概要
k8sと比べてcomposeが使えるなら比較的すすっと使えるDockerSwarmを
一から構築して、rolling updateやrollback, managerを全部落としてみるとかしつつ、
nginx,fastapi,postgresqlのコンテンを作って、nginxとfastapiはHAProxyを介してサービスを公開する。
前提
- 全部さくらのクラウド上に作成する
- インスタンスのOSは全部 Ubuntu 20.04.3 LTS
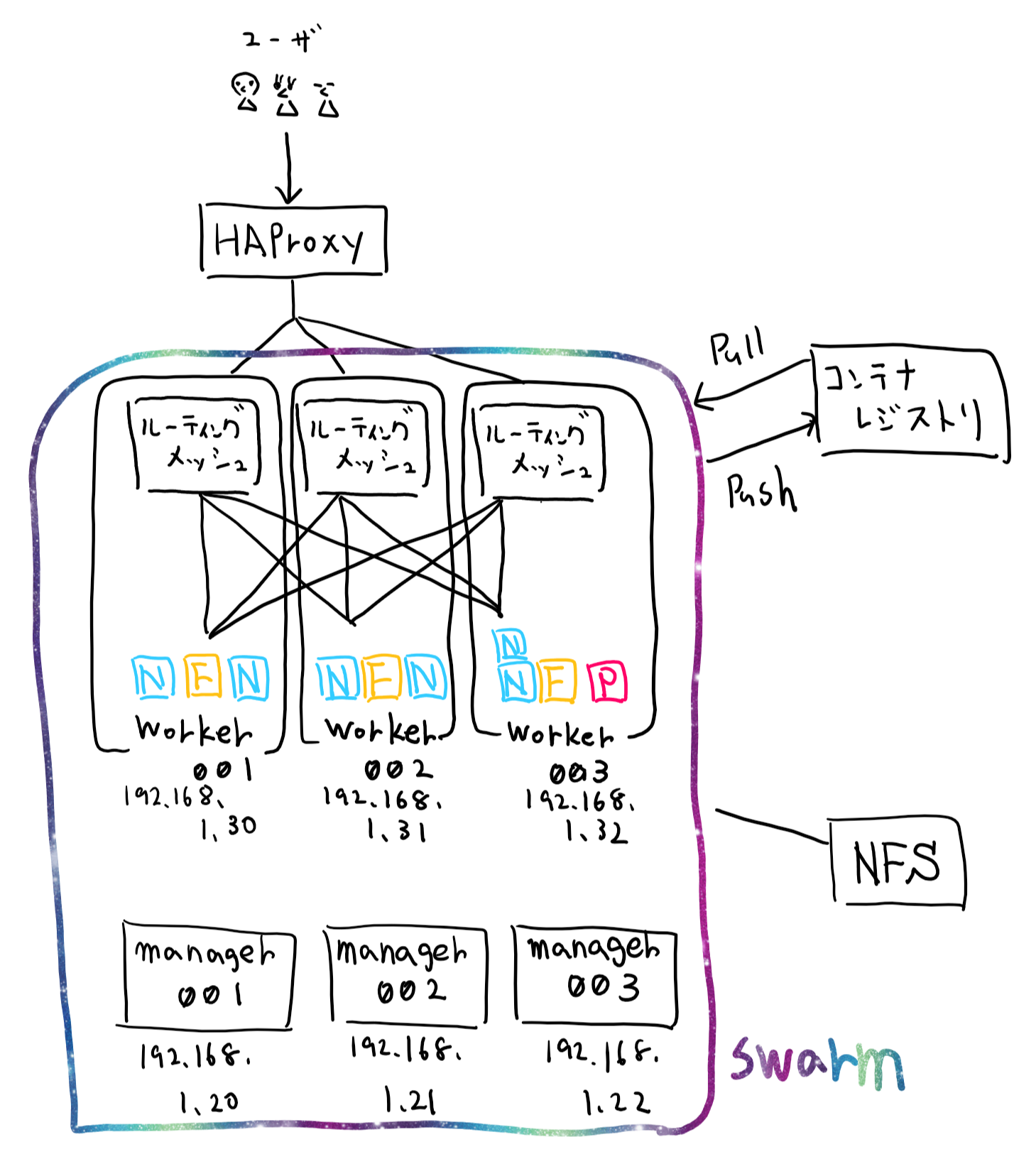
- managerは3台
- IPは192.168.1.20 - 22
- workerは3台
- IPは192.168.1.30 - 32
- HAProxyは1台
- IPは192.168.1.40
- コンテナレジストリはさくらのクラウドのLabプロダクトを使う
- postgresqlのデータの永続化はさくらのクラウドのNFSアプライアンスを使う
- たくさんインスタンスを作るのでお金がぼちぼちかかるから始めたらさっさと終わらせるつもりでがんばる。
2Hくらいで終わらせれば166円くらいで済むはず。
8Hくらいかかったとしても代官山でランチするより安いはず。
構成
大体こんなイメージ。ややこしいのでインスタンスを接続するスイッチは省いている。
Nはnginx, Fはfastapi, Pはpostgresqlのコンテナを表している。
準備
インスタンスを結ぶスイッチを作る
公式のスイッチのドキュメント に沿ってコントロールパネルからクリッククリックして1つ作る。
1Hあたり11円、1日あたり110円、一ヶ月あたり2200円かかる。
インスタンスを作る
一番小さいサイズのインスタンスを7台(manager用3台,worker用3台,HAProxy用1台)作る。
名前やホスト名で何用なのかを分かるようにしておく。
1Hあたり9円、1日あたり100円、一ヶ月あたり1991円 が1インスタンスづつにかかる。
接続先スイッチは前項で作ったスイッチでOKOK。
さくらインターネットが用意しているスタートアップスクリプトで
最新のDockerがインストールされるスクリプトをインスタンス作成時に選択しておくと楽。
インスタンスが出来上がったらmanager用とworker用のインスタンスで以下のコマンドを実行する。
sudo apt update && sudo apt upgrade -y && sudo apt install vim nfs-common -y && sudo apt autoremove -y && sudo reboot
NFSアプライアンスを作る
公式のNFSのドキュメントに沿って、クリッククリックして1つ作る。
IPは 192.168.1.200 にしておく。
1Hあたり9円、1日あたり99円、一ヶ月あたり1980円かかる。
作ったら、作ったインスタンスのどれでもいいので以下のコマンドを実行しておく。
sudo mount -o rw 192.168.1.200:/export /mnt
sudo mkdir /mnt/for_postgres
sudo umount /mnt
コンテナレジストリを使えるようにする
ただで使える。公式のコンテナレジストリのドキュメントを見てレジストリとユーザを作る。
イメージを作ってコンテナレジストリにpushする。
ここは飛ばしても良い。飛ばす場合は後述するyamlからfastapiに関する記述を消す必要がある。
manager用のインスタンスの内1つで以下を実行する。
