はじめに
MicrosoftのDeep Learningツール(Cognitive Toolkit)を使った自然言語分類技術を、機会あって本気で実装したので共有しようと思います。
今回のテーマは自然言語分類技術としていますが、もう少し具体的にいうと
自然言語の質問文に一問一答形式で回答するチャットボット
です。「チャットボット」という言葉でも少しイメージが広くなってしまうので、今回は「ヘルプデスクの代替として使う問合せチャットボット」に限定します。本投稿ではQAチャットボットと呼ぶことにします。具体例としては、こんなやつ。
こういうQAチャットボットは2016年ごろから流行り始めていくつかのサービスが開始され、今では目新しさは無くなってしまいました。最初はAIというトレンドキーワードの力を借りて、サイトの賑やかしとして意味を持っていましたが、あまり一般の方の生活の中に普及しているとはいえない状況になっているというのが現状ではないでしょうか?
でも、なぜ普及しなかったんだろう?
おそらくいろんな意見があると思いますが、僕は正答精度と運用コストだと思います。結局のところ正答精度がよければ、電話とかFAQで調べるより楽だし、営業時間外でも聞けるし、人相手より気軽に聞けるので、便利なはずです。2016年から作られだしたボットは、聞いたところ精度が30%前後くらいらしいです。それだと聞くだけ無駄だって思ってしまいますよね。あともう一つは、QAチャットボットを運用するコストが減らせず、投げ出してしまった開発チームをいくつか見ました。
しかし、対してUSのMicrosoftやFacebookやGoogleなどのテクノロジーの動きを追っていくと、すでにQAチャットボットは最新テクノロジーとして扱われてません。すでに最新落ちした「当たり前」の段階に入ったテクノロジーのように扱われているように感じます。つまり、彼らのソフトウェア開発チームや研究所レベルではすでに使い物になるレベルに達していて、「もう飽きたよ」って雰囲気です。
この違いはなんなんだろうって考えました。
きっとこういうことだろうと僕は思いました。
・USのハイレベルなエンジニア間ではすでに使い物になる正答精度と運用コストとして認識され扱われている
・企業で開発している現場ではその技術が吸収できておらず、高い品質&低い運用コストで提供できていない
たまたまQAチャットボット案件に誘われたこともあり、この仮設を確認すべく、
かなり本気でQAチャットボットを実装しました。
そして僕の結論としては、
高い正答精度&低い運用コストは、すでに現場で実現できるレベルまで進んでいる
です。
この投稿で書くこと
検証を始めた時点(2017年8月)のQAチャットボットテクノロジーで、どれだけ高い正答精度&低い運用コストが実現できるか検証した結果の共有。今回検証した仕組みは私一人で作ったものでもないし、また弊社内でソリューション化して外販するようなのでチューニング済みのコードは共有できないのですが、チューニング前のサンプルコードは共有します。あと、実装の考え方、扱うテクノロジーの基本的な使い方を書きます。後ろの章で説明しますがチューニング前のコードであっても多くの業務に耐えれるレベルの正答精度は出せるののではないかと考えてます。
