はじめに
ベイズ因果推論
因果推論の文脈で、平均処置効果(Average Treatment Effect, ATE)の推定は線形回帰やロジット回帰、傾向スコア法などを用いて行われることが多くあります。そこで実務では次のような疑問に直面することが少なくありません。
- 推定されたATEの不確実性を、分布として表現したい
- 非線形モデルにおいて、回帰係数とATEが一致しない問題をどう扱うべきか
- 推定にモデルの仮定や事前情報を明示的に反映させたい
これらの問いに自然に答えてくれる枠組みが、ベイズ因果推論です。
ベイズ的なアプローチでは、ATEを単なる点推定量としてではなく、
$$p(\text{ATE} \mid \text{data})$$
という事後分布として捉えることができます。これにより、
- 「ATEが正である確率はどれくらいか」
- 「95%の信用区間はどの範囲か」
といった問いに直接答えることが可能になります。
g-computation
ベイズでATEを推定する際に中心的な役割を果たすのがg-computation(g-formula)です。g-computationは、「もし全員に処置を行ったら(あるいは行わなかったら)、結果は平均的にどうなるか」という反実仮想の問いを、
- モデルを推定し
- 処置を固定した仮想データを生成し
- 共変量分布で平均を取る
という手続きによって数値的に評価します。
特にロジット回帰やプロビット回帰のような非線形モデルでは、回帰係数そのものがATEを意味しないため、
$$E[Y(1)] - E[Y(0)]$$
の評価にはg-computationが必要となります。
準備
- 処置変数:$A\in \lbrace 0,1\rbrace$
- 処置前の変数:$Z$
- アウトカム:$Y$
- データ:$\lbrace A_i, Z_i, Y_i;i=1,\cdots, n\rbrace$
平均処置効果を以下で定義する。
$$ATE = E\lbrace Y(1) \rbrace-E\lbrace Y(0)\rbrace$$
$E\lbrace Y(a) \rbrace$を識別したいとき、観察されるデータの分布が分かっているならば$E\lbrace Y(a) \rbrace$は以下で表現される(g-formula)。
$$E\lbrace Y(a) \rbrace = \int E\lbrace Y|A = a, Z = z \rbrace p(z)dz$$
いま、$p(z)$がパラメータのベクトル$\eta$によって特徴付けられている($p(z;\eta)$)とすると、以下のステップによって$\theta,\eta$を推定することができる(g-computation)。
- 推定された$\hat \eta$に基づいて、ブートストラップにより$p(z;\hat \eta)$から$m$個のサンプル$z_1, \cdots, z_m$を生成する。
- 各$a$について$E\lbrace Y(a)\rbrace$のsample analogを計算する。
$$\hat E\lbrace Y(a)\rbrace = \frac{1}{m}\sum_{j=1}^m E\lbrace Y | A = a, Z_j = z_j;\hat \theta\rbrace$$
仮定
以下の3つの仮定が成立していると考える。
- Ignorability
$$\lbrace Y(0),Y(1)\rbrace \perp A|L$$
すなわち、$E(Y(1)|A=1,L) \equiv E(Y(1)|A=0,L)$が成立。
-
Positivity
$$\forall a, l\quad P(A=a|L=l)>0$$ -
Consistency
$$Y_i=Y_i(a) if A_i = a$$
シミュレーション
以下のようなロジスティック回帰モデルを考える。
$$logit(P(Y_i=1|A_i))=\alpha + \tau A_i + \beta'Z_i$$
ただし、$Z_i$は共変量のベクトルである。
set.seed(456)
df <- tibble::tibble(
Z1 = rbinom(n = 5000, size = 1, prob = 0.3),
Z2 = rbinom(n = 5000, size = 1, prob = plogis(0 + 0.2*Z1)),
A = rbinom(n = 5000, size = 1, prob = plogis(-1 + 0.7*Z1 + 0.8*Z2)),
Y = rbinom(n = 5000, size = 1, prob = plogis(-0.5 + 1*Z1 + 0.7*Z2 + 1.3*A))
)
fit1 <- glm(Y ~ 1 + Z1 + Z2 + A, family = binomial(link = "logit"), data = df)
