【追記 2019/02/12】
記事の中で、QnA MakerはDeep Learning系のRNNアルゴリズムを使ってるんだろう的なことを書いたのですが、製品開発チームの人に聞く機会があって知ったのですが、どうやら違ったようです。何のアルゴリズムかは正確に確認できてないのですが、おそらくTF-IDFからのcosine類似度とかを使ってそうで、それは比較的昔からよく使われる手法だと思います。最近、Deep Learningばっかりが存在感を増しているので、「Deep Learningが先進的ですべてにおいて優れている」と勘違いしがちですが、冷や水をかけられた気分です。
へんな先入観なく、幅広いデータ分析アルゴリズムを考慮していかないとなと思わされた一件でした。
あー、だからモデル作るの滅茶苦茶早いのかー。
はじめに
前回、「Microsoft Cognitive Toolkit」っていうDeep Learningフレームワークを使って、ニューラルネットワーク系のコードを書いて作るChatBot実装について投稿しました。
Microsoftの自然言語分類技術を本気で検証してみた。〈Microsoft Cognitive ToolkitでのChatBot実装〉
あの頃は、まだあと2年くらいはCognitive Serviceのような簡易AIのサービスが、自前で書いたニューラルネットワーク系コードを超えることないんだろうなとか思ってました。まぁ、自前のコードは作り手の腕次第なんですが、それを差し引いても自前でオーダーメイドで時間かけてチューニングしてるんだから、自前の方が正答精度は高いでしょ!って思ってました。
だがしかし、やっぱこの世界の世代交代は早いなって、つくづく思います。
QnA Makerを検証して、とてつもない衝撃を受けました。もう半端ないっすね。
やはり、Microsoftが製品化してGA(製品化リリース)するということは、「世界中の人に叩かれ、文句いわれ、それに負けじと改善されて生き残ってきている」「僕らじゃ想像できないくらい優秀なソフトウェアでペローパーにより開発される」ということなんだなーって。
この衝撃を伝えたいなと思います。
たぶんここまでくれば、FAQチャットボットも特別な知識を持つ人がいなくでも作れるような頃合い(普及期)を迎えるんじゃないかなとか考えています。
この投稿で書く内容
- QnA Makerについての特記事項
- QnA MakerとMicrosoft Cognitive Toolkitベースの正答率の違い ※テスト結果
- QnA Makerの良いところと未だイマイチなところ
- QnA Makerの大雑把な紹介
- QnA Maker流の学習データについて
- 種類
- 作り方
- チューニング方法
- 学習運用について
- 実装の例
- 1問1答を1問多答にして正答率を上げる
- UIの実装例。FAQボットはチャットUIがベストではない!(と思う)
手元での正答率の検証結果
AI系のサービスで最も重視されることが多い精度。ChatBotでは正答率になりますが、やはり最も注目されます。
端的に書くと、同じ条件化で正答精度の評価をすると以下のような感じでした。
| Used By | 正答率 |
|---|---|
| Microsoft Cognitive Toolkitで作ったデータモデル | 96% |
| QnA Maker | (まさかの)100% |
正答精度100%とか意味がわからん!という衝撃。
なんかいろいろ自分のテスト条件を疑ってしまい(過学習かなとか)、調べて、何回もテストしましたが、100%ですね。正確には99%の時もあったのですが、学習データが明らかに間違ったデータだったので直したら100%になります。ということは、学習データがおかしくなければ(人間の判断と学習データが合致していれば)、100%の精度がでてしまうということ。
過去の苦労があるので目を背けたくなりましたが、ちゃんと受け止めねば。悔しいですが、品質での負けは負けで受け入れるべきっすよね。
なんか下町ロケットの佃社長が頭に浮かびます。※でも佃製作所って結局負けないじゃんね。ドラマってセコイなー。とか思ってたら、最終回は佃製作所が大手の立場で下町トラクターに負けたままで終わりました。ドラマだと主人公側が負けて終わるのもスッキリした気分になんないなーと思いました。