利用するDeep Learningテクノロジー
自然言語分類器の実装に使う Deep Learningテクノロジーの選択肢としては、GoogleのTensorFlow、PFNのChainerあたりも候補に考えたが、僕がMicrosoft寄りというのもあり Microsoft Cognitive Toolkit でQAチャットボットで検証しました。
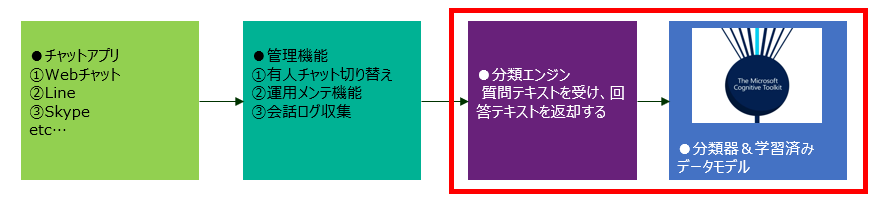
対象とするシステム範囲
システムの実行環境全体をイメージ化すると以下のようになります。今回はそのうち、赤枠のところだけ触れます。赤枠以外のところは、世の中に情報が多くあるという点と業務要件によって考え方が大きく変わってくるところなので今回触れません。
投稿する目的
テクノロジーを開発する方々が努力されてQAチャットボットが実用レベルになっているにも関わらず、日本では「使い物にならない」イメージが先行して普及していないのは悲しい話だなと思いました。私が説明するのは数ある実装パターンのうちのほんの1例でしかないのですが、理解を深めてもらい、QAチャットボット普及の一助になれば嬉しいなと考えています。ある程度のレベルまで質の高まったテクノロジーはさっさと普及して次のさらに高度なテクノロジーに進まないといけないと思います。
QAチャットボットのメリット
QAチャットボットが本当に役に立つのか疑問だという旨を、僕自身が1年半前にした投稿で書いたのですが、いくつかチャットボット案件を経験した今では自信持って言えます。
「チャットボットは役に立ちます」
もちろん使いどころが大事ですが、ヘルプデスクの代替としての一問一答チャットボットの業務シナリオでは、次のようなメリットがあります。
- 大手企業だと500人以上のヘルプデスク人員がいます。ヘルプデスクへの問合せのうち約7割がQAチャットボットで対応できる類の質問なので、ざっくり言って半数くらいは人員を削減できます(例えば1人あたり年収400万円の人が250人減れば、1年あたり10億円コスト低減できます。)
- 顧客満足度の向上
- 電話だと取ってもらえず問い合わせ自体を諦めることが全体の~3割ほどあるらしいです。電話を取ってもらえないイラっと感がなくなります。
- 24時間365日対応できる。営業時間じゃない時に電話できないというイラッと感がなくなります。
- 電話で聞くのって時間と場所を選ぶのでめんどくさい。待ち時間が長いし、回答が遅い。電車の中だと電話できない。
- 若者世代は電話自体に特に慣れておらず、気が重いのでチャットのほうがストレスが無い
一般の利用者はまだ慣れてないからすぐに電話で問合せをしてしまいがちですが、世の中にQAチャットボットが多くなってくると絶対QAチャットボットの方が便利だと僕は思います。
また、次の記事のように「声での電話問合せ」が身体的な問題で難しい方も、より良いコミュニケーションが実現でき、社会がより豊かになるのではと期待もあります。
https://toyokeizai.net/articles/-/212281
対してデメリットは以下のような点だと思います。正答精度は高い前提で考えます。
- 開発や運用のテクニカルな難易度が未だ高い
