概要
http://insideairbnb.com/get-the-data.html から取得した、
2019年分の東京のデータをpandasを使って見てみた。
listings.csv というデータを使っていてarchiveされているものも使っています。
経緯
Amsterdamに泊まりたい人のためにAirbnbのデータを分析したから という記事で、
Airbnbのデータが公開されていることを知ったので、上記の記事とは違うcsvを使ってみました。
どういったデータなのか
airbnbに登録されている東京の物件のデータです。
https://min-paku.biz/glossary/listing を見ると、
利用者が予約をするのに参考にする情報みたいですね。
データは以下の感じで、部屋のタイプや金額、最低宿泊数などが載っています。
-
データの形
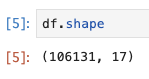
-
カラム名
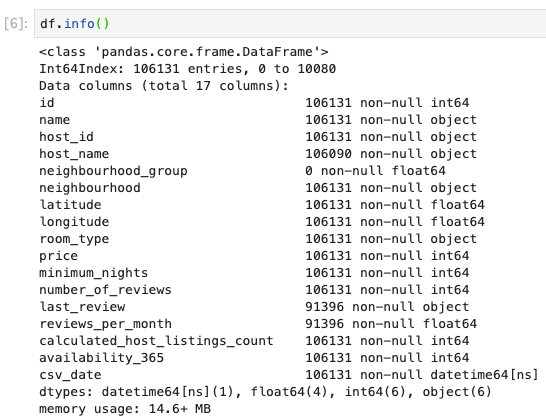
準備
- import
import pandas as pd
from matplotlib import pyplot as plt
import japanize_matplotlib
import seaborn as sns
import glob
%matplotlib inline
-
CSVの用意
1ファイルが一ヶ月分であるCSVをnotebookと同じディレクトリにあるdataというフォルダに
入れます。 -
CSVの読み込みとデータの整形
CSVが複数あるのであったので以下の方法でぐぐっと読み込みます。
ファイル名がlistings_2019-03-25.csvという感じなので、
年月日の部分をデータフレームにも入れていつのデータなのかが、分かるようにします。
csv_list = glob.glob("./data/*.csv") # 指定したパスのCSVのファイル名をリストの形で取得する。
df = pd.DataFrame()
for i in csv_list:
tmp_date = i.split("_")[1].split(".")[0] # _を区切りとして分割して1個めのデータを抜き出してそれをさらに.で分割して0個目のデータを変数に入れる。
tmp_df = pd.read_csv(i)
tmp_df["csv_date"] = tmp_date
df = pd.concat((df, tmp_df) ) #
df["csv_date"] = pd.to_datetime(df["csv_date"])
df["host_id"] = df["host_id"].astype("str")
価格帯とlistings数の分布
sns.scatterplot(x="price", y="calculated_host_listings_count",
data=df, hue="room_type", size="room_type")
plt.legend(bbox_to_anchor=(1.4, 0.5))
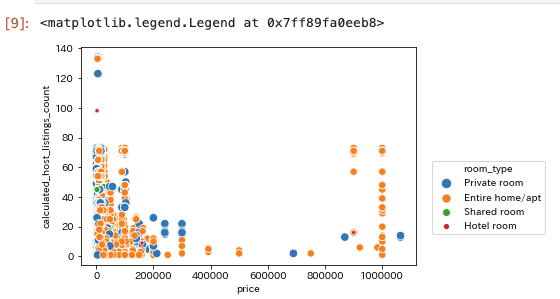
なんかぶっ飛んだ価格帯の物件がありますが、価格とlistings数の間には特に関係は無さそう。
月毎のレコード件数の可視化
df2 = df.groupby(["csv_date"], as_index=False)["id"].count() # csv_date の列の値でレコードをまとめてレコード数をカウントする。
df2.rename(columns={"id": "レコード件数"}, inplace=True) # columnの名前をrenameする。
sns.barplot(x=df2["csv_date"].dt.month, y="レコード件数", data=df2)
plt.title("2019年の月別レコード件数")
plt.xlabel("month")
plt.xticks(rotation=90)
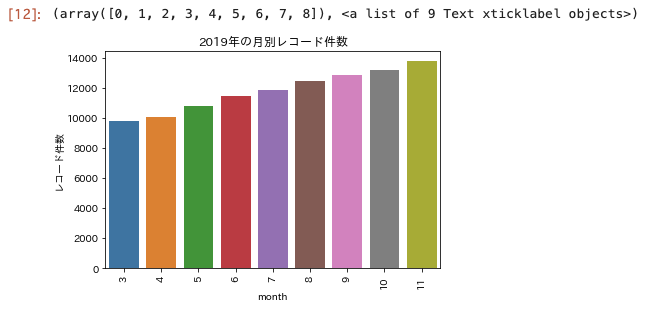
年末になるにつれて件数が増えていっている。
この辺は calendar.csv も取得して合わせてみるとなんか分かるかも?
