データ収集(icrawlerで効率よく簡単に!)
# 日向坂メンバーリストを作成する!(いちいち書くのは面倒くさいので、スクレイピングしました!)
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import time
brower = webdriver.Chrome(ChromeDriverManager().install())
brower.get("https://www.hinatazaka46.com/s/official/search/artist?ima=0000")
# 「brower.find_element_by_class_name」ではなく、「brower.find_elements_by_class_name」にして複数のクラスを取得することに注意!
menber_names = brower.find_elements_by_class_name("c-member__name")
menber_names_list = []
for menber_name in menber_names:
#メンバーの名前以外にも空白が含まれてたので、余計な空白を削除するため条件設定
if len(menber_name.text) >= 2:
menber_names_list.append(menber_name.text)
import os# …①(ファイルやディレクトリの存在確認・指定したパスのファイル名の取得・パスやファイル名の結合)
import glob# …②(引数に指定されたパターンにマッチするファイルパス名を"全て"取得)
import random# …③(引数に指定されたリストからランダムで複数の要素を取得)
import shutil# …④(ファイル・ディレクトリを移動する)
from icrawler.builtin import GoogleImageCrawler# …⑤(Google画像検索からデータを収集するためのモジュール)
# 画像を保存するルートディレクトリパス
root_dir = 'hinatazaka46_images/'
# 収集画像データ数
data_count = 100
def crawl_image(hinatazaka_name, datacount, root_dir):
crawler = GoogleImageCrawler(storage={'root_dir':root_dir + hinatazaka_name + '/train'})
# (画像を保村するフォルダを指定)
filters = dict(
size='large',
type='photo'
)
#
# クローリングの実行
crawler.crawl(
keyword=hinatazaka_name, #検索ワード
filters=filters, #画像の検索条件
max_num=datacount #収集したい最大画像枚数
)
# 前回実行時のtestディレクトリが存在する場合、ファイルをすべて削除する
if os.path.isdir(root_dir + hinatazaka_name + '/test'):
shutil.rmtree(root_dir + hinatazaka_name + '/test')
os.makedirs(root_dir + hinatazaka_name + '/test')
# ダウンロードファイルをリストとして、全て取得
filelist = glob.glob(root_dir + hinatazaka_name + '/train/*')
# ダウンロード数の2割をtestデータとして抽出
test_ratio = 0.2
testfiles = random.sample(filelist, int(len(filelist) * test_ratio))
for testfile in testfiles:
shutil.move(testfile, root_dir + hinatazaka_name + '/test/')
# 日向坂メンバーの人数分だけクローリングを実行
for hinatazaka_name in menber_names_list:
crawl_image(hinatazaka_name, data_count, root_dir)

上図のようにフォルダも自動的に作成されました!
モデル構築
Microsoft Azureの画像認識サービスである**"Custom Vision Service"**を利用して簡単に作成します!