docker login [コンテナレジストリ名]
Username: [ユーザ名]
Password: [パスワード]
git clone git@github.com:tomokitamaki/fastapi_train.git
docker image build コンテナレジストリ名.sakuracr.jp/fastapi:test
docker push コンテナレジストリ名.sakuracr.jp/fastapi:test
managerでdocker loginしておけば、その情報はworkerにも伝わるので、
workerでコンテナレジストリからイメージをpullする事が出来る。
swarmを使ってクラスターを作る。
1台目のmanagerを作る
manager用のインスタンで以下を実行する。
docker swarm init --advertise-addr <MANAGER-IP>
e.g.
docker swarm init --advertise-addr 192.168.1.20
docker swarm join --token SWMTKN-1-3prk6vb2jv39rkiop~b1vpnb5 192.168.1.20:2377 的な出力がされたと思うのでそれをコピーしておく。
workerを作る
worker用の各インスタンスでコピーしておいたコマンドを実行する。
実行し終わったら、swarm init を実行したインスタンスで docker node ls を実行してworkerが3台表示されるか確認する。
managerを増やす
managerのインスタンスで docker swarm join-token manager を実行する。
tokenとコマンドが表示されるので、他のmanager用のインスタンスにてそれを実行する。
実行後はmanagerのインスタンスで docker node lsをして確認するとヨイヨイ。
概ね以下みたいな表示になるはず。
ubuntu@swarm-manager00:~$ sudo docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
ymr0r30c15xg41dkx7blidc2l * swarm-manager00 Ready Drain Reachable 20.10.8
knytfmppymxsct77c6g2jbpuk swarm-manager01 Ready Drain Leader 20.10.8
b1da2gb38b9ywgimedzr2m1dh swarm-manager02 Ready Drain Reachable 20.10.8
va7h6hmqvkpx7hl19c3cciaom worker001 Ready Active 20.10.8
xkjuhu7ocql4v3dmdazh8fozq worker002 Ready Active 20.10.8
9cl6nrlbcn64u1fx7ifjj35ox worker003 Ready Active 20.10.8
ubuntu@swarm-manager00:~$
managerにコンテナが配置されないようにする。
以下のコマンドを実行する。
実行後、managerのインスタンスにて docker node lsを実行すると該当のnodeのAVAILABILITYがDrainになっている。
docker node update --availability drain ノード名
e.g.