- 正答率の検証テスト内容
①学習データを作る ※基本重複データ無し。多少はある。
②学習データの8割をモデル学習用に、2割をテスト用に分ける
③学習してモデル作成。そのモデルでテスト。
④モデルから返ってきた回答のトップ3が正解だったら正解と判定
⑤②~⑤を3回行う
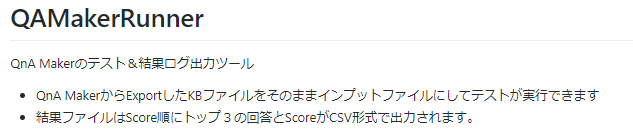
QnA Makerをテストをするためのプログラムを作ったので、Githubに置きました。良ければどうぞ。
https://github.com/tomohikue/QAMakerRunner
- 正答率とは(僕が勝手に使っている言葉です。世の中の標準で適した言葉が見つからず)
FAQが用意されている範囲での回答の正解率。
学習データとは別のテストデータでデータモデルに問い合わせを行い、「文章のみのインプットで人と同じ判断で答えを導きだせる率」。1000の文章を問いあわせたとして、900文章が正解すれば、正答率90%。FAQが用意されていない質問をした場合は、カウントの対象外にする。実運用の場合は、FAQが存在しない問い合わせを受ける可能性は十分にある。それは正答率の評価とは別に考えている。ちなみに僕のいうところの正答率は、「人の判断と同じ」というのが正解データなので、よくAI系のニュースにでてくる**「FAQチャットボットは人を超えるのか」っていう問いに関しては「人の判断が100%なんだから、100%である人を超えることはない」です。人を超えてFAQボットを作るためには利用者がインプットした文章以外**から、例えばFacebookとかから利用者の情報を取る必要がありますが、それはそれで有用そうなので、今後挑戦してみたいです。
QnA Makerの良いところと未だイマイチなところ
自作で作るデータモデルと比較して、QnA Makerの良いところと未だイマイチなところを、僕の視点でまとめてみました。
良いところ
-
技術的な難易度が今までより格段に低い
- 良いところはなんといってもコレでしょう?いままでFAQチャットボットのようなアプリを作るためには、機械学習や自然言語分類の知識がやっぱりたくさん必要でした。そういう知識があって、かつアプリケーション開発も兼ねた両方の知識ある人って割と少ない印象があるので、データサイエンティストっぽい人とアプリ開発の人の2人が必要で、ちょっとPoCやったりするくらいでもハードルが高かったと思います。今後はこの投稿で書いてるポイントを見てもらえば、アプリ開発者だけで作って、ボットの学習もできるようになると思います。
-
学習データの作り方が楽
- ちょっと説明が必要なので、後続の章で詳細は書きます。学習データを作るというめんどっちい作業が、当然かのように自動化されています。今まで自動化したくても開発工数が大きすぎてなかなか作れなかったのに、なんか当たり前かのように対応されていると逆にイラッとしますよね。
-
データモデルのトレーニング時間が短い
- Deep Leaning フレームワークだとGPUハイスペックマシン作って20分くらいかかるところが、QnA Makerなら 8.65秒でした。ふざけてますよね。いままでの悩ましい長時間の待ち時間はなんだったんだ。Excelの保存感覚で、データモデル作成まで終わります。(8.65秒と書きましたが、波が大きいです。)
未だイマイチなところ(12/12時点の課題点。改善される!はず。)
-
1問1答が前提で設計されているため、「聞き返し」に対応するにはカスタマイズが必要。Qに対するAの正答率が必ず100%になったとしても、「サインインできないんだけど?」といった曖昧な聞き方されると、システムAなのかシステムBなのか聞き返したいですよね?次のアップデートで、この機能に対応してほしい。
- 聞き返しとは、以下ようにScore(マッチ率)が低い時に選択肢を出す方法
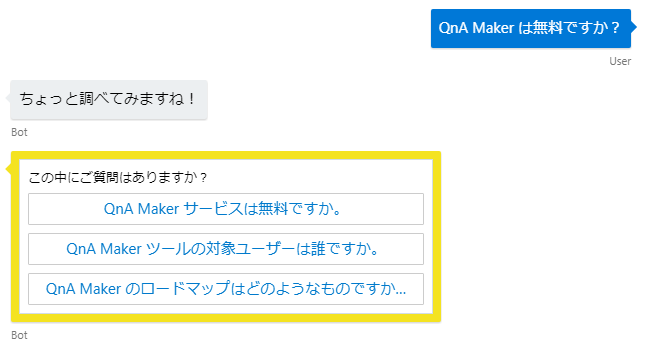
- 聞き返しとは、以下ようにScore(マッチ率)が低い時に選択肢を出す方法
-
