/PPTX)の“本文=コンテンツ取得”は制限あり(コネクタ経由で中身を自在に読む用途には不向き)
- 公開Webサイトは **Bing Search系のツールやHTTPリクエストを利用
エージェントフロー(Agent flow / Power Automate)
- 適合範囲はコネクタに近く、複数システム横断・条件分岐・承認・通知など「業務プロセス化」に強い
MCP(Model Context Protocol)
- SharePointサイト/ページ、Microsoftドキュメント、その他ファイルは 要精査(Agent 365 MCPなどで対応できる範囲に依存)
- SharePointリスト / Dataverse / 外部データ(APIあり) はマネージドMCPがすでに提供されているため、そちらを活用
- その他の対向サービスに対してもMCPがラインナップされていれば積極的に利用を検討できる
AI Tools(AI Prompt / AI Builder)
- Dataverse レコード はデータソースとして標準サポート
- PDFはアップロード前提で活用可能 -> ドキュメント比較などで活用
- 位置づけは「取得」ではなく、分類/抽出/整形などのAI処理をツール化するイメージ
Computer Use
- 外部データ(APIなし) に対して利用
- APIが無い/繋げない対象への“最終手段”としての選択肢
Code Interpreter
- XLSX/CSV 等のファイルに対して数値分析などの用途で利用
- “ナレッジ/ツールでファイルを取得した後に、集計・変換・可視化・レポート生成”に使う(分析用途)
REST API
- 「コネクタが無いAPI」を OpenAPI でツール化して呼び出す用途にフィット
3. データの属性からの適合性マトリクス
これまで、ナレッジやツールの仕様・制限およびデータの種類や置き場所に対するマトリクスを説明していきました。もう少し深堀して、ファイルそのものの拡張子など細かな内容もブレイクダウンしていきます。
基本的には、いままでまとめてきた内容がベースになりますが、取得するデータの属性などにフォーカスしています。
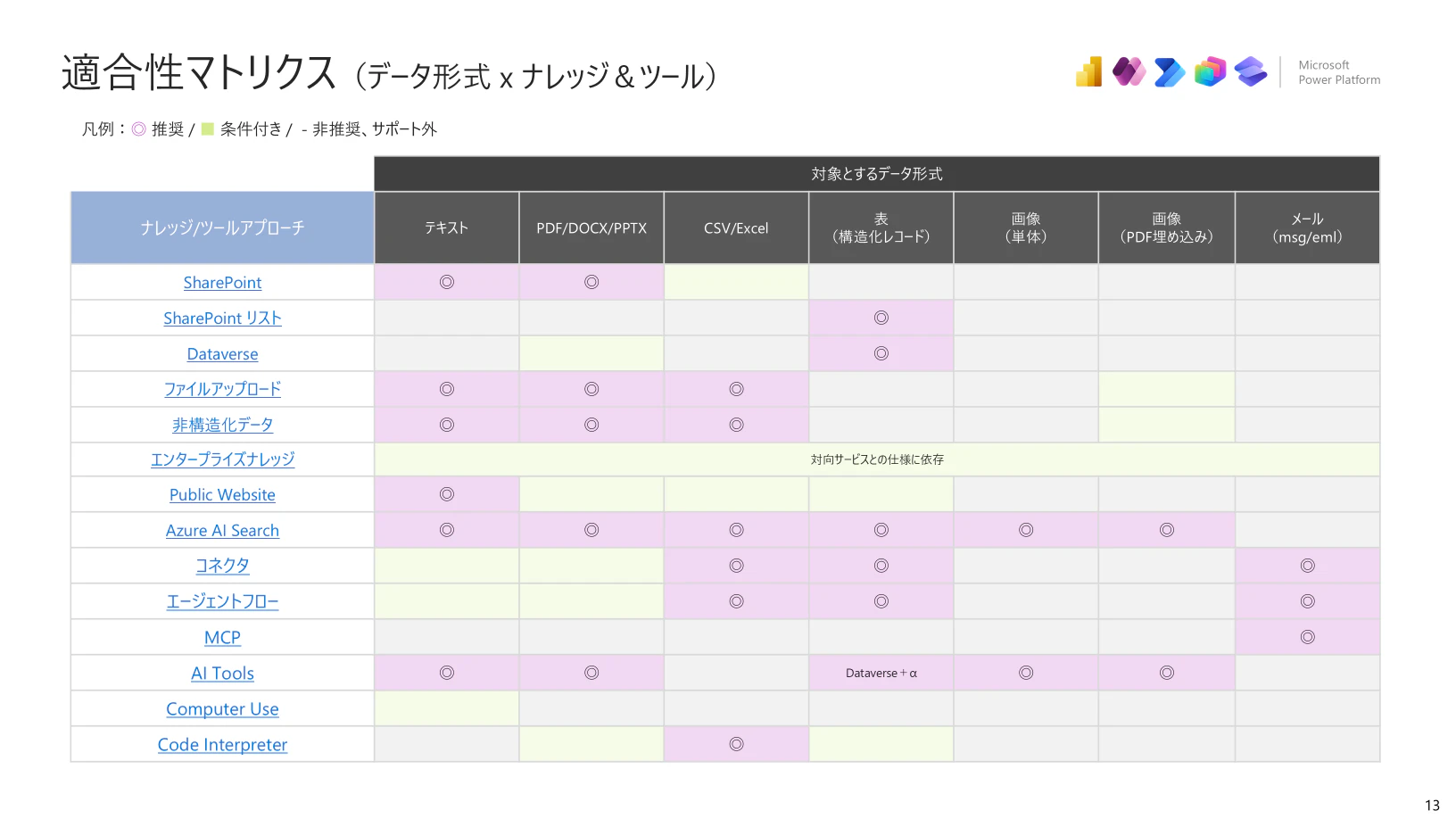
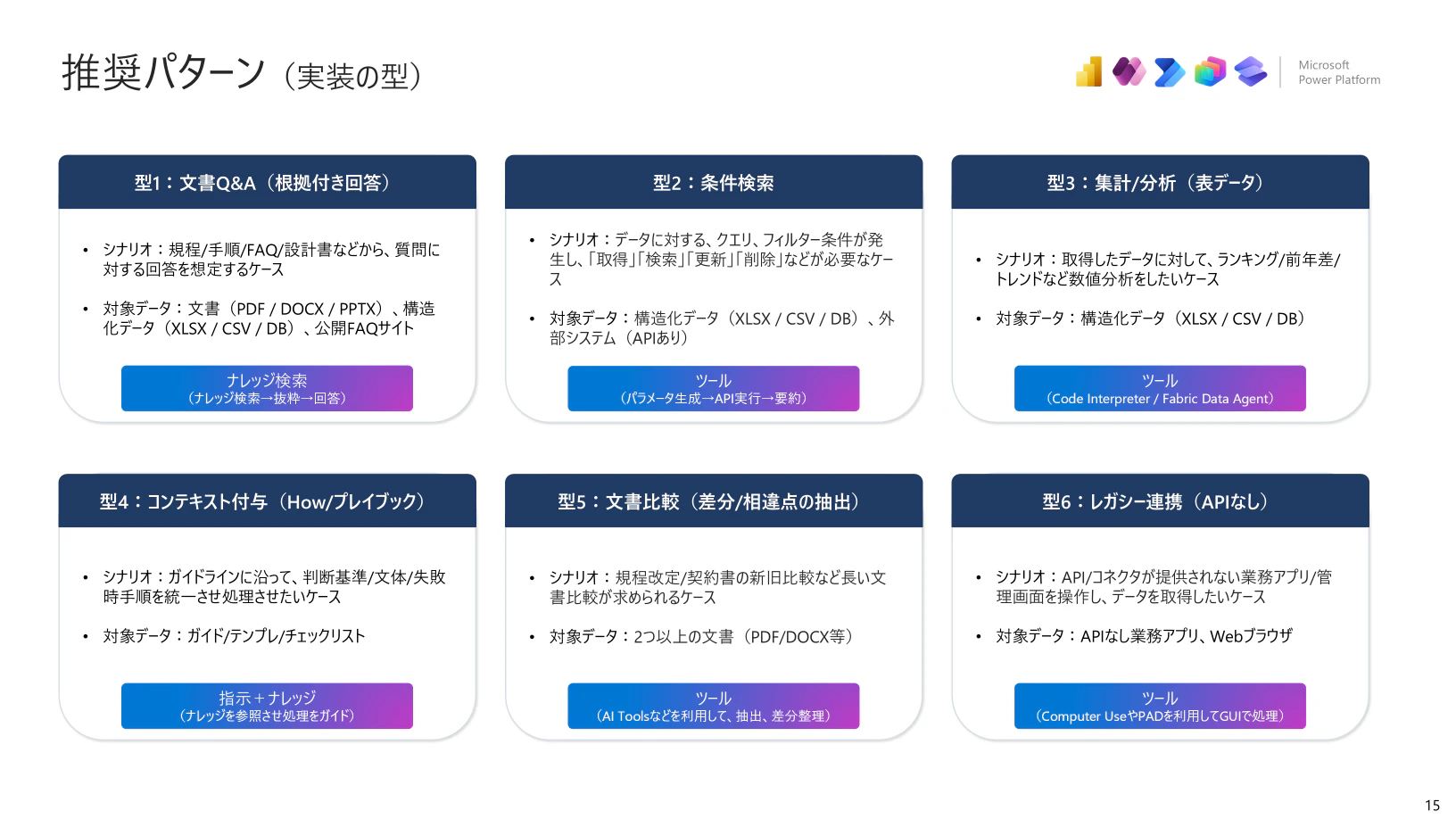
4. よくあるユースケース x アプローチ
細部の話をしていきましたが、これまで説明してきた内容をユースケースから逆引きしてアプローチを導きたいと思います。
これらはもちろん単独で実装されるものではなく、必要に応じて組み合わせて実装するものになります。
おわり
お持ちのデータに対しての実装アプローチをまとめてみました。
進化の早い製品でございますし、正解は1つでないと思いますので、あくまで参考までに役に立てば幸いです!
本記事を踏まえると以下のブログが腹落ちするかもしれませんので、併せてお読みください