はじめに
こんにちは!みそしるです!
今回は、ドットログ内ハッカソンで作成した拡張機能「ReaDash」の紹介と、開発で行った日本語分かち書きの調整を解説いたします!
ReaDash とは
ReaDashは、ウェブページのテキストを一度にすべて表示するのではなく、フレーズごとに表示することで、速読を支援するブラウザ拡張機能です。
ウェブページからテキストを抽出し、一度に1つの文章のまとまりを表示します。矢印キーを押しながら一点を見つめ続けることで視線移動なくあらゆる文章を斜め読みすることができます。

本記事では、ReaDashで採用している、軽量で扱いやすいTinySegmenterを使った自然な日本語の分かち書きの実現方法を、実例を交えて解説します。
TinySegmenter とは?
まず、TinySegmenterについて説明します。
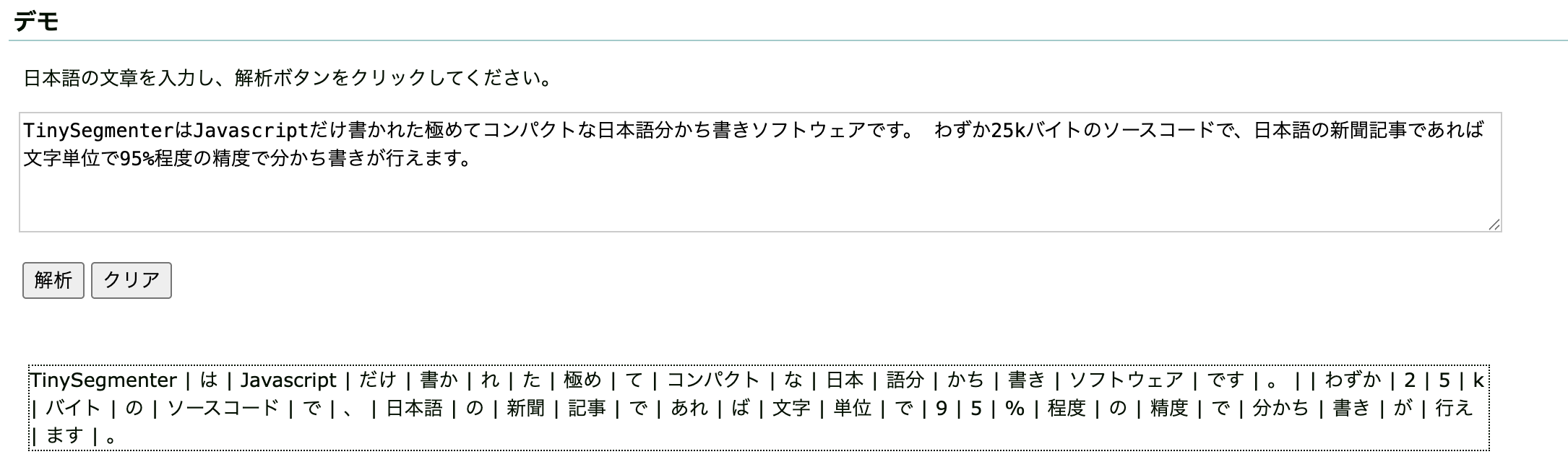
公式のデモページを引用します。
TinySegmenterはJavascriptだけ書かれた極めてコンパクトな日本語分かち書きソフトウェアです。 わずか25kバイトのソースコードで、日本語の新聞記事であれば文字単位で95%程度の精度で分かち書きが行えます。
日本語の分かち書きに特化しているかつ、クライアントのみで動くのが魅力的です。
ただし、以下の画像のように分かち書きは必ずしも「読みやすいまとまり」「意味のあるまとまり」を提供するわけではありません。
そこで、ReaDashの開発では、単純なパターンマッチでいくつかのパターンを調整し、文章を読みやすく分割できるように工夫をしています。
TinySegmenterの出力:何が問題なのか?
