アンサンブル学習とは?
-
複数の学習器を組み合わせ、より良い予測を得ようとするテクニック。単一のモデルを単独で使うよりも大抵の場合良い結果が得られる。
-
具体的には、複数の予測器の予測値の**「平均値をとる」、もしくは「多数決をとる」**などの処理で組み合わせる。
-
近年、データ分析の現場で注目されている**「ブースティング」「ランダムフォレスト」**などもアンサンブル学習の一種。
バギング
「複数の学習器(予測器)を組み合わせる」と言っても、同じデータを使って同じアルゴリズムで学習を行ったモデルを組み合わせても意味はない。
とは言え、普通データは1つしか存在しない。
そこれ、**「ブーストラップ」**と呼ばれるテクニックを使う。
- ブーストラップ…訓練データからランダムに(重複ありで)n個のデータをサンプリングする。
訓練データから大きさnのブーストラップデータ集合をN個生成する。
それらのデータを用いてN個の予測モデルを作ると、それぞれの予測値は、yn(x)となる。
よって、バギングを使ったモデルの最終的な予測値は次のようになる。
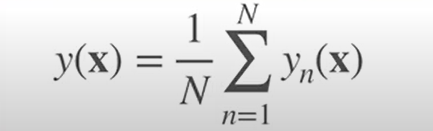
スタッキング
先程のバギングは、N個の予測値の単純平均を考えた。つまり、ここの予測値を平等に評価しており、それぞれのモデルの重要度を考慮できていない。
- スタッキングは、個々の予測値の加重平均を最終的な予測値とし、モデルごとの重要度を考慮する。
よって、最終的な予測値は、
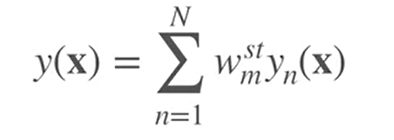
パンピング
-
パンピングは、複数の予測器の中から最も当てはまりの良いモデルを探すための手法。
-
ブーストラップデータ集合を使ってN個のモデルを生成し、それらをもとの訓練データに当てはめ、予測誤差を最小にするモデルを最良のモデルとして選ぶ。
-
バギング,スタッキングに比べ、一見メリットの無いような手法だが、質の悪いデータを用いて望ましくない解が得られてしまったとき、それらのデータを除いたブーストラップデータ集合によって、より良い解が得られることがある。
ランダムフォレスト
-ランダムフォレストは、前述の「バギング」のベース学習器として「決定木」を用いた手法。具体的なアルゴリズムは以下の通り、
①訓練データからN個のブーストラップデータ集合を取り出す。
②これらのデータを使ってN個の木Tnを生成する。
- このときp個の特徴量からm個だけをランダムに選ぶ。
③回帰の場合は平均を、分類の場合は多数決を取って最終的な予測値とする。
なぜベース学習器に決定木を用いるのか?
- バギングの基本的な考え方は、分散大・バイアス小のモデルを複数組み合わせて誤差を減らすこと。
①分散大・バイアス小 → 複雑なモデル(決定木,最近傍法)
②分散小・バイアス大 → 単純なモデル(線形回帰)
-
決定木は、バギングのベース学習器としては理想的な分散大・バイアス小のモデル**(過学習を複数のモデルの平均とることで修正できる。)**
-
その他、「高速である」、「変数のデータ型を問わない」、「スケーリングに対して不変」などのメリットがある。
なぜ一部の特徴量だけしか使わないのか?
- アンサンブル学習においては、モデル間の相関が低ければ低いほど最終的な予測値の精度は高まる。
→同じようなモデルをいくつも集めても意味はなく、異なったデータで学習したモデルを組み合わせたほうが性能が高い。
- ブーストラップに加え、それぞれのモデルで学習に使う変数を変えることでモデル間の相関を低くする。
ブースティングとは?