必須の運用メンテナンスツールがまだあまり充実していない。
- FAQチャットボットは運用しながら、「新規のFAQ」「間違ってしまった回答」をメンテナンスしていく必要がある。そのための支援ツールが無い。Preview時は、簡易的とはいえあったのに、なくなってる。。。開発中でまだ完成していないだけだと信じたい。
- Previewにあった支援ツール・・・一般ユーザの問いあわせログをテスト画面に流し込んでくれる機能。一般ユーザに回答した内容をレビューしやすい仕様になっていて、良い機能だった。
- FAQチャットボットは運用しながら、「新規のFAQ」「間違ってしまった回答」をメンテナンスしていく必要がある。そのための支援ツールが無い。Preview時は、簡易的とはいえあったのに、なくなってる。。。開発中でまだ完成していないだけだと信じたい。
-
ユーザが問いあわせたレスポンスログがApplication Insightに蓄積されるが、以下のようなイマイチな点がある
- QnA Makerの画面からログがダウンロードできない。※Preview時はできたのに、、、。
- ログも1問1答の分しか記録されない。「聞き返し」の複数回答分は記録されない。なんかApplication Insightって自由な項目をセットする時はDictionary型で入れないといけないらしく、変なログ出力仕様になっている。これって設計ミスレベルの仕様だろって思った。
- あとApplication Insightってシステム部門向けには良いけど、業務部門にデータを提供するために使うストレージとして使いにくい。ログはRDBかTabel型DBしてほしかった。まだ作っているところですが今のところ、僕はAzure StorageのTableか、Cosmos DBのTableでログ蓄積しようと考えています。
QnA Makerの大雑把な紹介
紹介文は今更感があるのですが、歴史を絡めながら大雑把にQnA Makerを紹介します。
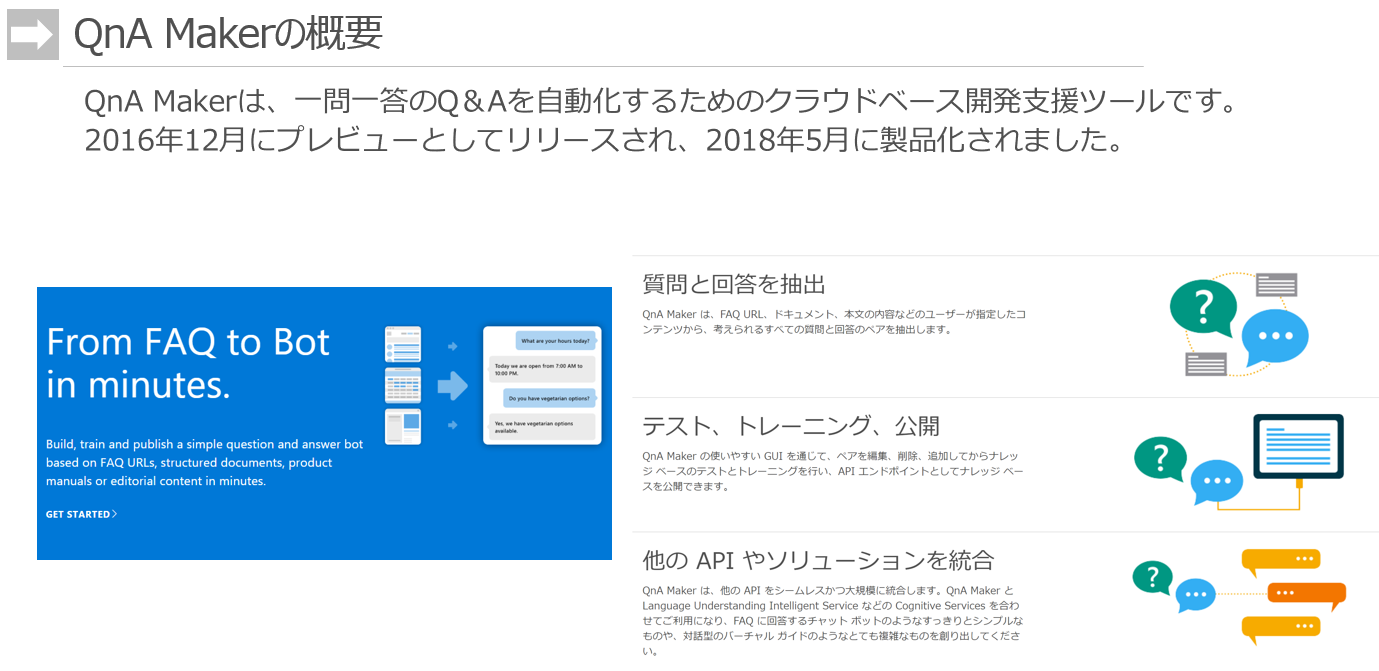
2016年生まれと、世に出てきたPreviewの頃から2年目くらいのサービスです。このサービスがでてきた頃は某社のWatsonが絶大な人気で、AIキーワードを牽引していた時代になります。そしてこの後しばらくして、チャットボットのための学習データの準備と、日々メンテナンスの大変さ、正答率を上げる大変さに気づき、幻滅期が始まりました。そういった大変さを打破するために、生まれたのがQnA Makerです。
そういった背景があって、トップページで語っているメイン機能は3つです。
-
質問と回答を抽出
- 要するに「学習データを作る支援ツールがあるので、楽になるよ」です。
-
テスト、トレーニング、公開
- 要するに「機械学習のデータモデルの作成と、アプリへのデプロイがテンプレートベースで、簡単にできるよ」です。
-
他のAPIやソリューションを統合
- 要するに「他のMS製品とイイ感じに連携するから、機能拡張が簡単にできるよ」です。
MSらしく「難しいことを簡単に提供する」って感じの製品ですね。
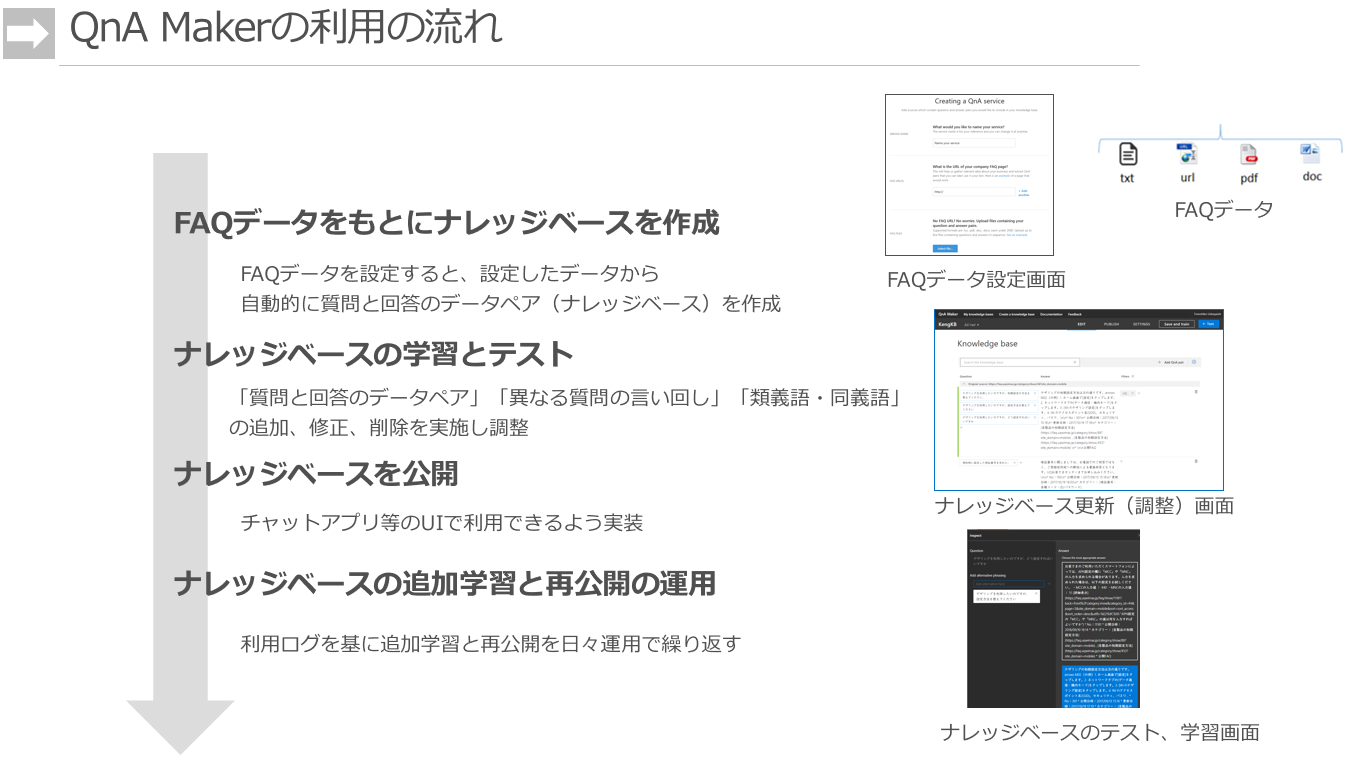
ナレッジベースと呼ばれる学習データを作成して、
学習データの整備(間違い削除、曖昧文章の修正など)をして、
データモデルを作って、アプリにデプロイ、
運用で集まったデータをもとに学習データを追加・修正し、改善していく。
まぁ、一般的なデータモデルの作り方の流れです。
もう今どきのAI系エンジニアには、違和感のない流れだと思います。

ここが、QnA Makerのすごいところ。
いままでチャットボットを作ったことある方は感じてもらえるんじゃないかと思いますが、インプットデータがこの3つというシンプルさは感動します。実装経験がある人ならFAQ自然言語分類エンジンにこの3つがインプットデータの最小セットであることが少し考えればわかるのですが、このあと、機械学習アルゴリズムのRNN系LSTMアルゴリズムとかに食わせるためには、かなりメンドクサイ加工処理をたくさんする必要があり、学習データ準備の疲弊ポイントになっています。それが、完全に製品がカバーしてくれています。