TinySegmenterは単語レベルで分割しますが、そのまま使うと速読には細かすぎます。
例文1: ニュース記事の一文
元のテキスト
新しいブラウザ拡張機能が2024年11月15日にリリースされました。
TinySegmenterの素の出力
["新しい", "ブラウザ", "拡張", "機能", "が", "2024", "年", "11", "月", "15", "日", "に", "リリース", "さ", "れ", "まし", "た", "。"]
問題点
- 「拡張機能」が「拡張」と「機能」に分割される
- 日付が「2024」「年」「11」「月」「15」「日」とバラバラ
- 「リリースされました」が細切れになる
例文2: 会話文
元のテキスト
彼は「こんにちは」と言って微笑んでいる。
TinySegmenterの素の出力
["彼", "は", "「", "こんにちは", "」", "と", "言っ", "て", "微笑ん", "で", "いる", "。"]
問題点
- 引用符が単独で分割される
- 「微笑んでいる」が「微笑ん」「で」「いる」に分割される
これらを自然なフレーズに整形していきます。
自然な分かち書きを実現する5つのパターン
パターン1: 引用符・括弧のグルーピング
短い引用は引用符ごと1つのまとまりにします。
悪い例(TinySegmenterのまま)
["彼", "は", "「", "こんにちは", "」", "と", "言っ", "た"]
→ 引用符「」が孤立している
良い例(引用符グルーピングのみ適用)
["彼", "は", "「こんにちは」", "と", "言っ", "た"]
→ 「こんにちは」が引用符ごと1つのまとまりに
実装のポイント
// 引用符で囲まれた短いテキスト(12文字以下)を検出
let inQuote = false;
let quoteBuffer = '';
for (const word of words) {
// 「 や(の開始を検出
if (/^[「((]/.test(word)) {
inQuote = true;
quoteBuffer = word;
continue;
}
if (inQuote) {
quoteBuffer += word;
// 」 や)の終了を検出
if (/[」))]$/.test(word)) {
inQuote = false;
// 短い引用(12文字以下)はそのまま1つのフレーズに
if (quoteBuffer.length <= 12) {
buffer += quoteBuffer;
wordCount++;
}
quoteBuffer = '';
}
}
}
他の例
例文: 製品名は「ReaDash」です。
| TinySegmenterのまま | 引用符グルーピングのみ適用 |
|---|---|
["製品", "名", "は", "「", "ReaDash", "」", "です", "。"] |
["製品", "名", "は", "「ReaDash」", "です", "。"] |
例文: 価格(税込)は500円でした。
| TinySegmenterのまま | 括弧グルーピングのみ適用 |
|---|---|
["価格", "(", "税込", ")", "は", "500", "円", "でし", "た", "。"] |
["価格", "(税込)", "は", "500", "円", "でし", "た", "。"] |
パターン2: 日付パターンの統合
日付は1つのまとまりとして扱います。
悪い例(TinySegmenterのまま)
["2024", "年", "11", "月", "15", "日", "に", "開催", "さ", "れ", "ます"]
→ 日付「2024年11月15日」がバラバラ
良い例(日付統合のみ適用)
["2024年11月15日", "に", "開催", "さ", "れ", "ます"]
→ 日付が1つのまとまりに
実装のポイント
// 数字で始まる場合、日付パターンをチェック
if (/^\d{1,4}$/.test(word)) {
let dateBuffer = word;
let j = idx + 1;
let isDate = false;
// 年月日、/, - などが続くかチェック
while (j < words.length && j < idx + 10) {
const next = words[j];
if (/^[年月日\/\-]$/.test(next) || /^\d{1,4}$/.test(next)) {
dateBuffer += next;
j++;
if (/[年月日\/\-]/.test(next)) {
isDate = true; // 日付パターンを検出
}
} else {
break;
}
}
// 日付として検出された場合、まとめて追加
if (isDate) {
buffer += dateBuffer;
wordCount++;
idx = j - 1;
}
}
他の例
例文: セールは12月25日から始まります。
| TinySegmenterのまま | 日付統合のみ適用 |
|---|---|
["セール", "は", "12", "月", "25", "日", "から", "始まり", "ます", "。"] |
["セール", "は", "12月25日", "から", "始まり", "ます", "。"] |
例文: 締切は2024/12/31です。
| TinySegmenterのまま | 日付統合のみ適用 |
