はじめに
とりあえず、CDPzを利用してSYSLOGをElasticsearchに取り込むところまで確認できました。
ただ、製品提供のものをそのまま使うだけではなく、より扱いやすくするために、一部カスタマイズを加えてみます。また、Elasticsearchに取り込まれた情報をKibanaでどのように扱えるのかをもう少し具体的に探ってみます。
関連記事
CDPzを利用したz/OS-ELK連携 - (1)セットアップ編
CDPzを利用したz/OS-ELK連携 - (2)SYSLOG取得編
CDPzを利用したz/OS-ELK連携 - (3)SMF-バッチ編
CDPzを利用したz/OS-ELK連携 - (4)SMF-リアルタイム編
CDPzを利用したz/OS-ELK連携 - (5)カスタマイズ-共通
CDPzを利用したz/OS-ELK連携 - (6)カスタマイズ-SYSLOG
CDPzを利用したz/OS-ELK連携 - (7)カスタマイズ-CICS
CDPzを利用したz/OS-ELK連携 - (8)カスタマイズ-RMF Monitor III
CDPzを利用したz/OS-ELK連携 - (9)カスタマイズ-fluentdの利用
データ取り込みのカスタマイズ
フィールドの型の対応
Elasticsearch側にフィールドの型を定義していないと、Elasticsearchにデータを投入する際にLogstashで以下のようなエラーが発生することがあります。
[WARN ] 2020-01-30 15:49:11.988 [[main]>worker1] elasticsearch - Could not index event to Elasticsearch. {:status=>400, :action=>["index", {:_id=>nil, :_index=>"cdp-zos-syslog-console-eplex-20200130", :routing=>nil, :_type=>"_doc"}, #<LogStash::Event:0x3d55233c>], :response=>{"index"=>{"_index"=>"cdp-zos-syslog-console-eplex-20200130", "_type"=>"_doc", "_id"=>"Hio19W8BNTmHFHNB9lgP", "status"=>400, "error"=>{"type"=>"mapper_parsing_exception", "reason"=>"failed to parse field [ROUTECODE] of type [long] in document with id 'Hio19W8BNTmHFHNB9lgP'. Preview of field's value: '40000000000000000000000000000000'", "caused_by"=>{"type"=>"illegal_argument_exception", "reason"=>"Value [40000000000000000000000000000000] is out of range for a long"}}}}}
Elasticsearch側に、以下のようにindex templateを作成し、明示的に型の定義をしておきます。
PUT _template/cdp_syslog_cust
{