今からこういう製品使う人には、この大変さは気づかず使うんだろうな。。。なんか悔しいな。一回苦しいんでほしい。。。
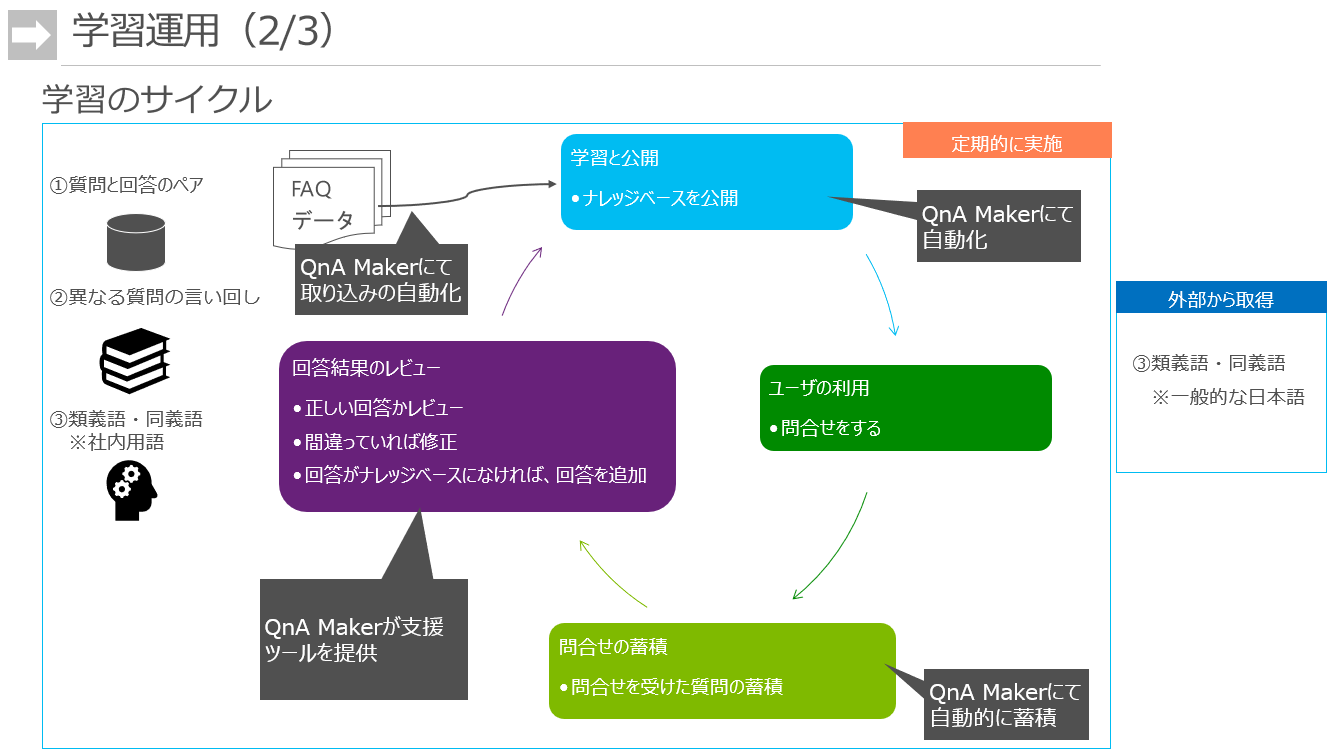
学習データを運用の中でメンテナンスしていくサイクルです。
ポイントは「回答結果のレビュー」。日々、ユーザが問いあわせたログを適切にレビューしていけば、正答率の改善および新たな内容の質問に対応していくことができます。

QnA MakerはFAQチャットボットを実装するためのキーテクノロジーですが、実際にチャット画面から使うためには、他の製品を組み合わせて実装する必要があります。
-
一番上のChannelの層
- UIを提供するツール群(TeamsやFacebook Messangerなど)
- アプリとUIを繋ぐインターフェース群。Bot Connectorと呼ばれる機能。
- LineとBot Frameworkを繋ぐインターフェースの開発を手伝ったことあるのですが、地味な癖にめちゃめちゃ開発が大変です。Lineもそうですが、Skype、Facebookなど、各自好き勝手に「インターフェースを作りすぎ」だし、各自好き勝手に「独自UIパーツを作りすぎ」です。そのクッションをするこのインターフェース機能は、めちゃめちゃ仕様決めも実装もムズイです。地味なのに難易度高いって、もっともやりたくない開発ですね、MSの開発がやってくれて良かったーと思う機能です。
-
二番目のBot Frameworkの層
- 会話フローを作るところ。ここはコードで書く必要があります。Bot Builder SDKを使い、Dialogでいうフレームワークで作る実装が僕は最適だと思ってます。
-
三番目のQnA Makerの層
- この層でQnA Makerにより自然言語分類を行います。
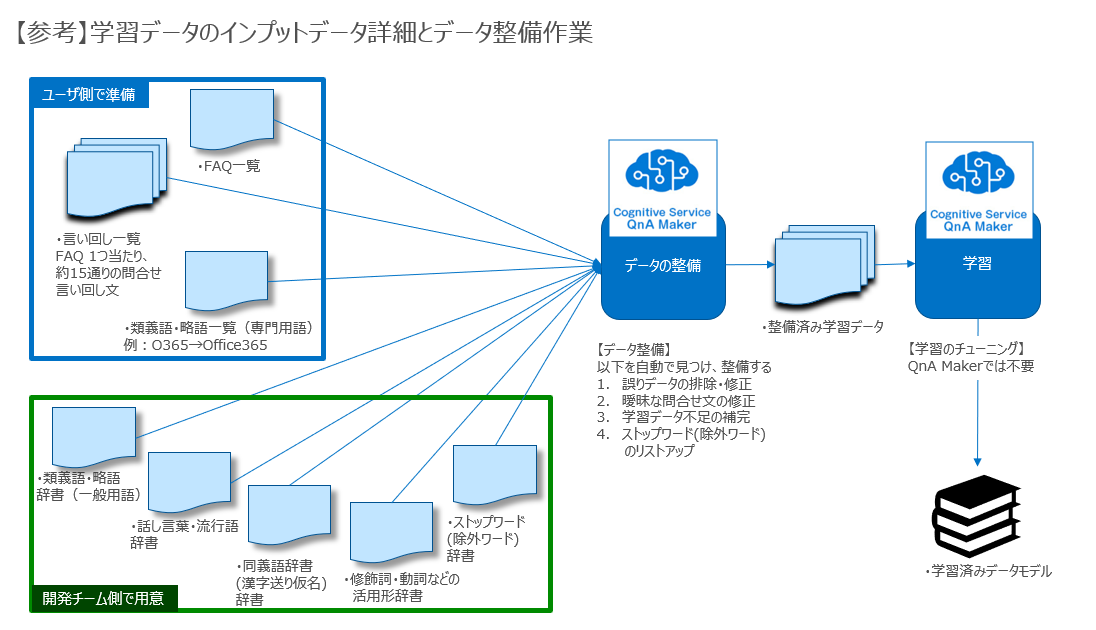
QnA Maker流の学習データについて
QnA Makerの紹介のところでは概念を説明しましたが、この章ではもう少し具体的な実装について説明します。
学習データの種類
QnA Makerの紹介で書いたように学習データは3種類あります。
①質問と回答のペア
②異なる言い回しの質問
③類義語・同義語
うち、「①質問と回答のペア」「②異なる言い回しの質問」はQnA Makerでは以下のようなEditor画面で管理されます。
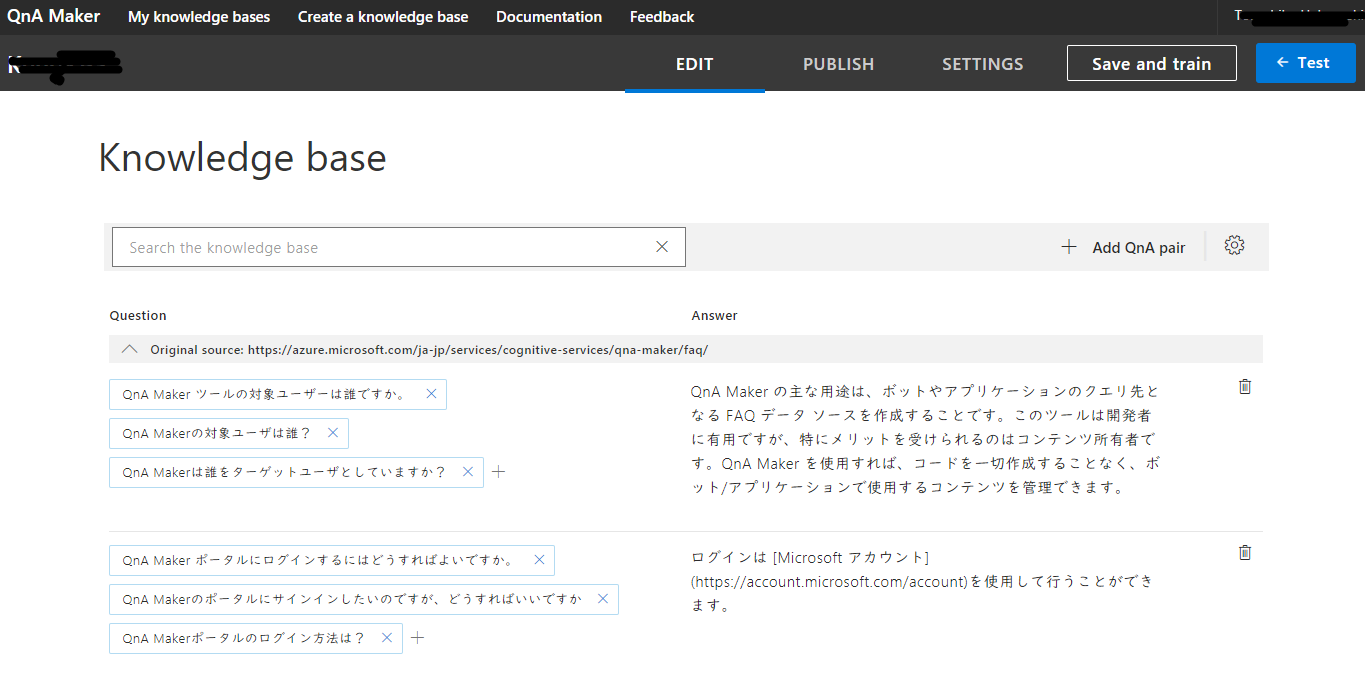
そして「③類義語・同義語」の入力は、なぜかQnA MakerにUIが用意されてないです。なので、RESTのPut要求で更新するしかないです。
↓以下はPostmanの画面ですが、こんな感じで類義語をJsonにまとめて書くと、データモデルが類義語を加味したScoreにしてくれます。
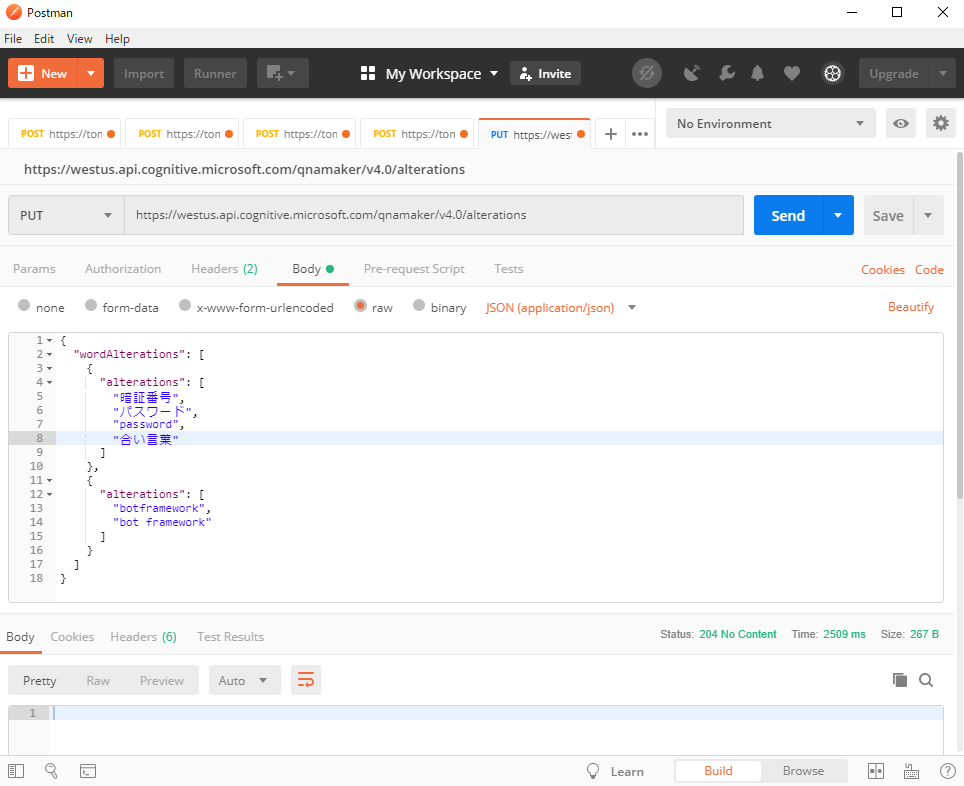
類義語のRestの説明ページはこのページ。全件置き換えのAPIなので注意。
学習データの作り方とチューニング方法
学習データの作り方
前章でも上げた3種類の学習データを作る時に僕がポイントとしていることを書きます。
-
「①質問と回答のペア」「②異なる言い回しの質問」を作成する際のポイント
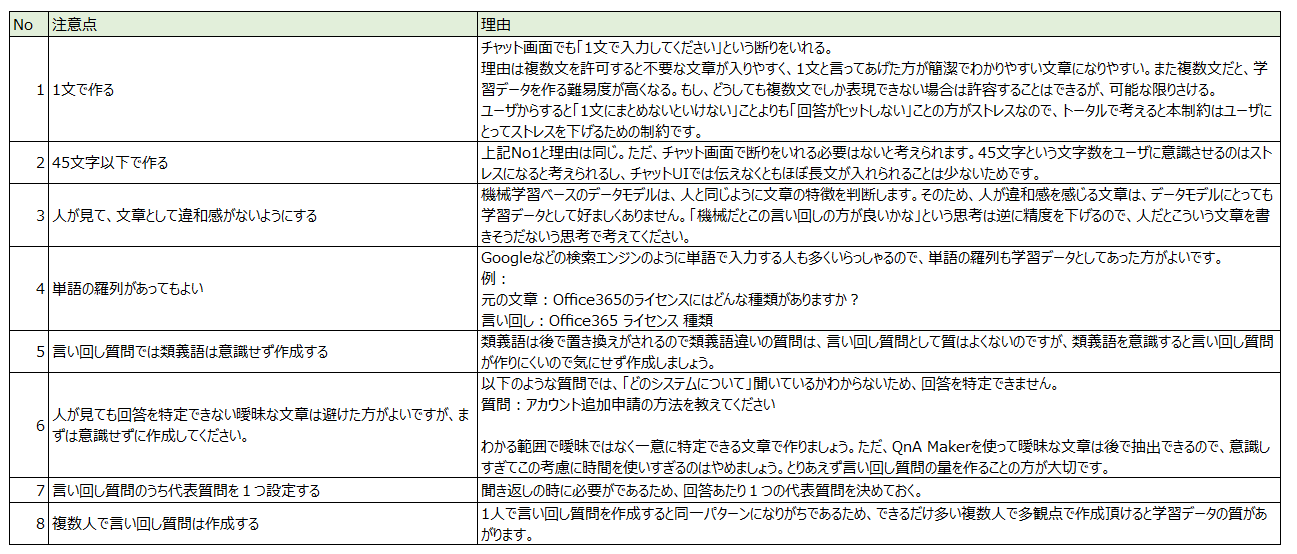
-
③類義語・同義語を作成する際のポイント
類義語・同義語は大きく2種類に分けられます。
(1)企業・組織内の内部用語
(2)一般的な日本語の類義語・同義語
ポイントは、「全方位的に類義語をQnA Makerにいれるのはやめましょう」ということ。
「①質問と回答のペア」「②異なる言い回しの質問」の文章の中にでてきた単語にのみフォーカスして類義語・同義語を用意する方が効率的です。
「全方位的に類義語・同義語」をまとめると、たぶん何万語レベルの数になるかと思います。
しかし、「①質問と回答のペア」「②異なる言い回しの質問」の中でってなると①と②で10000件くらい文章があったとしても、おそらく単語分解してた2000単語前後にしかならないはずです。そして2000語の中でも類義語・同義語の必要な品詞(名詞、動詞など)に絞れば、1000語もいかないと思います。その1000語の類義語・同義語を探しましょう。