リソースグループの作成
**"新規"**をクリック!
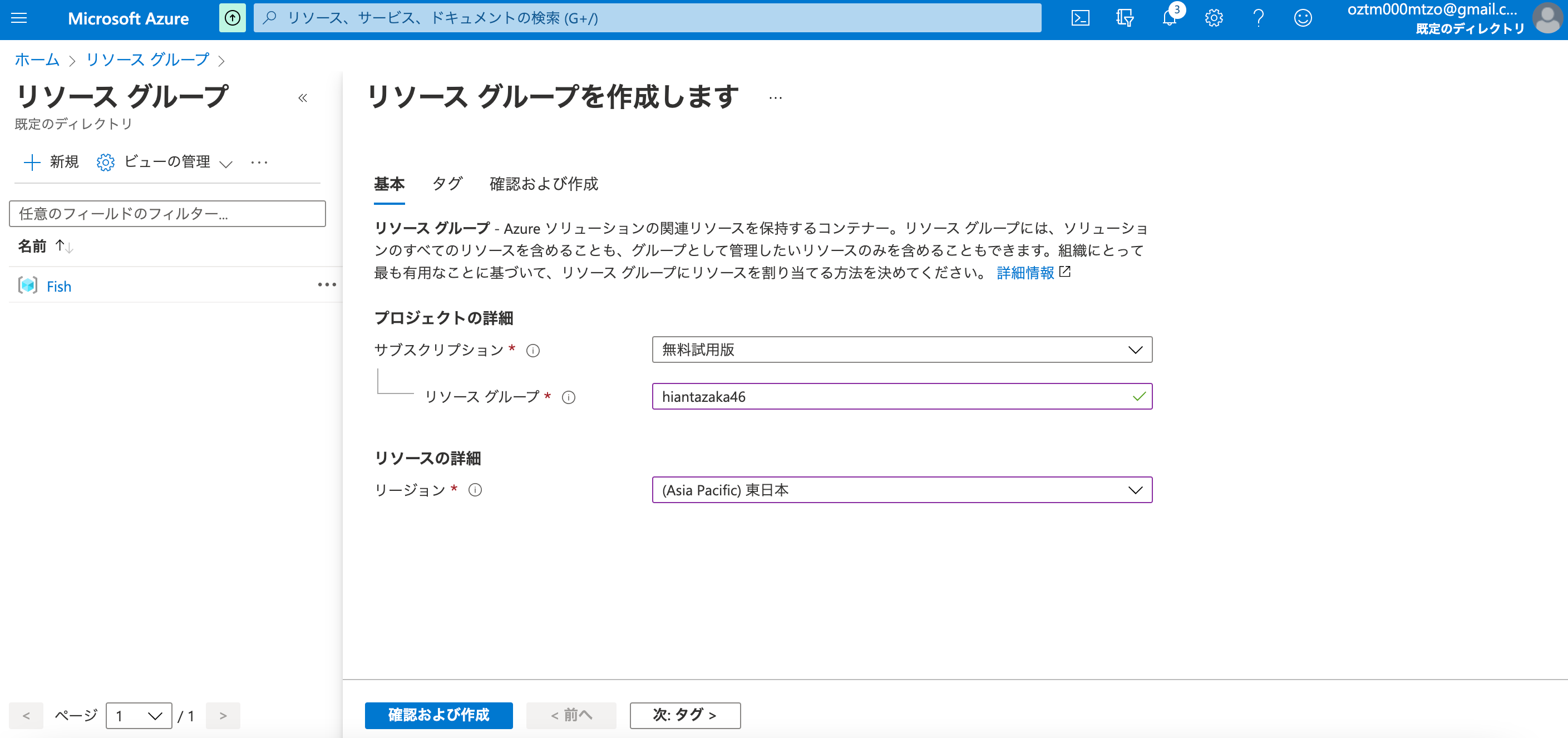
・サブスクリプション:"無料使用版"
・リソース グループ:"hiantazaka46"
・リージョン:"(Asia Pacific)東日本"
リソースの作成!
