Local LLMと形態素解析で構築する、完全自律型X(Twitter)自動投稿パイプラインのアーキテクチャ
はじめに
日常の断片的な思考を元として、ローカル環境で稼働するLLMがテキストを生成し、X(Twitter)へ自動投稿するシステムを構築しました。
単なる「AIにテキストを書かせるBot」ではなく、LLM特有のループ発作や特定語彙への依存を、形態素解析を用いた自作のバリデータで検知・排除し、デッドロック時にはテキストを解体・再構築するフォールバック層まで備えた、自己完結型のデータパイプラインを設計しています。
こちらでは、その5層からなるシステムアーキテクチャの全体像を解説します。
システム構成と5つのパイプライン
1. 外部データの収集・咀嚼(インプット層)
ユーザーが登録する思考リストの単語をトリガーに、外部検索を実行してシードとなるテキストを収集します。
- 技術要素: DuckDuckGo API, SQLite
- 処理内容: DuckDuckGo APIへリクエストを送信し、取得したWeb上のテキストから、LLMが「美学や質感の強いフレーズ」を自律的に抽出・サニタイズしてデータベース(SQLite)へ蓄積します。

2. 異質な文脈の衝突と生成(推論層)
収集したワード群をベースに、ローカルLLM(Gemma 3 12B)に140文字の情景テキストを生成させます。ここでは確率によって3つのプロンプト・ルーティングを行っています。
- 異常値 (Low) / 15%: temp=0.2 の低温度設定による、硬質で残酷なシステムログ調の出力。
- 異常値 (Drama) / 15%: 名もなき人物たちの記憶やセリフが交錯する退廃ドラマモード。
- 通常 (High) / 70%: 無機物や熱力学の概念が意思を持って脈動する擬人化・インダストリアルモード。
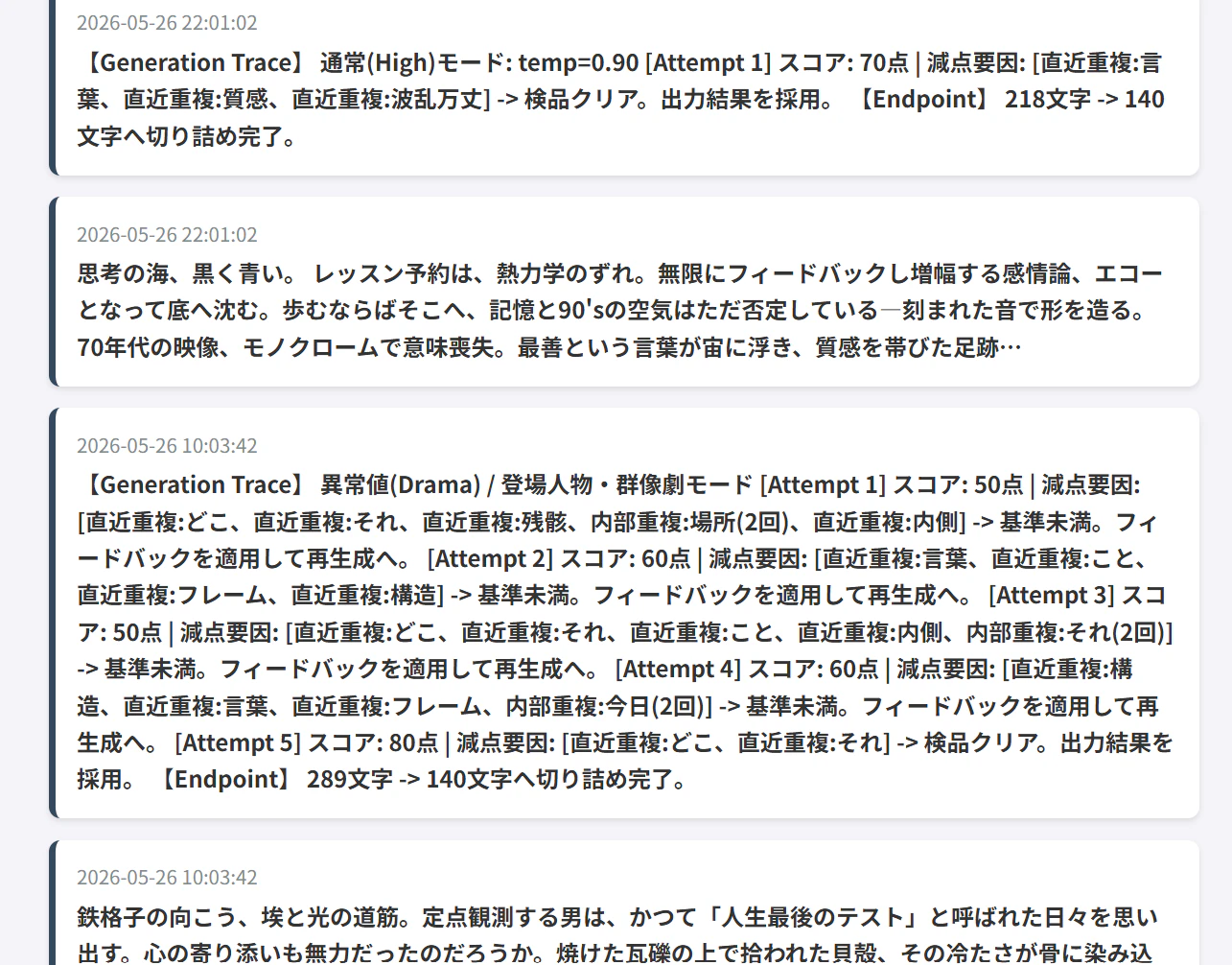
3. バリデーション(検品層)
AIの「お気に入りワード(筐体、回路、ログ等)」への過剰な依存を防ぐための検品機構です。