その1000語を抽出するために①と②の文章を単語分解する方法
MecabかJuman++で形態素に分解して、Distinctでしょうね。辞書はmecab-ipadic-NEologdがおススメ。
Windows標準の形態素解析ツールは、日本語の辞書が弱いのであまりお勧めしないかな・・・
(1)企業・組織内の内部用語を作るための情報源
力技で組織内から探してくるしかないです。
(2)一般的な日本語の類義語・同義語を作るための情報源
前回の記事で書いた以下の辞書から、取ってくる。
いくつか以下に辞書書いてますが、「たんし」だけでも良い気がします。Word Netは情報量が多くていいのですが、扱いにくくて、、、。
辞書の取得
日本では国立機関や大学などで自然言語処理の研究がたくさん実施されており、そのアウトプットである辞書データが多く公開されています。そのため、有難いことにその辞書を利用させて頂くことができます。本当に感謝しています。以下は上から順にお勧めです。ライセンスに注意してご利用ください。
1. 同義語辞書・漢字送り仮名(例:借入、借り入れ → 借入れ)
2. 類義語・略語(例:O365 → Office365)
自組織内でしか使われない専門用語は自組織内で作るしかありません。しかし、一般的な類義語は外から取得できます。
学習データのチューニング方法
今回のような自然言語分類器のチューニングポイントは従来、2つでした。
1つが、学習データを整備するチューニング、
もう1つが、自然言語分類器の分類アルゴリズムのチューニングです。
しかし、後者の方はQnA Makerがカバーしてくれて、かつ品質が前出のとおり最高な品質なので、前者だけを考えればよくなりました。
-
学習データのチューニング内容(大きく3つ)
- 学習データの誤りを探して直す
- 学習データの中で曖昧な文章を探して直す。例:「サインインできない。」という文章は「どのシステムに?」という点が曖昧なので答えを一意に判断できない。こういう文章を学習データ内には入らないにする。
- 学習データが不十分なものを補完する。
-
それぞれの具体的なチューニング方法
- 「1. 学習データの誤りを探して直す」「2. 学習データの中で曖昧な文章を探して直す」は同じ方法です。
- 学習データと同じデータでテストする。つまりKBのQuestionを、問い合わせデータとしてQnA Makerに投げてAnswerとScoreを見る
- 通常、学習データと同じデータでテストをすると100%正解するはず。それでも正解しないもしくはScoreが95%以上じゃないっていうことは、学習データに誤りや曖昧があるということ。
- 学習データと同じテストデータで、正答率100%にあるようになったら、学習データを8:2くらいに分けて、それを学習データ8:テストデータ2として、テストする。いわゆる交差検証ってやつをします。
- 学習データと同じデータでテストする。つまりKBのQuestionを、問い合わせデータとしてQnA Makerに投げてAnswerとScoreを見る
- 「3.学習データが不十分なものを補完する。」
- 単純に1つの回答あたりの言い回し質問数が少ないすぎるものがないか確認する。僕の閾値としては1回答あたり最低10件以上、15件がベターで考えています。
- 「1. 学習データの誤りを探して直す」「2. 学習データの中で曖昧な文章を探して直す」は同じ方法です。
QnA Makerに大量の件数のリクエストを出すテストをするためのプログラムを作ったので、Githubに置きました。良ければどうぞ。※上で書いたのと同じです。
https://github.com/tomohikue/QAMakerRunner
学習運用について
初期FAQチャットボット作成時の学習データについて書きましたが、本番運用が始まってからもこの手のツールは、学習運用を回していく必要があります。理由は、以下の大きく2つかと考えています。
- まだFAQに加えられていない質問と回答を追加する
- 初期学習では正答率が上げ切れてなかった質問に対して追加で学習させる
