はじめに
因果推論では、データから直接検証できない仮定を置く必要があります。そのため、データをどれだけ多く集めても、あるパラメータの推論は必ずしも精緻になりません。
このようなパラメータを感度パラメータ(sensitivity parameter)と言います。Estimandは感度パラメータの関数であることが多く、ここでは事前分布によって決定されると考えます。
今回は、感度分析(Sensitivity Analysis)によって因果推論における仮定への依存度を可視化することを試みます。
Sensitivity Analysis
無視可能性を仮定したもとでのpoint-treatmentを考えます。
$$Y(a) \perp\ A \mid L$$
ただし、$Y(a)$は潜在結果、$A$は処置変数、$L$は観測可能な共変量です。
この仮定は$(Y(1) \mid A=1,L) \equiv (Y(0) \mid A =0, L)$を示唆しますが、これは観察データから示すことができません。
いま、以下のような状況を考えます。
$$(Y(1) \mid A=1,L) \sim N(\beta_0 + \beta_1 L, \sigma^2)$$
$$(Y(0) \mid A=0,L) \sim N(\alpha_0 + \alpha_1 L, \sigma^2)$$
無視可能性のもとでは、$\alpha_j = \beta_j \quad (j=0, 1)$が成立します。
より一般的には、観察データからは識別できないパラメータ$\Delta_j$を用いて、
$$\alpha_j = \beta_j \ + \Delta_j$$
と書けます。この$\Delta_j$を感度パラメータ(sensitivity parameter)と呼びます。
念頭にあるモデルが無視可能性の仮定からどれくらい逸脱しているかを定量的に示すために、$\Delta_j$の事前分布を設定します。
$$\Pi(\Delta_j)=I(\Delta_j = 0)$$
$E[Y(a)]$が以下のように識別されることに注意すると、
$$E[Y(a)]=\int E[Y(a) \mid L=l]dF_{L=l}(l)$$
$$=\int E[Y(a) \mid L=l, A=a]dF_{L=l}(l) \ \cdots ①$$
$$=\int E[Y\mid L=l, A=a]dF_{L=l}(l) \ \cdots ②$$
(①は無視可能性、②は一致性より成立)
潜在的なsensitivityパラメータは以下のように定義されます。
$$\Delta_a(l) = E[Y(a)\mid A=1, L =l] \ - E[Y(a)\mid A=0, L =l]$$
ATEを$\psi$で表すと、
$$\psi = E[Y(1)] \ -E[Y(0)]$$
となることから、
$$\int E[Y \mid A=1,L=l]dF_{L=l}(l) \ - \int E[Y \mid A=0, L=l]dF_{L=l}(l) = \psi + \xi$$
ただし、
$$\xi = \int[\Delta_1(l)e(l) \ + \Delta_0(l)\lbrace 1-e(l)\rbrace]dF_{L=l}(l)$$
で、$e(l)$は$e(l)=P(A=1 \mid L)$なる傾向スコアです。
$\Delta_1(l), \Delta_0(l)$については観察されるデータから知ることができないため、何らかの仮定を置く必要があります。ここでは$\Delta_1(l)=\Delta_0(l)=\Delta$とします。
すると、
$$\xi = \int[\Delta e(l) \ + \Delta \lbrace 1-e(l)\rbrace]dF_{L=l}(l)=\Delta$$
となり、これがセレクションバイアスのサイズとなります。
$$E[Y(0) \mid A=1, L] \ - E[Y(0) \mid A=0,L]=\Delta$$
$\Delta < 0$の方向にセレクションバイアスが存在すると考えられるとき、$\Delta = -\Delta^*$として、
$$\Delta^{*}\sim Gamma(a,b)$$
なる事前分布を設定します。
シミュレーション
- $A$:処置変数
- $L$:観測可能な共変量
- $U$:観測不可能な共変量
- $Y$:アウトカム
サンプルサイズを$N = 1,\cdots, 100$として、上記の変数を生成します。
ただし、処置割当の確率、処置変数の生成、アウトカムの生成には以下を仮定します。
$$P(A_i = 1\mid L_i, U_i)=logit^{-1}(L_i + U_i)$$
$$A_i \mid L_i, U_i \sim Bernoulli(logit^{-1}(L_i + U_i))$$
$$Y_i \mid A_i, L_i, U_i \sim N(A_i - L_i - 2U_i, 1)$$
ここでは真のATEのサイズは1となります。
set.seed(123)
N = 100
warmup = 500
iter = 1000
n_draws = iter - warmup
L = rnorm(N)
U = rnorm(N)
A = simcausal::rbern(N, prob = arm::invlogit(0 + 1*L + 1*U))
Y = rnorm(N, mean = 0 + 1*A - 1*L - 2*U, sd = 1)