coef <- coef(fit1)
fATE <- mean(plogis(cbind(1, df$Z1, df$Z2, 1) %*% coef) -
plogis(cbind(1, df$Z1, df$Z2, 0) %*% coef))
ATEの点推定
fit1 <- glm(Y ~ 1 + Z1 + Z2 + A, family = binomial(link = "logit"), data = df)
coef <- coef(fit1)
fATE <- mean(plogis(cbind(1, df$Z1, df$Z2, 1) %*% coef) -
plogis(cbind(1, df$Z1, df$Z2, 0) %*% coef))
頻度論的な点推定では約0.27というサイズのATEが得られる。
> print(fATE)
[1] 0.2701615
Stanファイルの実装
モンテカルロ積分によるg-computationを行うため、Stanファイルを実装する。
data {
int<lower=0> N;
int<lower=0> P;
matrix[N, P] X;
vector[N] A;
int<lower=0,upper=1> Y[N];
}
transformed data {
vector[N] boot_probs = rep_vector(1.0/N, N);
}
parameters {
vector[P + 1] alpha;
}
transformed parameters {
vector[P] beta = head(alpha, P);
real tau = alpha[P + 1];
}
model {
alpha ~ normal(0, 2.5);
Y ~ bernoulli_logit(X * beta + A * tau);
}
generated quantities {
int row_i;
real ATE = 0;
vector[N] Y_a1;
vector[N] Y_a0;
for (n in 1:N) {
row_i = categorical_rng(boot_probs);
Y_a1[n] = bernoulli_logit_rng(X[row_i] * beta + tau);
Y_a0[n] = bernoulli_logit_rng(X[row_i] * beta);
ATE = ATE + (Y_a1[n] - Y_a0[n])/N;
}
}
MCMC
MCMCによってパラメータ$\tau$の推定値をサンプリングし、事後分布を可視化する。
data_list <- list(N = nrow(df),
P = 3,
X = cbind(1, df$Z1, df$Z2),
A = df$A,
Y = df$Y)
rstan::rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
fit1 <- rstan::stan(file = "g-computation.stan", data = data_list)
post <- rstan::extract(fit1) |>
tibble::as.tibble()
ggplot2::ggplot(post, ggplot2::aes(x = ATE)) +
ggplot2::geom_density(fill = "skyblue", alpha = 0.4) +
ggplot2::geom_vline(xintercept = mean(post$ATE), linewidth = 1) +
ggplot2::geom_vline(
xintercept = quantile(post$ATE, c(0.025, 0.975)),
linetype = "dashed"
) +
ggplot2::annotate(
"text",
x = mean(post$ATE),
y = Inf,
label = paste0("", round(mean(post$ATE), 3)),
vjust = 1.5,
hjust = -0.3
) +
ggplot2::labs(
title = "Posterior distribution of ATE",
x = "ATE",
y = "Density"
) +
ggplot2::theme_minimal()
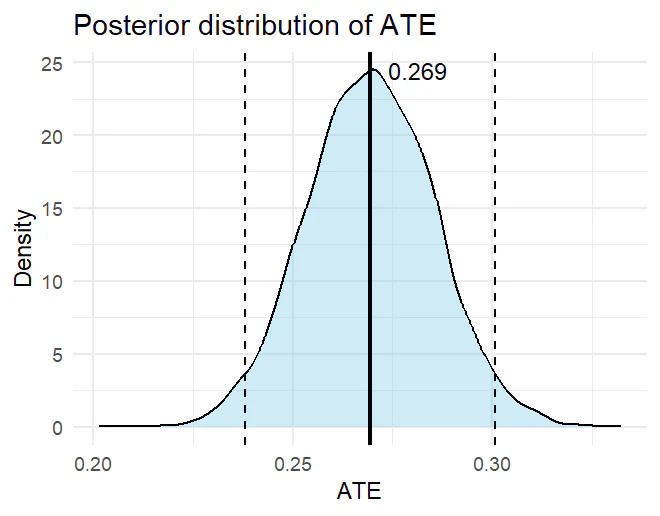
点推定は0.27だったが、ATEの事後分布は0.269を平均とする分布になっており、妥当な結果だといえる。また、95%信用区間は$[0.23, 0.30]$であることがわかる。
> quantile(post$ATE, c(0.025, 0.975))
2.5% 97.5%
0.2382 0.3008