FAQチャットボットの学習運用は、「かなり大変で運用できない」と言われることが多い領域だったと思います。今でもそこそこ大変なのですが、QnA Makerは一部自動化してくれています。
学習運用の手順
-
利用者の問い合わせログを蓄積させる。※この機能は上記で書いたとおり、QnA Makerは未熟な機能しかありません。なので自作が必要です。
-
ログを、運用チームが自由に参照できるようにする。 ※この機能もQnA Makerにはないので自作が必要です。Excelに落とせれば十分かと思います。
-
運用チームがログを見て、質問に対して、本当に正解を返しているか人が文章を読んで判断していく。(QnA Makerの結果のレビューをする)
- ログの数および運用チームで使える工数を考慮して、レビューする件数は決定する。
- もっとも良いのはログの全件レビューであるが、件数が多いと実現不可なので、「ユーザからのフィードバックボタン結果が悪かったもの」および「回答したScoreが低かったもの」から候補を抽出して効率をあげる
-
メンテナンス対象が決まったら、QnA Makerに学習データを追加する
- KBエディターの画面の赤枠のところのボタンから追加する

- 人が期待していた結果と違う回答をしている(誤り回答)を修正する
- QnA Makerのテスト画面を開き、利用者が入力した文言をコピーして、実行する。回答が返ってきたらInspectボタンを押すとメンテナンス画面がでてきます。 これ、割とシンプルで地味な機能ですが、便利です。
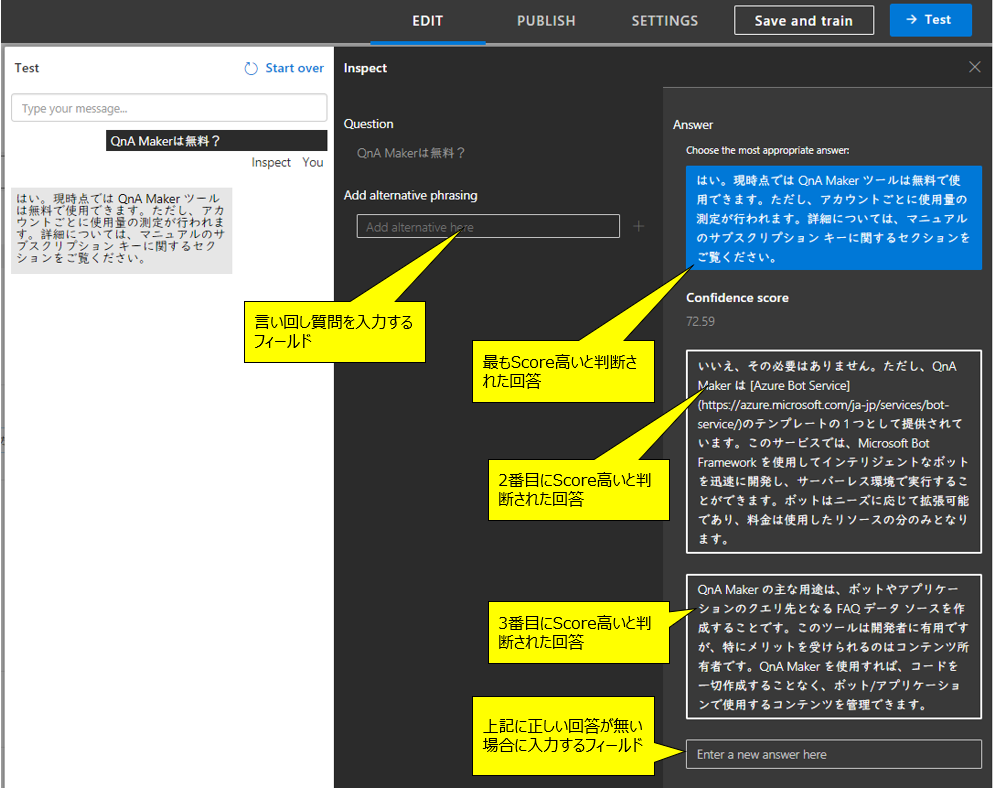
- QnA Makerのテスト画面を開き、利用者が入力した文言をコピーして、実行する。回答が返ってきたらInspectボタンを押すとメンテナンス画面がでてきます。 これ、割とシンプルで地味な機能ですが、便利です。
- KBエディターの画面の赤枠のところのボタンから追加する
-
類義語が増えたら追加する。 ※上記で書いた類義語追加のUIは提供されていないので、自作が必要です。
学習運用のところは、未だ機能がそろっておらず、自作する必要がある部分がややあります。QnA Makerの今後に期待です。
実装の例
1問1答を1問多答にして正答率を上げる
QnA MakerとAzure Bot Service連携は、最短でベースのチャットボットを作ることができる良いテンプレートです。
・参考サイト
https://docs.microsoft.com/ja-jp/azure/cognitive-services/qnamaker/tutorials/create-qna-bot
しかし、それはとんでもなくシンプルすぎる実装です。
↓こんな感じです。
①質問を入力
②回答だけをダイレクトにBotが送ってくる
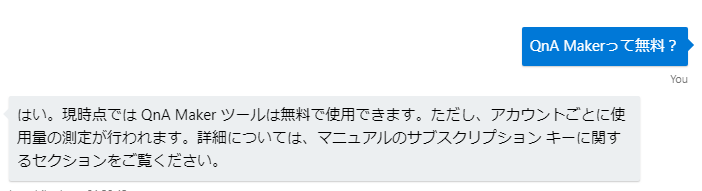
予測のScoreとか完全無視して、回答を1つだけ返してきます。Scoreが90%以上で、ほぼ必ず正解している回答であれば、これも有りかもしれませんが、Scoreが1%だったとしてもこの返し方になる実装は実用的ではないですよね。なので、実用的には以下のようになると思います。
①あいさつ
②質問を受ける
③Scoreが閾値を超えたものだけを複数選択で出す
④選択してもらう
⑤フィードバックをもらう
↓こんな感じ
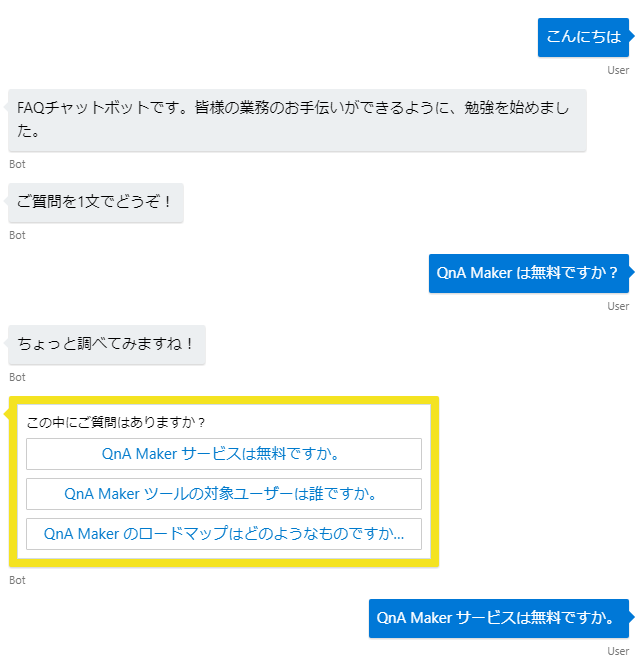
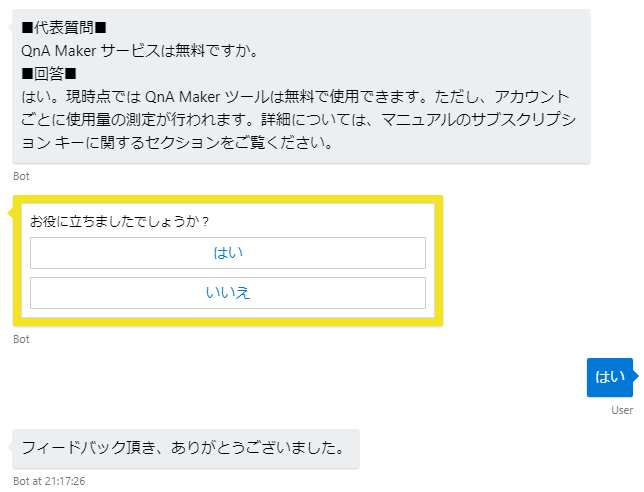
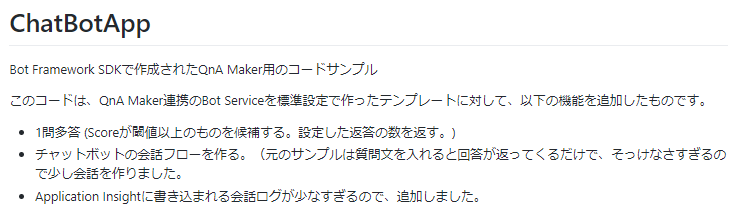
この動作をするコードをGitHubにおいてます。よければどうぞ。※上で書いたのと同じです。
https://github.com/tomohikue/ChatBotApp
UIの実装例。FAQボットはチャットUIがベストではない!(と思う)
FAQボットっていうと、なぜかチャットUIっていう先入観がある人が多いように思うのですが、僕はそのUIに非常に疑問を感じ続けています。なぜなら、会話なんていいから最短で回答がほしいなと思ってしまうからです。前章のように「あいさつ」とかいらんし、余計な入力したくないでなと思うんです。