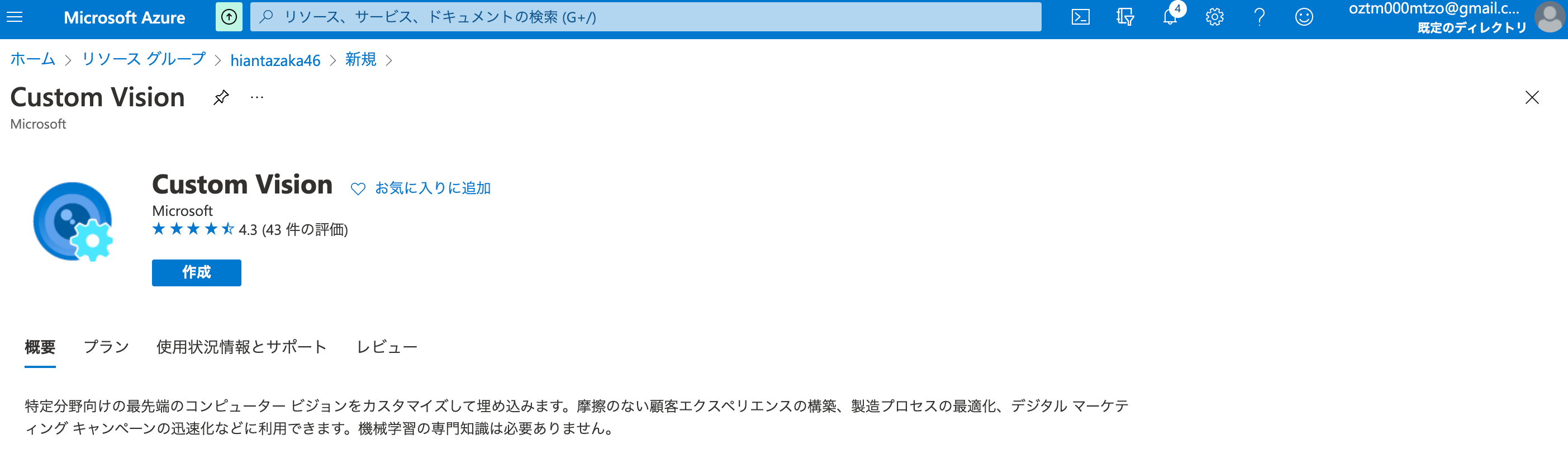
Custom Visionを選択して、**"Custom Visionリソース"**を作成する!
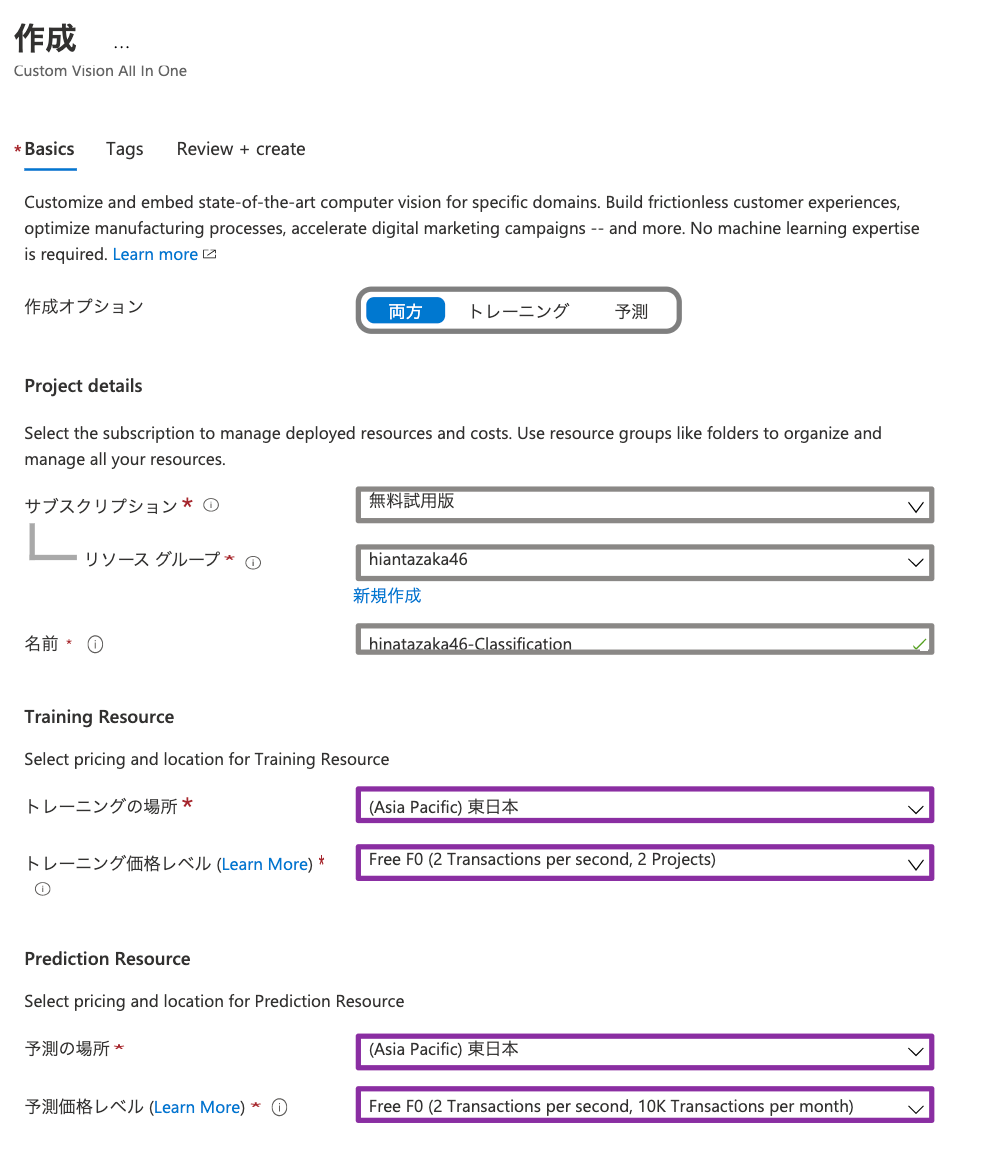
上記のurlにアクセスして、**"モデル構築用のプロジェクト"**を作成する!
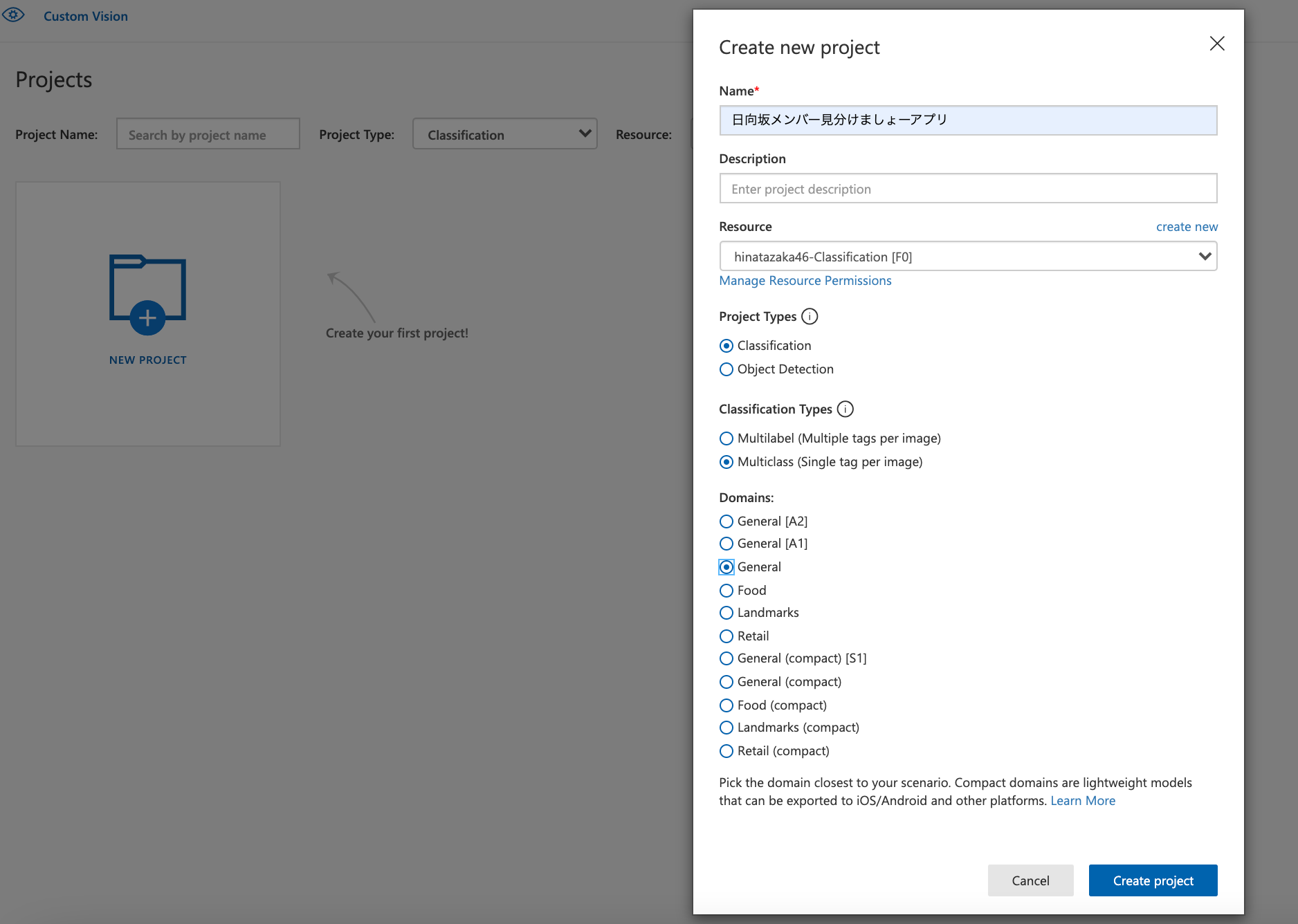
その後、訓練データをラベルごとに貼り付けて、**"Train"**を開始する!
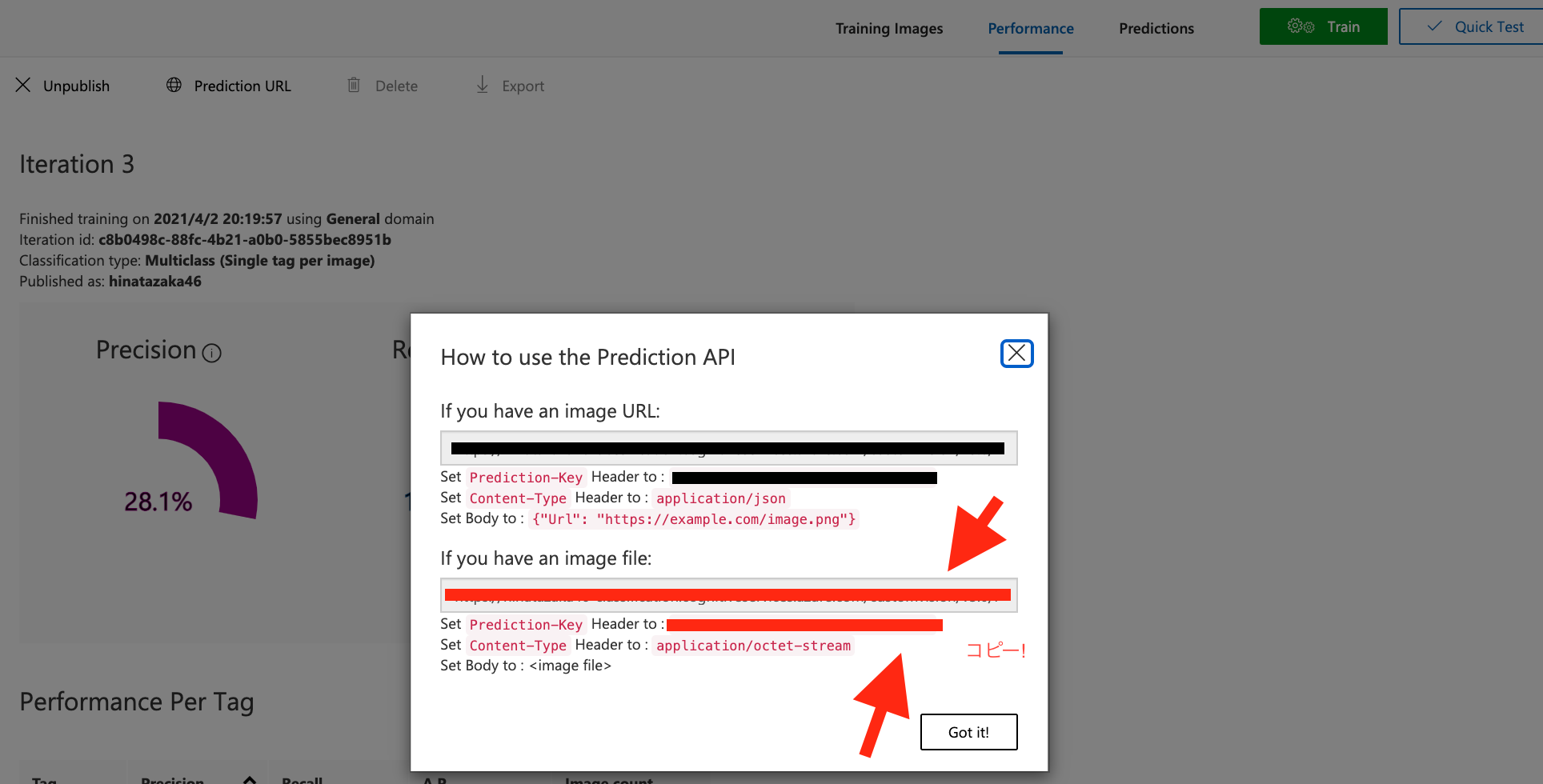
そして、**"Performance"の"Prediction URL"**からAPIを利用するのに必要な情報をコピーする!(赤線の2つ!)
API利用
import glob
import requests
import json
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
# 各自で取得(赤線の部分をそれぞれペースト)
base_url = '??????????????????'