どういった部屋が増えているのかを可視化する
# csv_dateとroom_typeの列でグループ化して必要な列だけ抜き出す。
df3 = df.groupby(["csv_date", "room_type"], as_index=False)\
.count().iloc[:, :3]\
.rename(columns={"id": "レコード件数"})
# room_type別で可視化
sns.barplot(x=df3["csv_date"].dt.month, y="レコード件数", data=df3, hue="room_type")
# legendがグラフの中に描画されて見にくいのでグラフの外に出す。
plt.legend(bbox_to_anchor=(1,1))
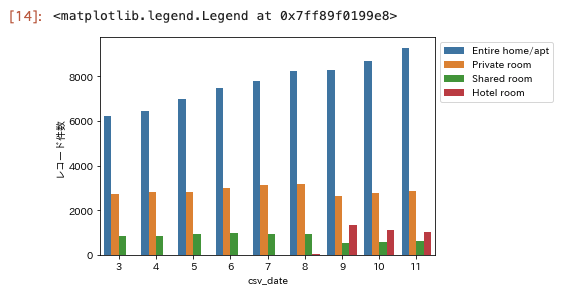
9月頃から急に、hotelというタイプのいかにも高そうな物件が出現しているが、
Entire home/aptといった1軒まるごと貸し出すようなものがムクムク伸びている。
意外と個室というは一定なのね。
部屋のタイプごとの金額を調べてみる
# 部屋のタイプごとにdescribeを描画する。
for i in df["room_type"].unique():
print("describe is ", i)
print(df.query("room_type == @i")["price"].describe().apply(lambda x: format(x, ".1f")))
print("---")
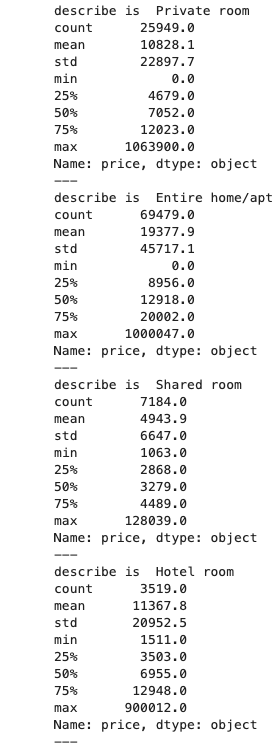
maxの値を見ると、どの部屋のタイプにもぶっ飛んだ価格が設定されている物件がある。
なので、どの部屋のタイプもカバーできそうな75%を超えるくらいの30,000を上限にしてさらに可視化してみる。
plt.figure(figsize=(10,10))
plt.ylim(0, 30000)
sns.boxplot(x="room_type", y="price", data=df)
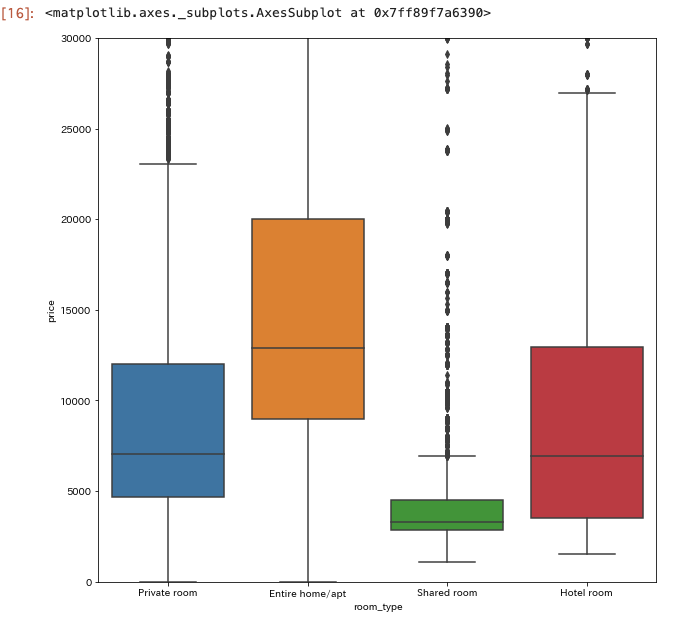
sharedがやっぱり単価が低いけど、上述の統計量からみてcount数はprivateとentireと比べてまさに桁が違うので、
薄利多売ということもできなそうなのでしんどそう。
hotelよりもentire home/apt の方が価格帯が上っぽい。
room_type が Entire home/apt を調べる
何となく一番儲かりそうな感じがするので。
価格の分布
sns.catplot(y="price", data=only_entire_homeapt_df, kind="strip")
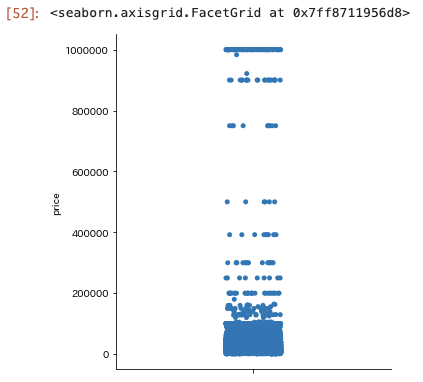