docker node update --availability drain swarm-manager01
コンテナを配置する(no use yaml)
以下を実行する。
sudo docker service create --replicas コンテナ数 --name サービス名 イメージ名
e.g.
sudo docker service create --replicas 2 --name nginxs nginx:1.20
nginxのコンテナが2つ配置されているはずなので以下のコマンドで確認する。
以下の出力からはworker003とworker001に配置されている事が分かる。
ubuntu@swarm-manager00:~$ docker service ps nginxs
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
6w5a9opoo09g nginxs.1 nginx:1.20 worker003 Running Running 43 seconds ago
evwbrw8mnuyt nginxs.2 nginx:1.20 worker001 Running Running 42 seconds ago
ubuntu@swarm-manager00:~$
ただ、ポートを公開していないのでnginxのあの画面の表示することは出来ない。
ポートを公開する
この状態でポートを公開する設定を追加することも出来るが、
一旦サービスを削除して再作成する時に合わせてポートを公開する。
以下のコマンドを実行する。
# サービスを削除する
docker service rm nginxs
# ホストの80番ポートでコンテナの80番ポートを公開する。
docker service create --replicas 2 --name nginxs --publish published=80,target=80 nginx:1.20
# サービスを確認。80番で公開されていることが分かる。
docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ge74e7yfrnlw nginxs replicated 2/2 nginx:1.20 *:80->80/tcp
# コンテナが稼働しているノードを確認する
docker service ps nginxs
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
xcujvw9697k9 nginxs.1 nginx:1.20 worker001 Running Running 22 seconds ago
tna62bax4xhb nginxs.2 nginx:1.20 worker003 Running Running 22 seconds ago
ルーティングメッシュを感じる
worker001とworker003でnginxのコンテナが稼働しているようなので
worker001とworker002のホストにブラウザからアクセスしてみる。
http://worker001のホストのIP
http://worker002のホストのIP
両方のURLでnginxの画面が表示されたはず。worker001はいいとして、
コンテナが配置されていないworker002でも表示されたのはswarmが
よしなにコンテナが稼働しているホストにルーティングしてくれるルーティングメッシュが機能しているから。便利。
でもホストは増えたり減ったり落ちたりするため、
ユーザにホストへ直接アクセスしてもらうのはちょっといただけないので、
HAProxyを使ってうまくやる感じにする。(後で)
ちなみにルーティングメッシュをバイパスする様な設定もswarmで出来る。
コンテナをスケールさせる
以下のコマンドを実行することでスケールさせられる。
# 増やす
docker service scale nginxs=30
# 減らす
docker service scale nginxs=1
コンテナのイメージをアップデートする
以下のコマンドを実行してnginxのlatestのイメージにアップデートする。
この時よく見ると1コンテナづつアップデートされているのでrolling updateされていることが分かる。
# nginx:latest のイメージを使うようにアップデート
docker service update --image nginx:latest nginxs
# アップデートされているか確認する。1.20からlatestになっている!
docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ge74e7yfrnlw nginxs replicated 2/2 nginx:latest *:80->80/tcp
