はじめに
これは一部のHTMLタグだけ許可する(DOM編)の続編で、正規表現で、一部のHTMLタグを許可してみようという試みである。
アーキテクチャ(基本方針)
こんな感じ
- 全体をHTMLエンコードしておく
- 許可タグだけ、HTMLデコードで、元のタグに戻していく
許可タグとして認識できる文字列だけ、ホワイトリスト方式のように、元のタグに戻るので、想定していないタグが有効になるなどの予想もしていない脆弱性が生まれないだろう。
アーキテクチャ(基本方針)(あいまいな書式の HTML)
前回の「一部のHTMLタグだけ許可する(DOM編)」もそうだが、Webページ上のリッチテキストライブラリが吐き出すHTML形式の装飾されたテキストをXSSのような脆弱性を生むことなく利用しよう、というのが前提なので、自由度のあるあいまいな解釈(例えば、ダブルクォートだけではなくシングルクォートで括ってもよいとか、そもそも括らなくてもなんとなく解釈してくれるとか)をする必要はなくて、そのWebページ上のリッチテキストライブラリが吐き出す形式だけ許可するようにすればよい。
アーキテクチャ(基本方針)(事前のHTMLエンコード)
入力データは、HTMLエンコードがある程度実施されているという前提(<と<の混在)だと仮定すると、単純な HTMLエンコード処理ではなく、「<」「>」「"」だけをエンコードする方がよい場合(無用な二重エンコードは汚い)もあるので、このあたりは入力されるデータの書式をあらかじめ吟味しておく必要がある。
まぁ、一旦HTMLエンコードしたうえで、「&amp;」→「&」に置換しておく。という方法で無用な二重エンコードを防いでもよい。
アーキテクチャ(基本方針)(属性のないタグ)
前篇からの前提を引き継いで、属性のない許可タグとして B タグと、Iタグと、それと、今回は BR タグを追加しよう。
属性がないので、正規表現としては単純だ。
つまり
- <B>
- </B>
- <I>
- </i>
- <BR>
だ。
データは事前にHTMLエンコードされているので、これらは、
- <B>
- </B>
- <I>
- </i>
- <BR>
になる。それぞれ、これらをHTMLデコードしてもどしてやるだけなので、特に問題はないだろう。
これらを一つの正規表現にまとめると、
<((/?((b)|(i)))|(br)|(/font))>
(ついでにfontの閉じタグも仲間に入れたよ)
アーキテクチャ(基本方針)(許可属性のあるタグ)
ここも前篇からの前提を引き継いで、FONTタグで、許可属性は、sizeとcolorということにしてみる。
正規表現は、こんな感じになるだろう。
<font((●●●●)|(◆◆◆◆))+>
アーキテクチャ(基本方針)(許可属性のあるタグ)(size属性)
さて、一つ目の●●●●について、size属性について考えてみよう。
size属性は、数値なので、数値しか与えられないだろう。
という事で、こんな感じになる
size="[0-9]+"
属性の値についてもホワイトリスト方式のように許可のみヒットするようにする事が重要
アーキテクチャ(基本方針)(許可属性のあるタグ)(color属性)
color属性は、アルファベット(色名)と#16進数なので、こんな感じでどうだろう。
color="[a-z0-9#]+"
特に、属性の値として「"」や「'」(エンコードされた「"」と「'」)は危険なので、それらがヒットしないように注意
アーキテクチャ(基本方針)(許可属性のあるタグ)(まとめ)
上記をまとめるとこんな感じになる
<font(( size="[0-9]+")|( color="[a-z0-9#]+"))+>
テスト結果
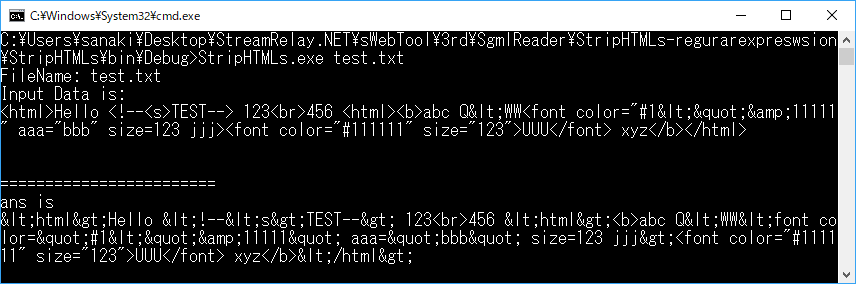
サンプルコードについて
サンプルはC#/.NET Frameworkだけど、JavaとかでPHPには移植しやすいと思う。
サンプルは、Bタグと、Iタグと、FONTタグのCOLORとSIZE属性だけ許可するようにしている正規表現だが、それ以外のタグについては、これらの正規表現を修正すればいいだろう。
DOM版よりコードが短くなっているなぁ~...
サンプルコードについて(正規表現のクラス)
正規表現のオプション(System.Text.RegularExpressions.RegexOptions)は、サンプルコードでは RegexOptions.IgnoreCase|RegexOptions.Singleline だけど、アプリケーション起動中に解放しないという事であれば RegexOptions.Compiled を足すと処理が速くなるそうだ。
(なんか、Compiled にすると、解放時にメモリリークみたいな問題があるそうだけど、逆に言えば解放しない固定な正規表現には使えるという事だと思う)
私はstaticのRegexにしている
public static Regex obj = new RegEx(......
みたいな感じ
サンプルコード(Program.cs)
using System;
using System.IO;
using System.Text.RegularExpressions;
using System.Web;
namespace StripHTMLs
{
class Program
{
static void Main(string[] args)
{
StreamReader reader = new StreamReader(new FileStream(args[0], FileMode.Open, FileAccess.Read));
String motoData = reader.ReadToEnd();
Console.WriteLine("FileName: " + args[0]);
Console.WriteLine("Input Data is: ");
Console.WriteLine(motoData);
Console.WriteLine("========================");
Console.WriteLine("ans is");
// まずは、HTMLエンコードをする(既にエンコード済の文字が再エンコードされないように「<」「>」「"」だけエンコードする)
motoData = motoData.Replace("<","<").Replace(">",">").Replace("\"",""");
// <b></b><i></i><br></font>など属性のない許可タグ(と閉じタグ)を元に戻す
// <(((/)?((b)|(i)))|(br)|(/font))>
// →
// <
// (
// (
// (/)?((b)|(i))
// )
// |
// (br)
// |
// (/font)
// )
// >
Regex regex0 = new Regex("<(((/)?((b)|(i)))|(br)|(/font))>", RegexOptions.IgnoreCase | RegexOptions.Singleline);
motoData = regex0.Replace(motoData, m => HttpUtility.HtmlDecode(m.Value) );
// fontタグのsizeとcolorだけ許可する
// <font(( size="[0-9]+")|( color="[a-z0-9#]+"))+>
// →
// <font
// (
// ( size="[0-9]+")
// |
// ( color="[a-z0-9#]+")
// )+
// >
Regex regex1 = new Regex("<font(( size="[0-9]+")|( color="[a-z0-9#]+"))+>", RegexOptions.IgnoreCase | RegexOptions.Singleline);
motoData = regex1.Replace(motoData, m => HttpUtility.HtmlDecode(m.Value));
Console.WriteLine(motoData);
}
}
}
次回は具体的なjsライブラリに対応してみる
一部のHTMLタグだけ許可する(CKEditer編)(正規表現編)