「親近感をもってほしい」とかそういう理由ならチャットUIもいいかもしれないのですが、社内利用とか実用性重視の場合はチャットUIは適してないんじゃないのって。
そしてこんな感じのUIを考えてみました。
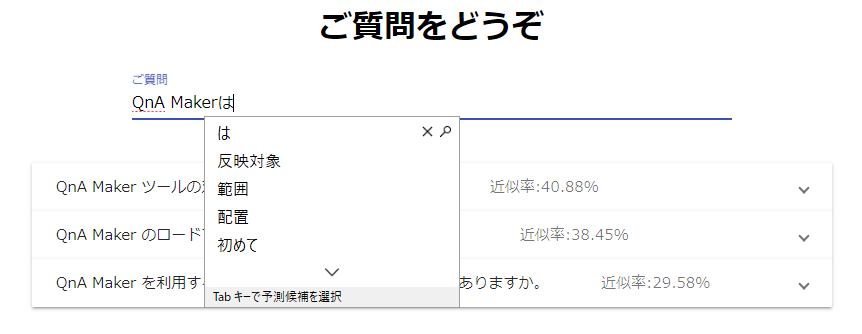
入力している途中に1文字打つたびに結果を取得して、Scoreの高い順に表示させていくUI。
そして、結果をアコーディオンで表示させて回答へたどり着くための速度を上げる。
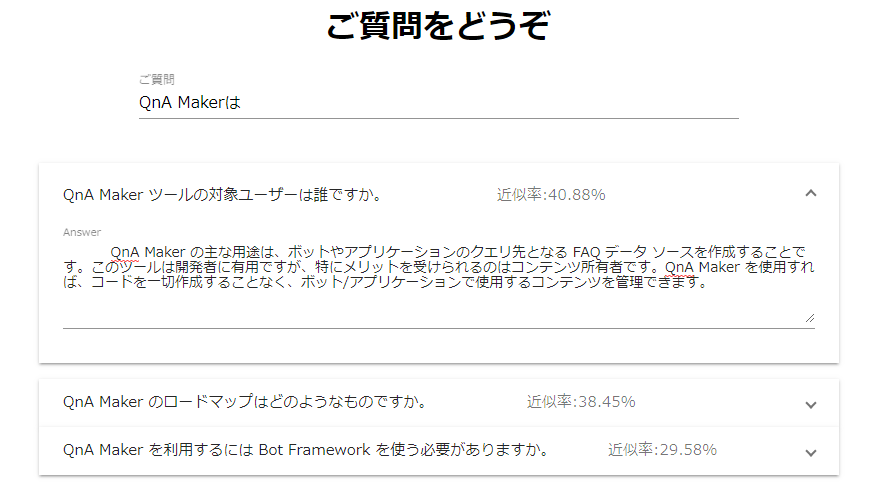
このUIのメリット
- 全文入力する必要がない
- 入力した文字が残っているので書き換えやすい。チャットUIは、書き換えにくく打ち間違えるとストレスを感じる。
- 無駄な挨拶などがないので、とにかく答えまでが早い
デメリット
- ユーザが入力を全部行ってくれないため、学習データをログしにくく、追加がの学習データが作りにくい
- AIっぽさがなく、新しさがない。なんかいままの検索みたいで野暮ったく感じられてしまうことが多い
デメリットの2つが強すぎますね。特に「ユーザが入力を全部行ってくれない」というのは、運用でどんどん学習を続けていく必要があるこのシステムとしては致命的じゃないかなと思います。ということから考えると、全員はこのUIにしない方がよくて、プレミアムユーザだけにするとかじゃないかと思います。
このUIのコードをGithubに置いてます。よろしければ。
https://github.com/tomohikue/AutoSuggestFaqUI
Appendix
その他、気になって調べてみたこと
- 一般的な類義語は、何も入力しなくてもすでに学習してくれているのか
- 動作をみたところだと、学習してくれてないようです。今後に期待ですね。
- アンサーの文字列も、Scoreの重みづけに使っているのか
- 動作をみたところ、重みづけは低いがScoreの重みづけ対象に入っているようです。
- 名詞と動詞、助詞など、品詞ごとに重みづけを変えているか?名詞の方が重要そうだからScore上げるなど。
- 動作をみた感じだと、品詞では区別してなさそう。でもこれは自然言語分類器はどれでも同じで、品詞ではなく単語の頻出度合いで調整されていると考えられる
- QnA Makerの裏側になるAzure Searchで日本語のワードブレイクがされているようだが、どんな感じにワードブレイクしているのか知りたい
- このツールを使わせてもらうと手軽に確認できます。
INPUT: 契約時に設定した暗証番号を忘れた。
TOKENS: [] [契約] [時] [設定] [し] [た] [暗証] [番号] [忘れ] [た]
- Azure Searchで使われているワードブレイカーの辞書がいまいちそうなんで、QnA MakerのKBに入れる前にワードブレイクした方がいいのか
- 外でワードブレイクしても、中でもう一度ブレイクされるので、意味なさそう
- 外で 「暗証番号」 で固まっても、中で 「暗証 番号」と分解されてしまう。逆に外の方が短く分けるべき時は有効だが、日本語にはあまりそういう言葉はないので。
- 外でワードブレイクしても、中でもう一度ブレイクされるので、意味なさそう
- そもそもワードブレイクが正確にされる必要があるのか
- おそらくQnA Makerの中で使っているであろうRNNアルゴリズムでは順序性を意識しているはずなので、ワードブレイクの精度は高くなくてもいいのではと思う。ただ以下で書く類義語の置き換えについては、正確なワードブレイクが必要そうな気がする。
- あれっ?類義語ってどうやって置き換えてるんだろう
- QnA Makerに類義語を与える時、「暗証番号」と1単語で入力しても「暗証 番号」とスペースを与えて入力しても結果は同じだった。ということは、類義語・同義語の置き換え前にトリムをしている?僕が類義語・同義語の置き換え処理を実装した時は、ワードブレイク後の単語どおしで完全一致したものを置き換えるという方式をとっていた。しかし、「暗証番号」「暗証 番号」の結果を見ると違うやり方をしてるようですね。