- 一問一答ができるのであれば、チャットが最も良い手段ではないのではないか?という話し。例えば、インテリジェンスな検索ボックスでもいいのでは?とか、アマゾンエコーやグーグルホームで音声ベースの方がいいのではないか?とか。これは僕もずっと疑問に感じている点で、いろいろ試してみる価値はあると思う
- (お爺さん的な発想でいうと)人とのコミュニケーションの機会が減るので、若者のコミュニケーション能力が低下するんじゃないかと思う
僕の頭が固くなってしまっているのか、あまりデメリットがでない・・・。正答精度が高い前提だと、あんまりデメリットないのでは???
正答精度の実績
2種類のテーマで奮闘した結果、こんな感じでした。
評価方法
- 自然言語で入力された文章(1文かつ50文字以内に制限)をデータモデルに渡し、返された回答文が人の判断と同じであるかを確認する。
- データモデルから確立の高い順に複数回答候補が返される場合がある。その場合は確率のトップ3のいずれかが正しければで正答としてカウントする。
※注意
今回のQAチャットボットは回答文を自動生成せず、事前に用意された回答文を返します。そのため、回答が用意されていない質問には答えられません。
テーマ①
ヘルプデスクへの問い合わせを代替するQAチャットボット。現行のQAチャットボットシステムがなく、質問と回答のログがないため、データは人力で検証用に作成。
正答率: 95%
※確率のトップ1のみが正しい場合の正答率は88%。
| 評価条件 | 値 |
|---|---|
| 質問と答えペアの数(分類するクラス数) | 100件くらい |
| 質問文 | キーボート入力での自然言語 |
| 精度評価の方法 | モデル作成者に隠しておいた質問データ50件をモデルに当ててその正答率を測る |
テーマ②
こちらもヘルプデスクへの問い合わせを代替するQAチャットボット。
ただし、回答できる質問と回答のペアを①の10倍の1000件にする。
こちらはすでに既存のQAチャットボットがあり問合せ履歴があるため、よりリアルな問合せメッセージで評価した。
評価方法①の正答率: 95%
評価方法②の正答率: 80%
評価方法③の正答率: 30%
| 評価条件 | 値 |
|---|---|
| 質問と答えペアの数(分類するクラス数) | 1000件くらい |
| 精度評価の方法① | モデル作成者に隠しておいた質問データ50件をモデルに当ててその正答率を測る |
| 精度評価の方法② | 既存QAチャットボットの過去履歴から、ランダムに抜いた質問200問をモデルに当てて、正答率を図る。※ただし、日本語として意味をなさない質問文は省く |
| 精度評価の方法③ | あまり多くは聞かれない意地悪な質問文をモデルに投げかけて、正答率を図る |
精度としては、まずまずな成果が出せたように思う。
まだまだ改善できる施策案はあるので、まだ精度向上の見込みはあると思っている。
この領域は、世の中に情報が少なく未開拓な部分が多いので、やればやるほど改善案が見えてきました。1つ改善すると、次の改善点が見えてきて、また次に進むと・・・というサイクルを繰り返し、数でいうと20以上の改善施策を行って上記の精度まで上がりました。
自然言語の分類手法
