Swaggerとは
- 公式サイト
- 概要
プロジェクト概要
ウェブサービスを利用。
フロントエンドとバックエンドでプロジェクトを分離している。
バックエンドはこんな構成。
フロントエンドはReact-Redux。
開発メンバーは3~5人程度で、全員バックエンドもフロントエンドも触る。
プロジェクト構成
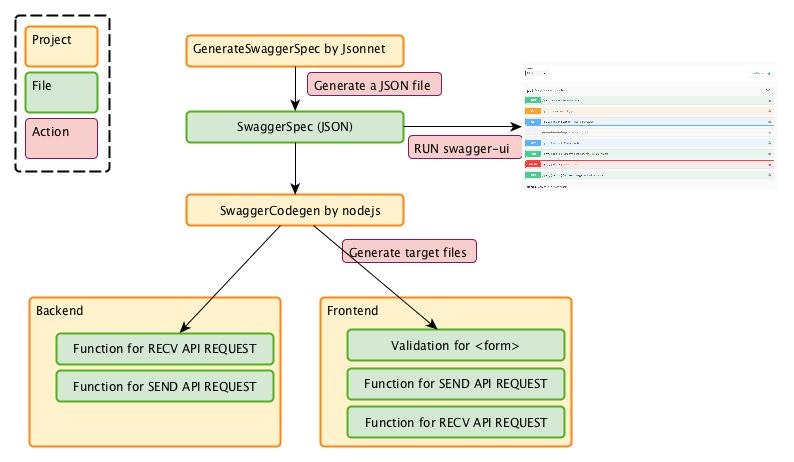
以下の4つのプロジェクトとして構成した。
- バックエンド
- フロントエンド
- SwaggerSpecのGenerator + SwaggerUI起動
- SwaggerCodeGenのカスタマイズ
利用した外部プロジェクト
Jsonnet
Googleが開発元のJSONを操作するDSL。
k8sの多環境設定などにも用いる。
よい紹介記事があるので、詳しくはそこで。
Jsonnetの薦め
使い方としては、以下のように利用している。
- 各エンドポイントごとにファイルを分ける
- Request/Responseなど共通定義できるものはテンプレートファイルを作り、利用する
- すべてのファイルを集めて定義するファイルを作る
メリット
- リソースごとに分けて定義できるので、可読性が高い
- テンプレートの関数をつくることができるので変更に強い
- 複数人での運用に向いている
デメリット
- 個々のファイルに分けるのでSwagger Editorは使えない
- DSLに慣れるまでの時間
- JSer,Rubyistであれば感覚で行けるレベル
swagger-js-codegen
個人が開発しているJSでのswagger codegen。
もともとSwaggerがJavaでできているのでコンパイルが必要などの手間がかかる。
これであればnodejsだけで済むので、環境構築が容易。またJSで記述できるので、フロントエンドメインの人でも変更できる。
メリット
- 環境構築が容易
- 出力ファイルの設定は本家と同じくmustacheなので必要となれば移植できる
デメリット
- 公式ではない
Swagger-Codegenで生成するファイル
フロントエンド
- Request定義用ファイル
- endpoint/HTTP Methodごとに関数を定義
- APIへデータを送る前に関数を呼び出しチェックを行う
- 必須項目/型/文字数/ファイルサイズなどをチェック
- validation用ファイル
- GET以外の際に関数を定義
- フォーム入力時に利用する
- Redux-Formのvalidate時に呼び出す
- Response確認用ファイル
- Responseに対し必須項目/型/文字数をチェック
- バックエンド側でもチェックするので重要度は低い
バックエンド
バックエンドはSwaggerを導入する前に作りきってしまったので、構造を変更する必要があり、実際の導入には至っていない。。
- Requestチェックファイル
- endpoint/HTTP Methodごとに関数を定義
- Response定義ファイル
- Responseの型などをチェック
その他、自分の環境を汚したくない場合のコマンド
JsonnetをDocker経由で実行
$ docker pull sparkprime/jsonnet
$ docker run -it -v /path/to/project:/app \
--rm sparkprime/jsonnet \
/app/aggregate.jsonnet \
-o /path/to/output.json
swagger-uiサーバをDocker経由で立てる
$ docker pull swaggerapi/swagger-ui
$ docker run -p 8080:8080 \
-e SWAGGER_JSON=/app/output.json \
-v /path/to/output.json:/app/output.json \
swaggerapi/swagger-ui
http://localhost:8080 でアクセス。
まとめ
当然だが出力するファイルは冪等性を保つ必要があり、出力ファイルを直接編集してはいけない。
その前提でフロント/バックエンドとも設計していれば、開発において非常に有効。
ここで用いている言語/技術は学習曲線が低く、どれも導入しやすいものなので、試してみる価値はある。
知見が欲しい人はご連絡ください。