"index_patterns": ["cdp-zos-syslog-console-*"],
"order" : 1,
"mappings": {
"properties": {
"rcd": {
"type": "keyword"
},
"ASID": {
"type": "keyword"
},
"SMFID": {
"type": "keyword"
},
"JOBNUM": {
"type": "keyword"
},
"CONSOLE": {
"type": "keyword"
},
"ROUTECODE": {
"type": "keyword"
},
"DESCRIPTOR": {
"type": "keyword"
},
"JOBNAME": {
"type": "keyword"
},
"FLAGS": {
"type": "keyword"
},
"TEXT": {
"type": "text"
}
}
}
}
結果
メッセージIDのハンドリング
ミドルウェアが出力するメッセージなどは、メッセージID + メッセージ本体というような形式のテキストが入っていることが多いと思います。このメッセージIDの部分を別フィールドとして抽出することを考えます。また、メッセージIDの先頭3桁を見ると大体何のコンポーネントが出しているメッセージかわかるので、先頭3文字部分をカテゴリとして別フィールドとして追加したいと思います。
そのために、メッセージIDを正規表現で表して条件に合致するものをメッセージIDフィールドとして識別させることにします。
以下、Logstashでの設定例です。
MSGID_MVS [A-Z]{3,7}[0-9]{3,5}[ADEISTW]?
MSGID_JES2 \$HASP[0-9]{3,4}
MSGID (%{MSGID_MVS}|%{MSGID_JES2})
MSGCATEGORY .{3,3}
TEXT_PATTERN01 [ ]*[+]?(%{MSGID:MSGID}[ ]+%{GREEDYDATA:TEXT}|%{GREEDYDATA:TEXT})
filter {
if [sourceType] == "zOS-SYSLOG-Console" {
mutate{ add_field => {
"[@metadata][timestamp]" => "%{TIMESTAMP}"
}}
date{ match => [
"[@metadata][timestamp]", "yyD HH.mm.ss.SSS Z"
]}
grok{
patterns_dir => ["/etc/logstash/config_syslog02/patterns.d"]
match => {"TEXT"=>"%{TEXT_PATTERN01}"}
overwrite => "TEXT"
}
grok{
match => {"MSGID"=>"^(?<MSGCATEGORY>.{3,3})"}
}
}
}
これで、MSGID, MSGCATEGORYというフィールドが追加されます。
Kibana操作
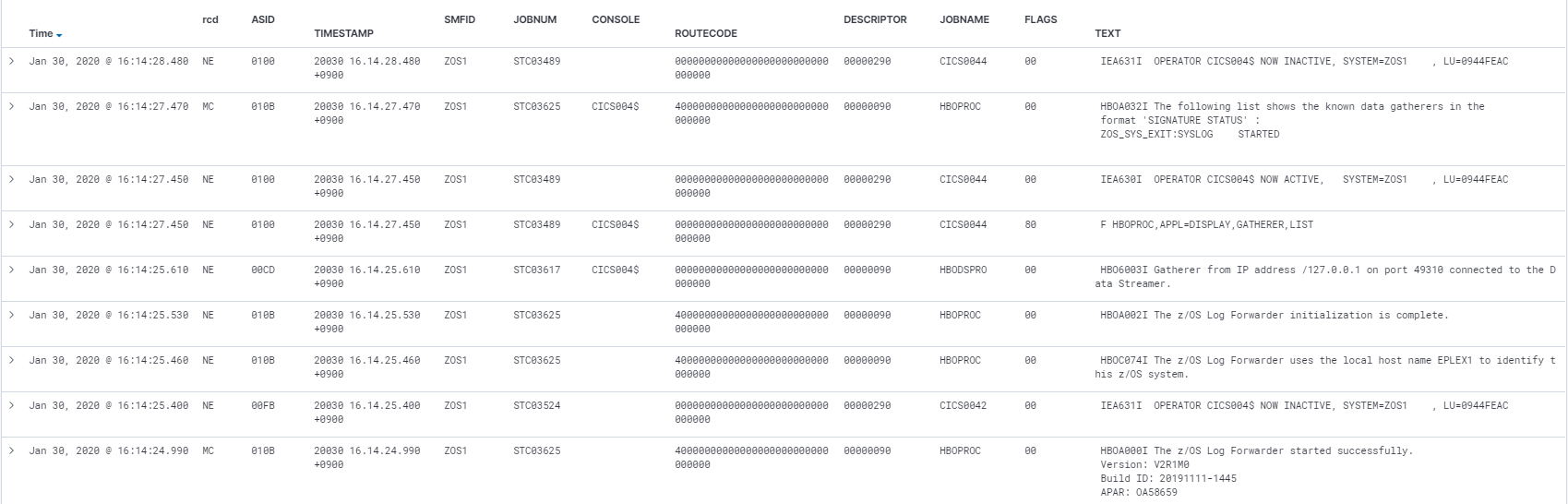
Discover
Discoverの画面例です。

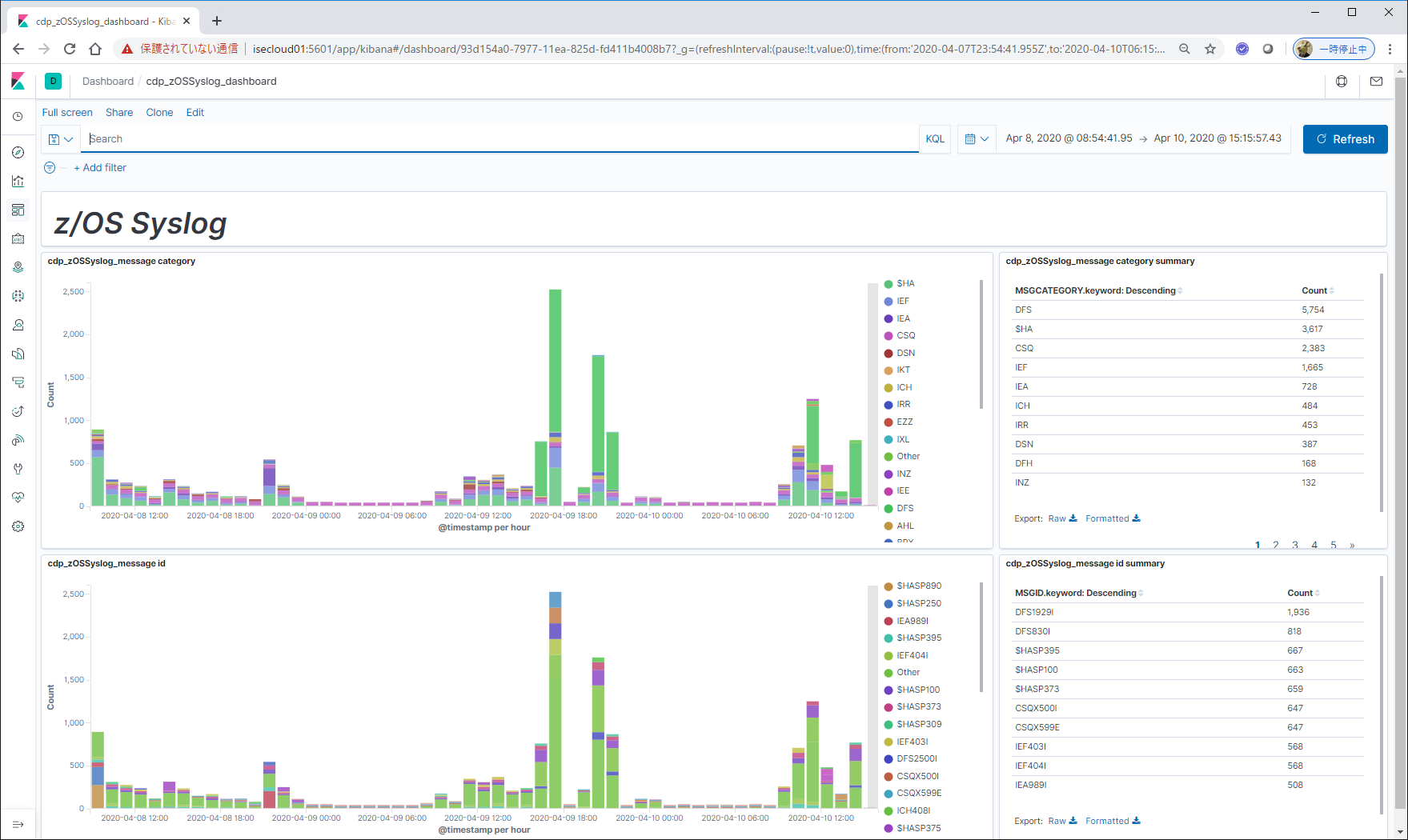
集計/グラフ化
MSGCATEGORYやMSGID単位での集計が行えます。