分類手法を理解するためには実際の実装を見た方がわかりやすいと思うので、元データからCognitive Toolkit(CNTK)に渡すTraningデータを作成するまでの流れを示すことで説明します。
データ加工の流れ


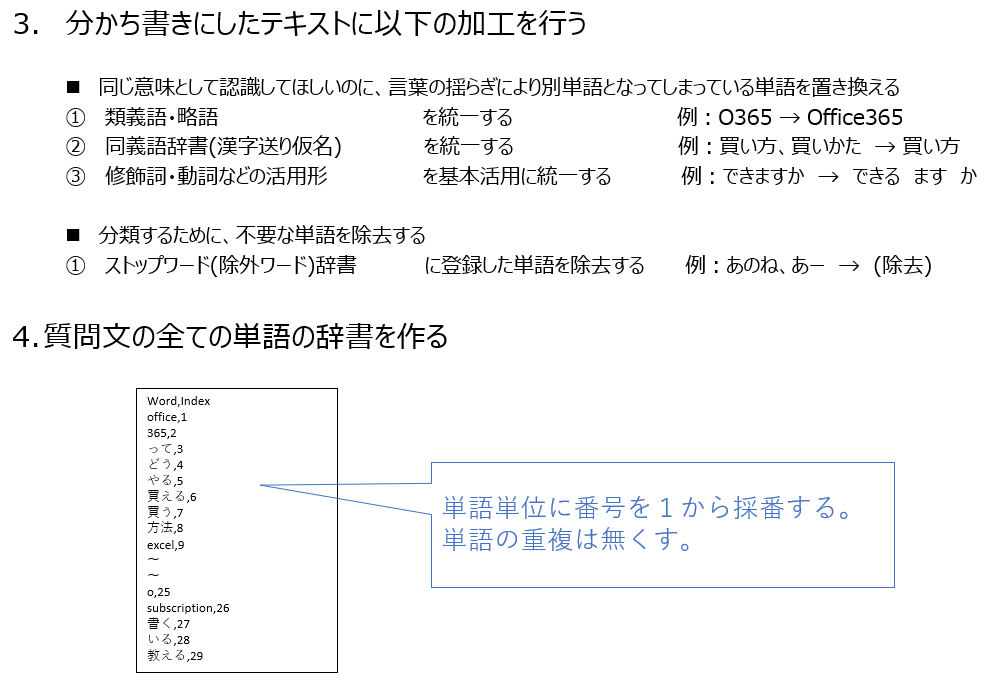
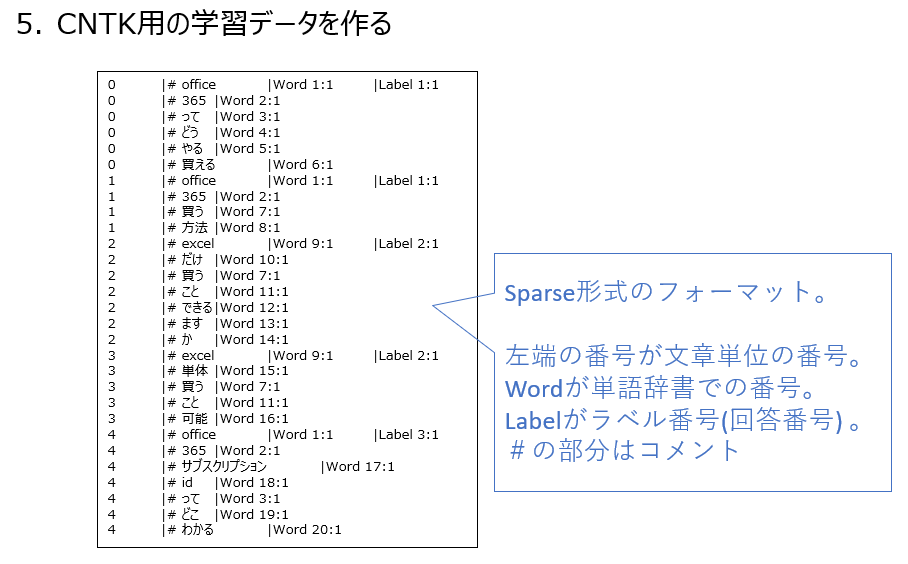
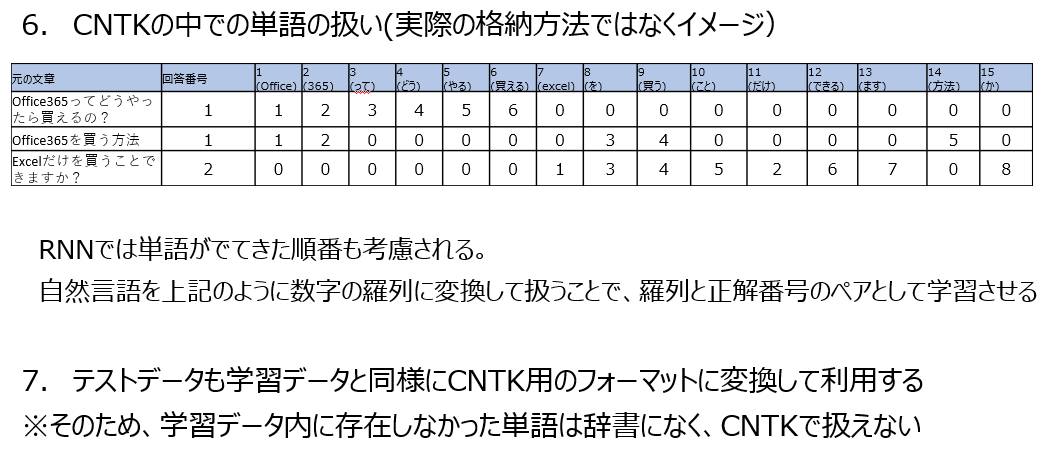
自然言語分類器の作り方
実装工程
自然言語分類器を実装工程は次のとおり。
- トレーニング環境を作る
- チューニングして精度を上げる
- 学習データの整備
- Training処理のチューニング(Deep Learningのニューラルネットワークコードの改善)
- 類義語・同義語
- アプリでモデルを使う
最も重要かつ複雑な工程は、チューニング工程です。これがうまくできるかで、正答精度が変わるのでアプリの利用価値に直結します。
1. トレーニング環境を作る
1.Microsoft Cognitive Toolkitをインストールする
バージョンは2.3で動作を確認しています。
インストールが終わったら環境変数が設定され、PowerShellで「cntk」と打ってCNTK.exeが実行されることを確認してください。
・言語
Training処理で使う言語は、Python版とBrain Script版(このツール独自言語)の2種類があるのですが、今回はBrain Script版を使ってます。しかし、Cognitive Toolkitはバージョン2になってからPython対応し、Pythonを強烈に推しているようなので今後新規でゼロから勉強される方はPythonの方が良いかもしれません。僕はPython版でも書いてみたのですが、このツールに関してはBrain Scriptの方がわかりやすいなーという気がします。独自言語ってのは該当の処理内容に最も適した形で作られるのだから、わかりやすく無駄がなくて良いです。
・GPUモード
Cognitive Toolkitは「CPU版」「GPU版」「1bit GPU版」の3つモードがあります。1bit GPUが一番早いようですが、試してみたところだと1台でTrainingする規模ならGPU版と変わらないです。通信量を減らす技術らしいので複数のマシンで並列するときにその能力を発揮するんだと思いますが、今回は1台でやってるので効果は感じれませんでした。ただ、CPU版とGPU版の違いは歴然で、10倍くらい処理時間が違います。トレーニングデータが約1000件くらいだとCPU版では処理時間が5分くらいですが、GPU版だと30秒くらいで終わります。これが10万件になると500分(CPU)と50分(GPU)の差なので、GPU版が使えるマシンはほぼ必須だと思います。また余談ですが、Nvidia製のデータセンター版GPUであるTeslaはハイスペックなモノを使っても、いまいち速度がでませんでした。理由はわかりませんが、ゲーミングマシンに入っているGeforce 1060が最速でした。なのでお勧めはゲーミングマシンです。
2.自然言語分類のためのBrain Script