- 次に考えられる類義語・同義語の置き換え方法としては、トリムした状態で全文の中からリプレイスをしているのではないかと思われる。
- この場合、「お借入=キャッシング」っていう類義語があり、「ATMでお借入れできます」という文章を置き換えると「ATMでキャッシングれができます」となり、正しく置き換えることができないパターンが日本語ではたくさんでてきます。
この投稿中で書いたコードのまとめ
以下3つ。すべてGithubに配置しています。

おわりに
今、NHKで放送されている「人間ってナンだ?超AI入門」という番組が好きで毎週めちゃめちゃ楽しみにして見ているのですが、その中で印象に残ったことがありました。正確には覚えてないのですが、カナダのAI技術の権威の方が、「現在のニューラルネットワーク技術で実現できていることは脳でいうとホンの小さな欠片くらいのことで、人間の脳はその10万~100万倍の大きさです」という趣旨のことを言われてました。このメッセージを聞いて、僕は単純にすごくワクワクしました。だって、現状のニューラルネットワークの仕組みでさえもこんなに複雑なのに、それをまだまだ100万倍複雑にしないと人の複雑性に追いつけないということだから(正確にはいろいろ違うかもしれないですが)。まだAI系の技術の底はまだまだ深いということが知れた気がして嬉しかったです。これがもし、「もう人の脳の仕組みの半分が解明されているんです」って言われたら、なんか底が見えた気がして寂しいですよね。
FAQチャットボットはこの先、普及していくんでしょうか?ここ数年、僕個人的にはよく考える事なんですが、「明確な理由はないですが利便性を試してみた感覚から、普及するとは思えないなー」という結論にいつも至ります。しかし、「FAQの自動化」は間違いなく普及すると思います。でも、チャットというUIでなのかというと違う気がしています。チャットボットのように明らかにAIっぽい実装というのはだんだん減っていき、今ひそかに流行り始めている「さりげなくAI」という形で、自動FAQも実装されていくという方がピンときています。「さりげなくAI」とは勝手に言葉作りましたが、従来の洗練された仕組みの中にこっそりアドインされていくタイプのAIです。例えば、Google検索って昔からUI変わらないですが、なんかいつの間にかスゴイ技術が入っていたりします。そんな感じです。自動FAQはどんなUIが正解なのかはまだ世の中にちゃんとした正解がないと思っていて、それは探しがいのある面白い課題です。QnA Makerのように頭脳の部分は実用性が高まってきたので、次はUIが洗練されていくんじゃないかと予想しています。
今回現状は、まだまだ流行っているFAQとチャットボットの組み合わせを検証しましたが、次の僕のテーマとしては「QnA MakerをFAQの自動化以外に使ってみる」「FAQの自動化をもっと適したUIに溶け込ませてみる」、「人の回答を超えるFAQボットを作るためにはどうすればいいか考えてみる」あたりをやっていきたいなーと考えています。
2018/12/27 追記
この投稿を書いた半月前はしばらくはUIが洗練されていって、頭脳の部分はまだしばらく時間がかかるのかなと思っていたのですが、予想に反して頭脳についても次のステップに進むであろう研究成果が発表され始めている模様。GoogleのBERTと、MicrosoftのBig Bird(ともにセサミストリートのキャラ名、対抗意識バリバリですね)。このあたりの技術は汎用自然言語モデルの実現が期待できるらしく、この投稿で書いた「言い回し質問」と「類義語」の作成手間が大きく削減されそう(ちょっとこれらの技術への理解度がまだ低いので、断定できないです。。。)。そうなると、FAQだけ入れれば、ユーザのいろんな言い回しに対応してくれるようになるってことですね。すげぇな、それができると会話中に直観的に相手がすごく賢い存在のように感じられそうです。研究室からでて、製品に組み込まれるのも、最近の感じだと1~2年後くらいですかね。楽しみです。
・この領域のリーダーボード ※GoogleのBERTとMicrosoftのBig Birdの競争が面白い
https://gluebenchmark.com/leaderboard