-「ブースティング」は、アンサンブル学習の手法の1つ。
-
ベース学習器を逐次的に訓練する。(前の学習器に基づいて次の学習器を生成)
バギングやスタッキングなどの手法は、複数のベース学習器を最終的に組み合わせて予測値を出す。(前後の学習器に関係性はない) -
**「AdaBoost」と「勾配ブースティング」**と呼ばれる2つの手法が代表的。
-
Kaggleでかなり人気な**「Xgboost」**というライブラリが実現するアルゴリズム。
AdaBoost(アダブースト)
- 各学習器の訓練で、重みづけられたデータ集合が利用される。
- 前の学習器が誤分類したデータ点により大きな重みを与える。
- 最初は全てに均等な重みを与える。
- それらのベース学習器の予測値を最後に結合して最終的な予測値とする。
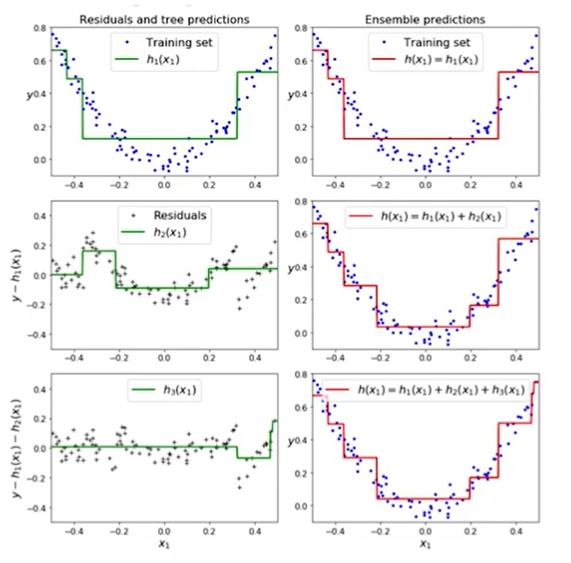
勾配ブースティングとは?
- 前の学習器の**「残差」**に適合する。
- ベース学習器としては、「決定木」がよく用いられる。
- xgboostによって実装されているアルゴリズム
実験①
import numpy as np
import matplotlib.pyplot as plt
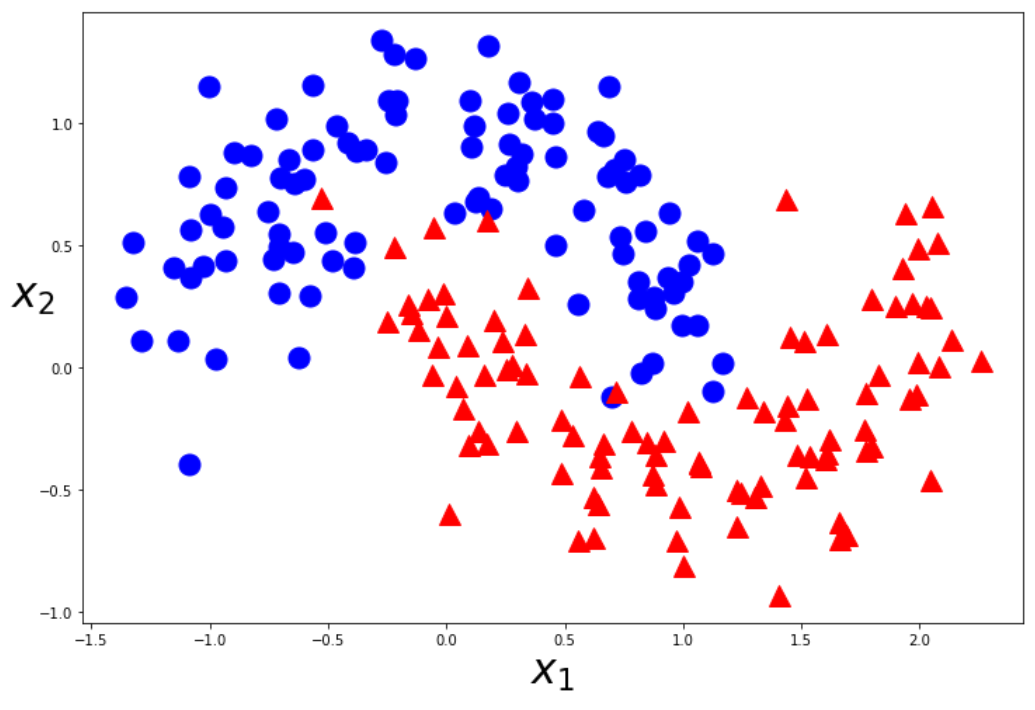
from sklearn.datasets import make_moons
moons=make_moons(n_samples=200,noise=0.2,random_state=0)
X=moons[0]
y=moons[1]
from matplotlib.colors import ListedColormap
def plot_decision_boundary(model,X,y):
_x1 = np.linspace(X[:,0].min()-0.5,X[:,0].max()+0.5,100)
_x2 = np.linspace(X[:,1].min()-0.5,X[:,1].max()+0.5,100)
x1,x2 = np.meshgrid(_x1,_x2)
X_new=np.c_[x1.ravel(),x2.ravel()]