prediction_key = '?????????????????????'
root_dir = 'hinatazaka46_images/'
# 検証対象のメンバ一覧
for member in menber_names_list:
testfiles = glob.glob(root_dir + member + '/test/*')
data_count = len(testfiles)
true_count = 0
for testfile in testfiles:
headers = {
'Content-Type': 'application/json',
'Prediction-Key': prediction_key
}
params = {}
predicts = {}
data = open(testfile, 'rb').read()
response = requests.post(base_url, headers=headers, params=params, data=data)
results = json.loads(response.text)
try:
# 予測結果のタグの数だけループ
for prediction in results['predictions']:
# 予測した魚とその確率を紐づけて格納
predicts[prediction['tagName']] = prediction['probability']
# 一番確率の高い魚を予測結果として選択
prediction_result = max(predicts, key=predicts.get)
# 予測結果が合っていれば正解数を増やす
if fishname == prediction_result:
true_count += 1
#画像サイズ > 6MB だとCustom Vision の制限にひっかりエラーが出るまで握り潰し
except KeyError:
data_count -= 1
continue
# 正解率の算出
print("true_count:",true_count,"data_count:",data_count)
accuracy = (true_count / data_count) * 100
print('メンバー名:' + fishname)
print('正解率:' + str(accuracy) + '%')

最後に
一応、Microsoft Azureの画像認識サービス(Azure Custom Vision)が提供する**"API"**を利用して、日向坂メンバーの顔認識分析ができました。
今回初めてこのAPIを利用してみて、"ノンプログラミングでモデル構築が行えること"・**"モデル構築が速い"**といったメリットを肌で感じました!
反省点として、予測精度がそこまで高くないことが挙げられます。
この改善点としては、"データ数の拡大"、**"写真の顔の部分のみを抽出"**をすることで予測精度がより高くなるのではないかと思いました!!
またね!!!!!!!!!
参考文献
①**"import os"**について
②**"import glob"**について
③**"import random"**について
④**"import shutil"**について
⑤**"import GoogleImageCrawler"**について