これまでの調べからも分かっていたとおり、ぶっ飛んだ価格帯があるが殆どは200,000円もいかない物件。
価格をbinningしてみる
bins_series = pd.cut(only_entire_homeapt_df["price"],
bins=[-1, 3000, 6000, 10000, 20000,
30000, 50000, 100000, 1100000])
sns.countplot(bins_series)
plt.xticks(rotation=90)
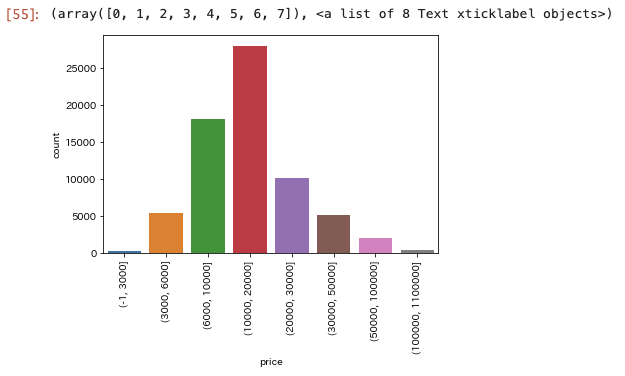
6000を超えるところから20,000未満がボリュームゾーンっぽい。
中でも、10,000を超えて20,000未満が多い感じ。
各物件の部屋数とかが分かると部屋の数に比して割安感のある価格を提示するとかできそう。
可用性
たぶん、宿泊できるとして家主が設定している日数はどの程度なのかという値だと思われる、
availability_365 を調べてみる。
only_entire_homeapt_df["availability_365"].describe()
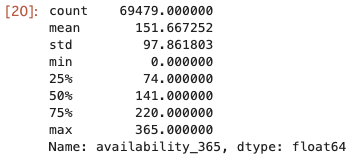
中央値が141なので、30(日)*5(ヶ月) = 150 って感じで考えると、
半年未満の物件もそこそこあるみたい。
最低宿泊数を見てみる
only_entire_homeapt_df["minimum_nights"].describe()

sns.countplot(x="minimum_nights", data=only_entire_homeapt_df.query("minimum_nights < 40"))
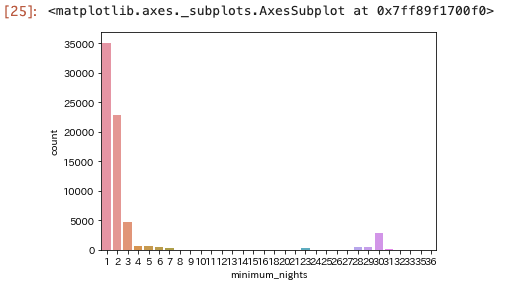
この辺は競争的に不利になる制約だと思うので、一泊がほとんど。
(全体の何%がそうなのかは気になったけど見てない。)
金額と可用性と最低宿泊数とcalculated_host_listings_count の関係
sns.pairplot(only_entire_homeapt_df[["price", "availability_365", "minimum_nights", "calculated_host_listings_count"]])
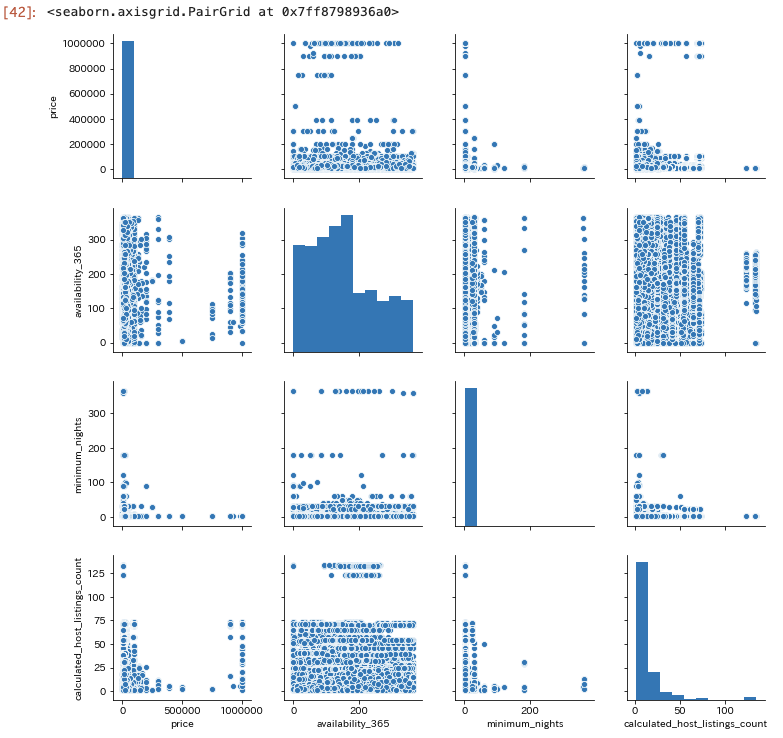
特に相関はなさそう。
まとめ
これだと自分が物件を出すとしてどの程度の部屋をいくらで出せばいいのかというは、
判断つかないので、calendar.csv も合わせて見てみたい!
その2はこちら。
https://qiita.com/txt_only/items/11625bc1c209f1f1d171