y_pred=model.predict(X_new).reshape(x1.shape)
custom_cmap=ListedColormap(["mediumblue","orangered"])
plt.contourf(x1,x2,y_pred,cmap=custom_cmap,alpha=0.3)
def plot_dataset(X,y):
plt.plot(X[:,0][y==0],X[:,1][y==0],"bo",ms=15)
plt.plot(X[:,0][y==1],X[:,1][y==1],"r^",ms=15)
plt.xlabel("$x_1$",fontsize=30)
plt.ylabel("$x_2$",fontsize=30,rotation=0)
plt.figure(figsize=(12,8))
plot_dataset(X,y)
plt.show()
決定木分析
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier #(scikit-learn で決定木分析 (CART法))
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0)
tree_clf=DecisionTreeClassifier().fit(X_train,y_train) #default上限なし
plt.figure(figsize=(12,8))
plot_decision_boundary(tree_clf,X,y)
plot_dataset(X,y)
plt.show()
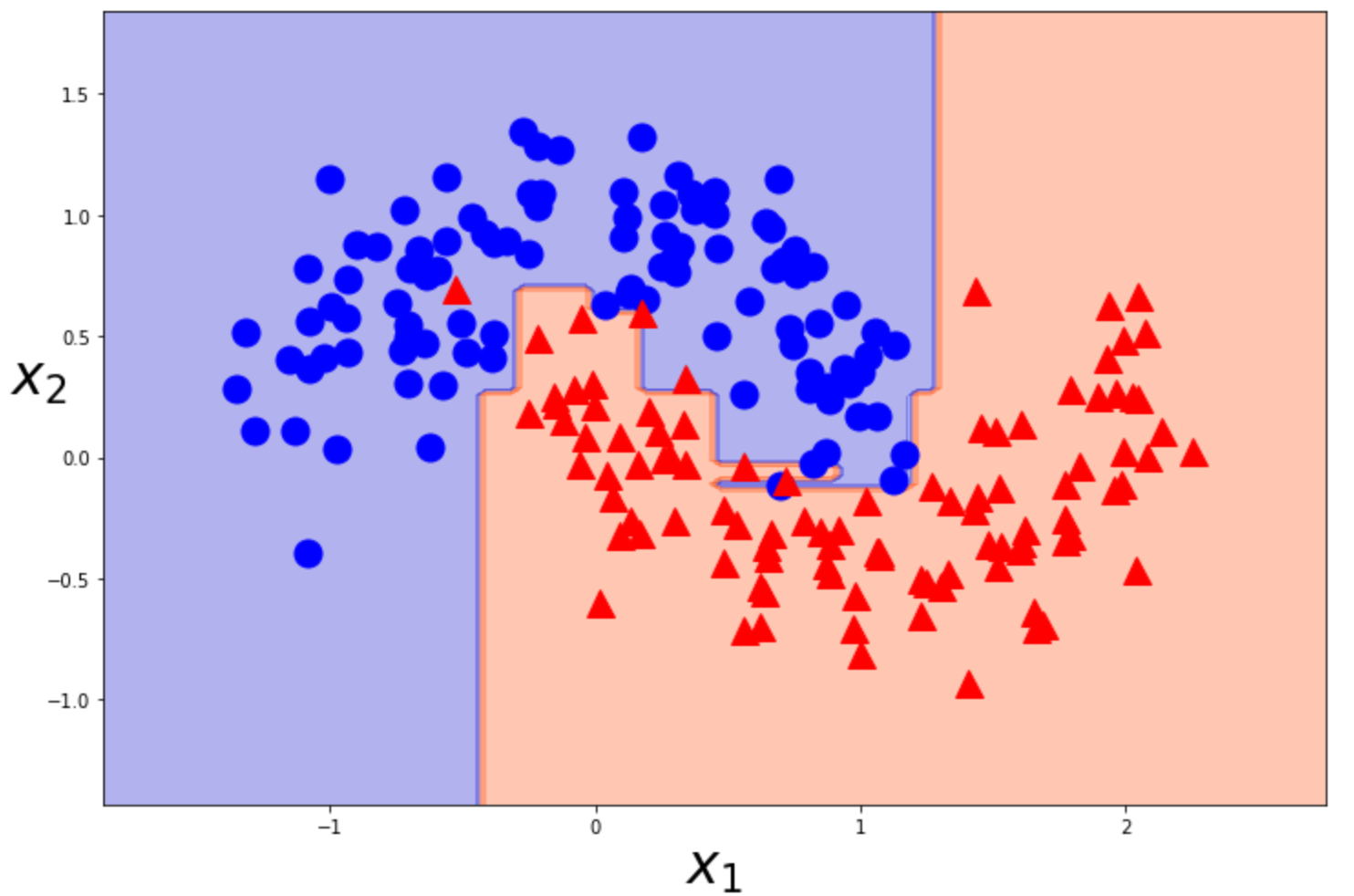
ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
random_forest=RandomForestClassifier(n_estimators=100,random_state=0).fit(X_train,y_train)
# デフォルトの値は10.バギングに用いる決定木の個数を指定.
plt.figure(figsize=(12,8))
plot_decision_boundary(random_forest,X,y)