- 技術要素: Python, Janome(形態素解析)
-
動的NGワード生成: 過去約3日分(
LIMIT 5)の投稿ログから重要名詞を抽出し、一時的なNGワードとして指定。 - 例外処理のチューニング: 「〜のよう」といった比喩表現は2回まで許容し、3回以上出現した場合はリジェクトする厳密なカウント制御を実装。
- フィードバックループ: スコア60点以下の減点判定を受けた場合、該当ワードをプロンプトで排除指定し、最大5回まで再推論(リトライ)を実行させます。
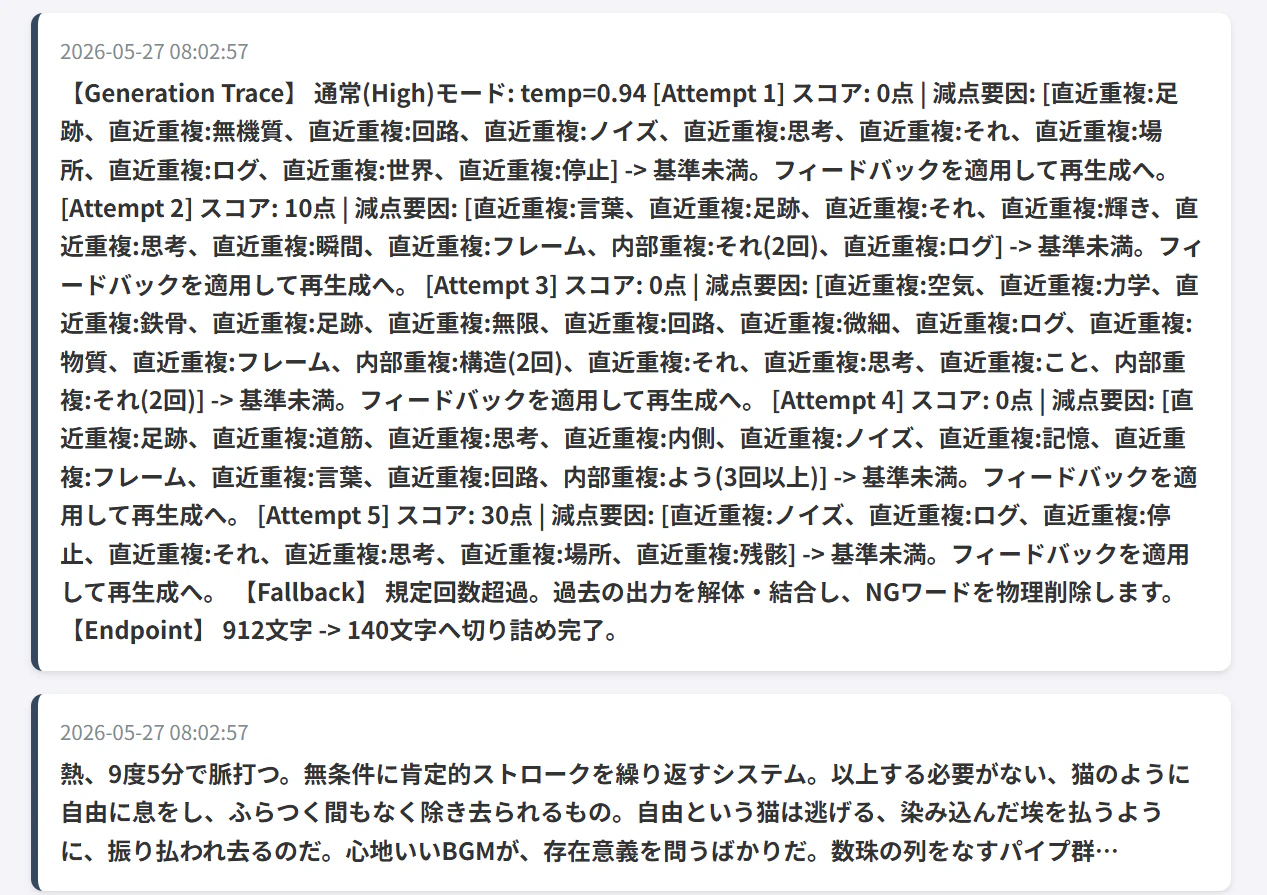
4. デッドロックの回避と着地(フォールバック層)
5回リトライしても検品を通過できなかった場合のセーフティネットです。システムのクラッシュを防ぎ、確実にエンドポイントへデータを渡します。
- キメラ結合: 失敗した5回分のテキストを文単位(文章のパーツ)に解体し、ランダムにシャッフルして再結合。
-
物理削除: 結合後のテキストから、正規表現を用いてNGワードや重複キーワードを物理的に除去。
5. 外部へのアウトプット(エンドポイント)
完成したテキストをX(Twitter)へパブリッシュします。
- 技術要素: X API
- 処理内容: テキストを140文字の制限に合わせて正確に切り詰め(オーバーフロー分は「…」へフェードアウト処理)、API経由で完全自動での投稿を実行します。
おわりに
私の思い付きの言葉を派生元にして、「検索し、LLMで歪ませ、自作のバリデータで検品し、ダメなら解体してキメラ合体させてとりあえず出力する」という一連のサイクルを自動化しました。
単にプロンプトを投げるだけでなく、推論結果をシステム的に監視・統制することで、自律的な運用が可能になっています。
リンク
リポジトリ
https://github.com/tomoro999/word-spreader
Xアカウント
https://x.com/t_a_r_o_u_99