続いてStanファイルを書き、コンパイルとMCMCを実行します。
data {
int N;
vector[N] treatment;
vector[N] confounder;
vector[N] outcome;
}
parameters {
real theta; // treatment differential estimate
real beta; // confounder coefficient
real<lower=0> phi; // conditional outcome distribution variance
real<lower=0> delta; // sensitivity parameter
real delta1; // sensitivity parameter
}
model {
theta ~ normal(0, 3);
beta ~ normal(0, 3);
delta ~ gamma(1, 3);
delta1 ~ normal(0, 1/sqrt(3) );
outcome ~ normal(treatment * theta + beta * confounder, phi);
}
generated quantities {
real psi1;
real psi2;
real psi3;
psi1 = theta + 1*delta;
psi2 = theta - 1*delta;
psi3 = theta + delta1;
}
stan_data <- list(
outcome = Y,
confounder = L,
treatment = A,
N = N)
rstan::rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores())
mcmc_fit <- rstan::stan(file = "sensitivity_analysis.stan", data = stan_data)
パラメータの事後サンプルを抽出し、$\psi_s = \psi - \Delta$の事後分布を可視化します。
post_draws <- rstan::extract(mcmc_fit, pars=c('theta','psi3','psi2','psi1'))
post_draws_summary <- do.call('cbind', post_draws) |>
tibble::as_tibble() |>
tidyr::pivot_longer(
cols = dplyr::everything(),
names_to = "parameter",
values_to = "value"
) |>
dplyr::group_by(parameter) |>
dplyr::summarise(
mean = mean(value),
lwr = quantile(value, 0.025),
upr = quantile(value, 0.975),
.groups = "drop"
) |>
dplyr::mutate(parameter = factor(parameter, levels = c("theta", "psi1", "psi2", "psi3")))
ggplot2::ggplot(post_draws_summary, ggplot2::aes(x = parameter, y = mean)) +
ggplot2::geom_point(size = 3) +
ggplot2::geom_errorbar(
ggplot2::aes(ymin = lwr, ymax = upr),
width = 0.15
) +
ggplot2::geom_hline(yintercept = 1, linetype = 2, color = "red") +
ggplot2::labs(
y = "Distance between true ATE and Selection Bias",
x = "Sensitivity Parameter Prior"
) +
ggplot2::theme_minimal()
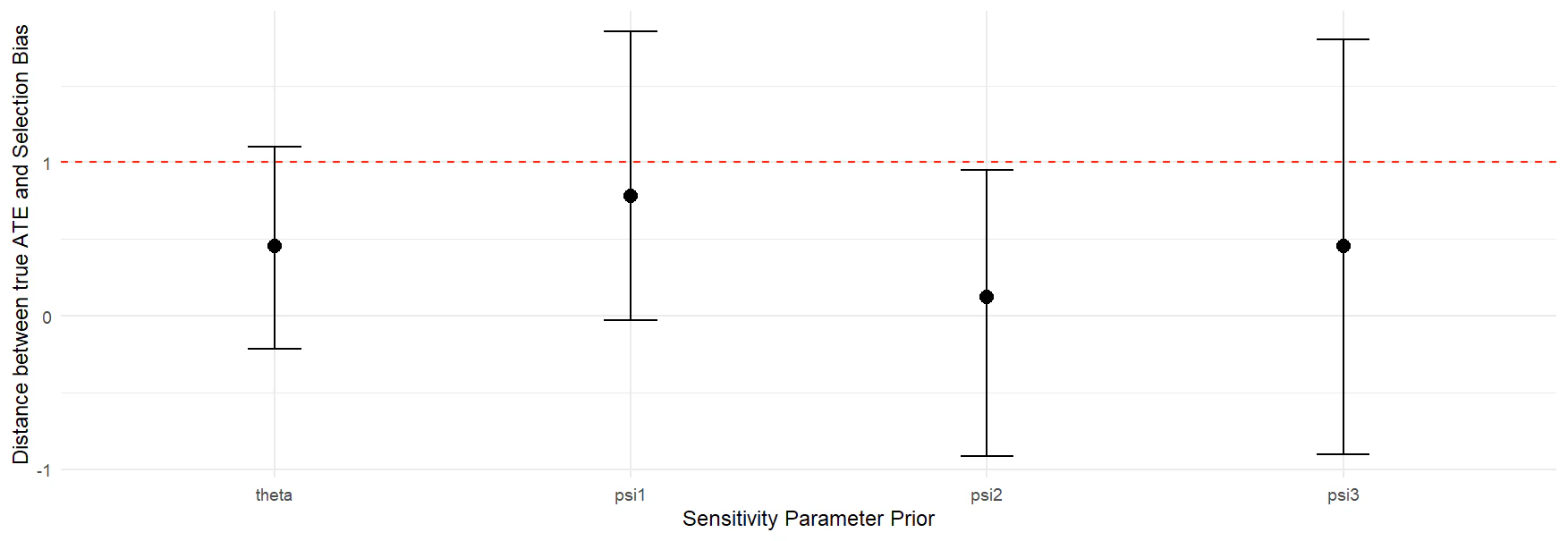
左から順に$\Delta \sim \delta_0,\ \Delta^* \sim Gam(1,3), \Delta \sim Gam(1,3), \ \Delta \sim N(0, 3^{-1/2})$のケースを示しています。
無視可能性が成立し、$\Delta$が平均0の分布に従っていると仮定したもとで、実際には観測不可能な共変量$U$が存在するために$\psi_0$が$\psi$から大きく外れていることが分かります。
一方で、左から2番目は$\Delta < 0$の方向にセレクションバイアスが存在すると仮定しているため、$\psi_0$と$\psi$の距離が縮まっていることが分かります。
参考文献
Oganisian, A., & Roy, J. (2021). A Practical Introduction to Bayesian Estimation of Causal Effects:Parametric and Nonparametric Approaches. Statistics in Medicine, 40(2), 518–551.