plot_dataset(X,y)
plt.show()
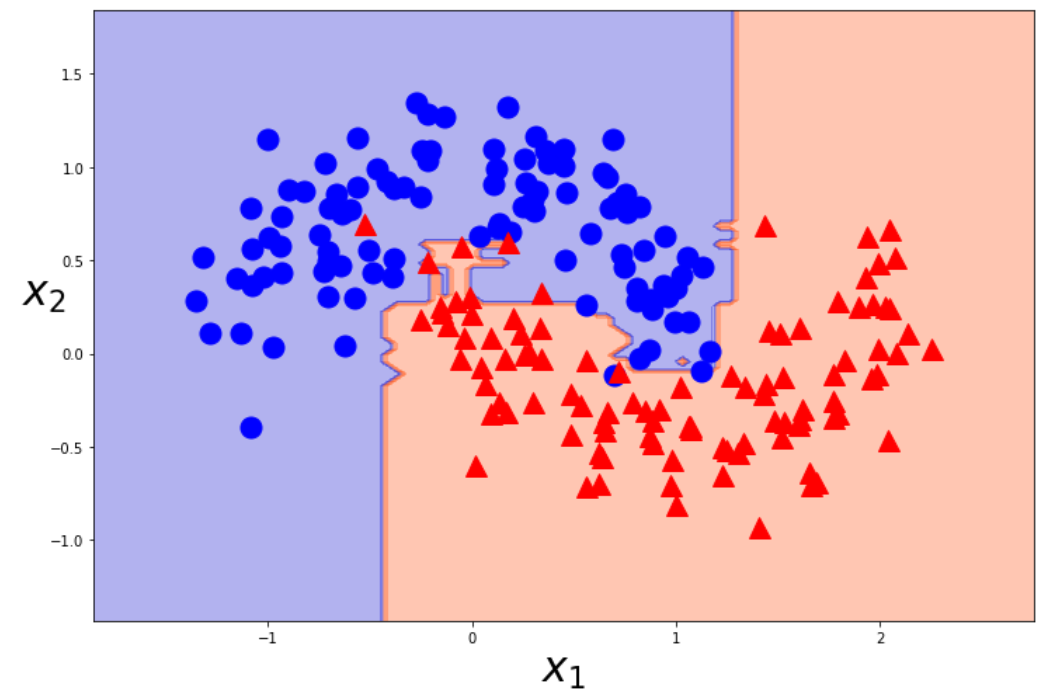
実験②
from sklearn.datasets import load_iris
iris=load_iris()
X_iris=iris.data
y_iris=iris.target
random_forest_iris=RandomForestClassifier(random_state=0).fit(X_iris,y_iris)
# それぞれの特徴量がどれだけ重要度をもっているか
random_forest_iris.feature_importances_
plt.figure(figsize=(12,8))
plt.barh(range(iris.data.shape[1]),random_forest_iris.feature_importances_,height=0.5)
plt.yticks(range(iris.data.shape[1]),iris.feature_names,fontsize=20)
plt.xlabel("Feature importance",fontsize=30)
plt.show()
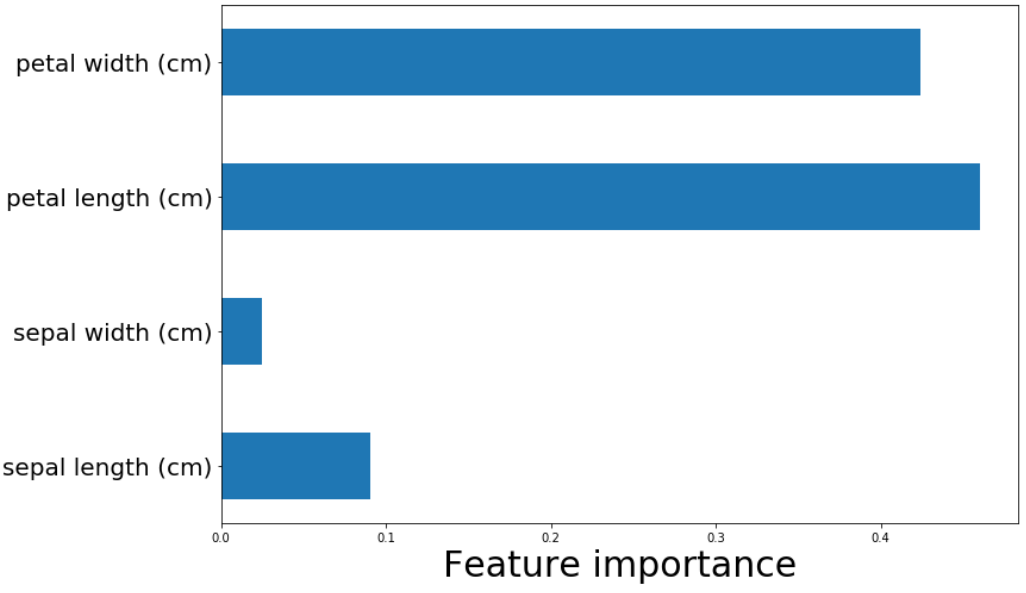
実験③
データセットはkaggleのタイタニック号を利用しました。
https://www.kaggle.com/c/titanic
import pandas as pd
df=pd.read_csv("train.csv")
df["Age"]=df["Age"].fillna(df["Age"].mean())
df["Embarked"]=df["Embarked"].fillna(df["Embarked"].mode()[0])#最頻値
from sklearn.preprocessing import LabelEncoder
cat_features=["Sex","Embarked"]
for col in cat_features:
lbl = LabelEncoder()
df[col]=lbl.fit_transform(list(df[col].values))
X=df.drop(columns=["PassengerId","Survived","Name","Ticket","Cabin"])
y=df["Survived"]
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0)
tree=DecisionTreeClassifier().fit(X_train,y_train)
print(tree.score(X_test,y_test))
rnd_forest=RandomForestClassifier(n_estimators=500,max_depth=5,random_state=0).fit(X_train,y_train)
print(rnd_forest.score(X_test,y_test))

提出形(submisson.csvとして出力)
# 提出形
test_df=pd.read_csv("test.csv")
test_df["Age"]=test_df["Age"].fillna(test_df["Age"].mean())
test_df["Fare"]=test_df["Fare"].fillna(test_df["Fare"].mean())
test_df["Embarked"]=test_df["Embarked"].fillna(test_df["Embarked"].mode()[0])#最頻値
for col in cat_features:
lbl = LabelEncoder()
test_df[col]=lbl.fit_transform(list(test_df[col].values))
X_pred=test_df.drop(columns=["PassengerId","Name","Ticket","Cabin"])
ID=test_df["PassengerId"]
prediction=rnd_forest.predict(X_pred)
submisson=pd.DataFrame({
"PassengerId":ID,
"Survived":prediction
})
submisson.to_csv("submisson.csv",index=False)