Microsoftが提供するサンプルを使うか、僕が作ったサンプルコードセットをご利用ください。Microsoftが提供するサンプルは、少し書き換えないと動作しなかったり、サンプルデータがなかったりするので、手っ取り早く試したい人は僕の作った方を使ってもらうのが早いです。
1.Example のBrain Scriptコードをダウンロード
MicrosoftがCognitive Toolkitのサンプルとして提供してくれている自然言語分類を行うコードをダウンロードして構成する。
https://github.com/Microsoft/CNTK/blob/master/Tests/EndToEndTests/Text/SequenceClassification/Config/seqcla.cntk
2.サンプルコードセットをダウンロード
僕が整理したサンプルです。最低限必要な Power shell スクリプトやサンプルデータも含めています。ただし、サンプルコードはMicrosoftが提供しているバージョンのものです。上記の検証でチューニングした後のものではありません。
2. チューニングして精度を上げる
実装工程のうち最も重要かつ工数がかかるのがチューニング工程です。
チューニング前の正答精度は40%くらい
正確に実績値を取っていなかったのでやや感覚値ですが、以下の2つで100%になります。
| チューニング内容 | 精度への影響 | 工数実績 | コメント |
|---|---|---|---|
| 学習データの整備 | +45%くらい | テーマ①で50時間。テーマ②で150時間。 | Cognitive Toolkitを使って効率よく進めないと工数が膨大にかかるので注意。「質問と答えペア」の数が増加するほど工数が指数関数的に上がっていく。また複数人で手分けしにくく1人で行う必要がある。 |
| Traininng処理のチューニング | +15%くらい | テーマ①で50時間。テーマ②で0時間。 | 1度チューニングできれば似たタイプの分類では流用できる。パラメータチューニングは手動ではやらず自動でできるようにアプリを組んだ方が圧倒的に効率が良い。 |
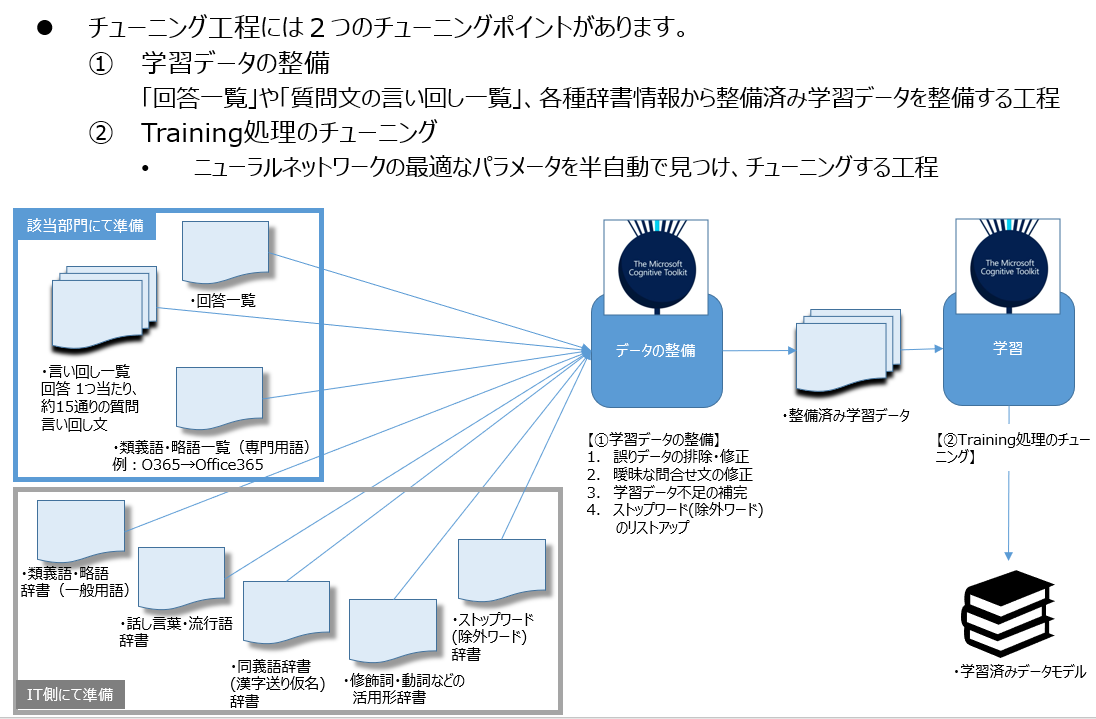
学習データの整備
以下の4つを行います。特に上2つが重要です。
- 誤りデータの排除・修正(質問文と回答のマッピングが間違っている)
- 曖昧な質問文の排除・修正(質問文と回答のマッピングが曖昧、複数に対応づく)
- 学習データ不足の補完(質問文にと回答のペアが少ない。10件以下)
- ストップワード(除外ワード)のリストアップ
1と2の効率良いの良い進め方
- 学習データをそのままテストデータにする
- 学習データでデータモデルを作る
- 学習データをそのままテストデータして予測する
- 予測が外れた「質問と回答のペア」を、人力でチェックし、修正する
- 学習データの7割を学習データ、3割をテストデータに分割してテストする(交差検証)
- 学習データの7割を学習データ、3割をテストデータに分割する。この時、分割がまんべなく思われるように専用のRやPythonなどのツールや関数を使う。