|---|---|
["締切", "は", "2024", "/", "12", "/", "31", "です", "。"] |
["締切", "は", "2024/12/31", "です", "。"] |
例文: 会議は11月から開始されました。
| TinySegmenterのまま | 日付統合のみ適用 |
|---|---|
["会議", "は", "11", "月", "から", "開始", "さ", "れ", "まし", "た", "。"] |
["会議", "は", "11月", "から", "開始", "さ", "れ", "まし", "た", "。"] |
パターン3: 数字のグルーピング
4桁以内の数字は1つのまとまりにします。
悪い例(TinySegmenterのまま)
["価格", "は", "1", ",", "234", "円", "です"]
→ 数字「1,234」がバラバラ
良い例(数字グルーピングのみ適用)
["価格", "は", "1,234", "円", "です"]
→ カンマ区切りの数字が1つにまとまる
実装のポイント
// 数字(4桁以内)を1つのまとまりとして扱う
if (/^\d{1,4}$/.test(word) || /^\d{1,3}(,\d{3})?$/.test(word)) {
let numberBuffer = word;
let j = idx + 1;
// 次も数字なら結合(4桁まで)
while (j < words.length &&
/^[\d,]+$/.test(words[j]) &&
numberBuffer.replace(/,/g, '').length <= 4) {
numberBuffer += words[j];
j++;
}
buffer += numberBuffer;
wordCount++;
idx = j - 1;
}
他の例
例文: 参加者は約500名でした。
| TinySegmenterのまま | 数字グルーピングのみ適用 |
|---|---|
["参加", "者", "は", "約", "500", "名", "でし", "た", "。"] |
["参加", "者", "は", "約", "500", "名", "でし", "た", "。"] |
例文: 売上は3,800万円を超えた。
| TinySegmenterのまま | 数字グルーピングのみ適用 |
|---|---|
["売上", "は", "3", ",", "800", "万", "円", "を", "超え", "た", "。"] |
["売上", "は", "3,800", "万", "円", "を", "超え", "た", "。"] |
パターン4: て形動詞+補助動詞の結合
「見ている」「やってみる」のような複合動詞は分割しません。
悪い例(TinySegmenterのまま)
["彼", "は", "走っ", "て", "いる"]
→ 「走っている」が分割される
良い例(改善後)
["彼は", "走っている"]
→ 動詞の活用形が自然に
実装のポイント
const nextWord = words[idx + 1] || '';
// て形・で形を検出
const isTeForm = /[てで]$/.test(word);
// 補助動詞を検出
const isAuxiliaryVerb = /^(いる|ある|おく|みる|しまう|くる|いく|もらう|あげる|くれる)/.test(nextWord);
// て形+補助動詞の場合は区切らない
const shouldBreak = !(isTeForm && isAuxiliaryVerb) &&
wordCount >= maxWordsPerPhrase;
他の例
例文: 本を読んでいる最中です。
| TinySegmenterのまま | 改善後 |
|---|---|
["本", "を", "読ん", "で", "いる", "最中", "です", "。"] |
["本を", "読んでいる", "最中です。"] |
例文: 試してみることにした。
| TinySegmenterのまま | 改善後 |
|---|---|
["試し", "て", "みる", "こと", "に", "し", "た", "。"] |
["試してみる", "ことにした。"] |
例文: ドアを開けておいてください。
| TinySegmenterのまま | 改善後 |
|---|---|
["ドア", "を", "開け", "て", "おい", "て", "ください", "。"] |
["ドアを", "開けておいて", "ください。"] |
例文: やってしまった感じがする。
| TinySegmenterのまま | 改善後 |
|---|---|
["やっ", "て", "しまっ", "た", "感じ", "が", "する", "。"] |
["やってしまった", "感じがする。"] |
パターン5: 句読点の扱い
句読点は前のフレーズに含めてから区切ります。
悪い例(処理なし)
["彼は走った", "。", "そして止まった"]
→ 句読点が孤立する
良い例(改善後)
["彼は走った。", "そして止まった"]
→ 句読点が自然な位置に
実装のポイント
// 句読点のみの場合は、前のバッファに追加してから区切る
const isPunctuationOnly = /^[、。!?,.!?]+$/.test(word);
if (isPunctuationOnly) {
if (wordCount > 0) {