rollbackする
以下のコマンドを実行してrollbackする。
# rollbackする
docker service rollback nginxs
# rollbaskしているか確認する。1.20に戻っている!
docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ge74e7yfrnlw nginxs replicated 2/2 nginx:1.20 *:80->80/tcp
yamlからコンテナを配置する
以下のyamlをtest_stack.yaml というファイル名で作成する。
version: "3.8"
services:
postgre_db:
image: postgres
deploy:
mode: replicated
replicas: 1
placement:
constraints:
- "node.role == worker"
volumes:
- type: volume
source: postgres_volume
target: /var/lib/postgresql/data
environment:
POSTGRES_USER: root
POSTGRES_PASSWORD: root
POSTGRES_HOST_AUTH_METHOD: trust
ports:
- published: 5432
target: 5432
fastapi:
image: レジストリ名.sakuracr.jp/fastapi:test
deploy:
mode: replicated
replicas: 3
placement:
constraints:
- "node.role == worker"
ports:
- published: 8000
target: 8000
nginx:
image: nginx:1.20
ports:
- published: 80
target: 80
deploy:
mode: replicated
replicas: 10
placement:
constraints:
- "node.role == worker"
volumes:
postgres_volume:
driver: local
driver_opts:
type: "nfs"
o: "addr=192.168.1.200,intr,rw,nfsvers=4"
device: ":/export/mydata"
postgresqlのデータはvolumesで定義されている様に
NFSに保存されるようになっている。なのでpostgresのコンテナが
どのworkerで起動していてもデータは同じものを参照できる。
作ったら、以下のコマンドを実行する。
# yamlを元にコンテナを配置する
docker stack deploy stack01 -c test_stack.yaml
# 配置されていることを確認する
docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
jiyu680mx4oc stack01_fastapi replicated 3/3 xxxx.sakuracr.jp/fastapi:test *:8000->8000/tcp
zpsq264lmdi3 stack01_nginx replicated 10/10 nginx:1.20 *:80->80/tcp
hfrhn8q18vub stack01_postgre_db replicated 1/1 postgres:latest *:5432->5432/tcp
配置されていれば、以下のURLにブラウザからアクセスするとngixの画面やfastapiのopenapiのドキュメントが表示される。
http://workerのIP:8000/docs
http://workerのIP
HAProxyを介してコンテナにアクセスする
HAProxy用のインスタンスで以下のコマンドを実行する。
sudo apt update && sudo apt upgrade -y && sudo apt install vim haproxy -y && sudo apt autoremove -y && sudo reboot
/etc/haproxy/haproxy.cfgに以下を追記する。
frontend nginxs
bind *:80
mode http
default_backend backend_nginxs
frontend fastapi
bind *:8000
mode http
default_backend backend_fastapi
backend backend_nginxs
server node00 192.168.1.30:80 check
server node01 192.168.1.31:80 check
server node02 192.168.1.32:80 check
backend backend_fastapi
server node00 192.168.1.30:8000 check
server node01 192.168.1.31:8000 check
server node02 192.168.1.32:8000 check
追記したら以下のコマンドを実行する。
# configに間違いが無いかを確認
sudo haproxy -f /etc/haproxy/ -c
# haproxyを稼働させる
sudo systemctl start haproxy.service
sudo systemctl enable haproxy.service
ここまで来たら以下のURLにブラウザからアクセスするとngixの画面やfastapiのopenapiのドキュメントが表示される。
http://haproxyのIP:8000/docs
http://haproxyのIP
workerを落としてみる
workerをshutdownとかしたり再起動させたりする。
そうするとそのworkerで動いていたコンテナは別のworkerに再配置される
managerを落としてみる
1台落としてみる
shutdownとかして落としてみる。
特にどうということはない。
もう1台落としてみる
残っている1台のマネージャでクラスタに関するコマンドを実行するとエラーになる。
e.g.
sudo docker service ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
ただこの状態でもHAProxyを介して各サービスにアクセスできるし、
managerを全台落としてもサービスの提供は継続される。
落としたmanagerを起動させれば自然と復旧する。
おわり
次はこの構成にconsulを追加したり、HAProxyをkeepaliveとVRRPで冗長化したりしたい。
さくらのクラウドにもマネージドデータベースなサービスが有るのでpostgresqlはそっちを使ってもいいのかも?
その他
-
何でmanagerは3台なの?2台じゃだめなの?
公式ドキュメントのManager nodesの項 にもあるように
N個のマネージャーを持つクラスターは、最大で(N-1)/2個のマネージャーの損失を許容する感じなので、2台だと足りない。また、常に全数の内 過半数のmanagerが稼働している必要がある。 -
docker swarm init した時に表示されたtokenが分からなくなったら。
managerのインスタンスでdocker swarm join-token workerを実行すれば表示される。 -
tokenを再生成したい
docker swarm join-token --rotate workerをmanagerのホスト上で実行する。
実行すると古いtokenは無効になる。
tokenは参加時に有効であればいいので、tokenを再生成しても既存のnodeには影響がない。以下にそう書いてある。
また、tokenは機密情報なのでgithubで管理したりオープンなチャットに送ったりしない。
ベストプラクティスっぽいものは上記のURL先に書いている。