buffer += word; // 句読点を追加
result.push(buffer); // フレーズを確定
buffer = '';
wordCount = 0;
}
continue;
}
他の例
例文: 今日は晴れ、明日は雨です。
| 処理なし | 改善後 |
|---|---|
["今日は晴れ", "、", "明日は雨です", "。"] |
["今日は晴れ、", "明日は雨です。"] |
例文: 驚いた!すごいね。
| 処理なし | 改善後 |
|---|---|
["驚いた", "!", "すごいね", "。"] |
["驚いた!", "すごいね。"] |
URL混在テキストへの対応
速読アプリでは、Webページに含まれるURLも適切に扱う必要があります。
問題
元のテキスト
詳しくはhttps://example.com/pageを参照してください。
TinySegmenterの出力
["詳しく", "は", "https", ":", "//", "example", ".", "com", "/", "page", "を", "参照", "し", "て", "ください", "。"]
→ URLが細かく分割されてしまう
解決策: プレースホルダー方式
-
セグメント前: URLを
__URL_0__のようなプレースホルダーに置換 - セグメント: TinySegmenterで分割
- 結合: 分割されたプレースホルダーを検出して結合
-
復元:
[🔗example.com](https://example.com/page)形式に変換
// 1. URLを保護
const { text: processedText, urls } = urlProtector.protect(text);
// "詳しくは__URL_0__を参照してください。"
// 2. セグメント化
const segmenter = new TinySegmenter();
let words = segmenter.segment(processedText);
// 3. プレースホルダーの結合
words = urlProtector.mergeFragmentedPlaceholders(words);
// 4. URLの復元
for (const word of words) {
if (urlProtector.isPlaceholder(word)) {
result.push(urlProtector.toUrlLink(word, urls));
}
}
最終結果
["詳しくは", "[🔗example.com](https://example.com/page)を", "参照してください。"]
実例:すべてのパターンを組み合わせる
元のテキスト
2024年11月15日、新しい速読アプリ「ReaDash」が公開されました。詳細はhttps://example.comで確認できます。価格は1,200円で、すでに500名が使ってみています。
TinySegmenterのみ(改善前)
["2024", "年", "11", "月", "15", "日", "、", "新しい", "速", "読", "アプリ", "「", "ReaDash", "」", "が", "公開", "さ", "れ", "まし", "た", "。", "詳細", "は", "https", ":", "//", "example", ".", "com", "で", "確認", "でき", "ます", "。", "価格", "は", "1", ",", "200", "円", "で", "、", "すでに", "500", "名", "が", "使っ", "て", "み", "て", "い", "ます", "。"]
→ 細かすぎて読みづらい
全パターン適用後(改善後)
["2024年11月15日、", "新しい速読アプリ", "「ReaDash」が", "公開されました。", "詳細は", "[🔗example.com](https://example.com)で", "確認できます。", "価格は", "1,200円で、", "すでに500名が", "使ってみています。"]
→ 自然で意味のあるフレーズに
まとめ
TinySegmenterの出力をそのまま使うと細かすぎますが、以下の5つのパターンを適用することで、自然な文章の分割を目指しました。
- 引用符・括弧のグルーピング: 短い引用は引用符ごと1フレーズに
- 日付パターンの統合: 「2024年11月15日」を分割しない
- 数字のグルーピング: 「1,234円」をまとめて扱う
- て形動詞+補助動詞: 「見ている」「やってみる」を分割しない
- 句読点の適切な配置: 句読点を前のフレーズに含める
おまけ
この ぶんょしう は イリギス の ケブンッリジ だがいく の けゅきんう の けっか 、
にんんげ は もじ を にしんき する とき その さしいょ と さいご の もさじえ あいてっれば
じばんゅん は めくちちゃゃ でも ちんゃと よめる という けゅきんう に もづいとて
わざと もじの じんばゅん を いかれえて あまりす。
以上の文章のように、人間は大体、単語の形が合っていれば脳で補完して文章を読むことができるらしいです。(タイポグリセミアというらしい)
今回のような「速読」「斜め読み」をテーマとする場合は特に意味のまとまりに神経質になりすぎる必要はないと思います。ただ、最低限の違和感をなくすことを目指して今回のような実装を行いました。