- 7割の学習データでデータモデルを作り、残り3割で予測する。
- この1と2を30回くらい繰り返す。データの分割は毎回バラバラになるようにする。
- 結果を集計して誤り回数が多い「質問と回答のペア」を、人力でチェックし、修正する。
上記の方法で行うと、学習データの約2割~3割くらいを人力でチェックすると、データが整備できます。
ポイントは人力のチェックは、時間がかかっても1人で行うことです。かなり複雑な質問と回答のマッピングになってくるので、マッピング精度を上げるためには1人の頭で全体を理解するしかありません。
3の効率良いの良い進め方
単純に「質問と回答のペア」が少ないものを補完します。
4の効率良いの良い進め方
ストップワードは、効果薄いので優先順位は最後でよいと思います。
Training処理のチューニング
Brain Scriptを修正してニューラルネットワーク処理を変更するチューニングです。これは難易度の高い領域です。
サンプルコードではRNN系のLSTMを使っていますが、GRUに変えたり、層ごとのノード数を変えたり、Epoch数やBatch Sizeを変えたりします。
ただ、このチューニングポイントは15%くらいの向上しかしないので、それ以外ができれば回答精度80%を超えてきます。
なので後回しにするのも手かなと考えられます。
各辞書について
辞書を使うことにより、多くの単語単位の言い回しに対応できるようになります。ただ学習データの言い回しが充実していれば、既出の単語を含む文章の正答精度はそれほどあがりません。つまり、分類器開発中のテストではあまり効果が見えません。辞書を使うことの大きなメリットは既出でない単語を含む文章への耐性です。分類器開発チームが想定できる文章の言い回しなんて、実際の運用時に入力される文章のレパートリーに比べると本当に一部でしかありません。例えば、「貸し出し、貸出、貸出し、貸しだし」など、日本語では送り仮名があまり統一されていないので辞書を当てないと違い送り仮名に対応できなくなります。よって、評価で正答率の数字を高く見せたいだけなら辞書はいりませんが、本気で運用で使うためには必須です。
辞書を扱うために使うツール
形態素解析エンジンMecabがお勧めです。僕は辞書からの文字列置き換えはMecabを使いました。JUMAN++も気になってましたが、Windowsで使うのが難しく試せてません。
辞書の使い方
Mecabの辞書に加えます。以下のようなフォーマットで入れて、右から3番目の項目を使うと、標準化された単語が取れます。
右から3番目の項目は動詞や修飾語の場合、活用基本形なので、活用が戻された単語が取れます。
また、左から4つ目の項目を-10000にしておくとこの行が優先されます(優先されない時もあるので注意。)
メアド,0,0,-10000,名詞,固有名詞,用語,*,*,*,メールアドレス,めーるあどれす,めーるあどれす
メール,0,0,-10000,名詞,固有名詞,用語,*,*,*,メールアドレス,めーるあどれす,めーるあどれす
ヤバイ,0,0,-10000,名詞,固有名詞,用語,*,*,*,やばい,やばい,やばい
やりかた,0,0,-10000,名詞,固有名詞,用語,*,*,*,やり方,やりかた,やりかた
辞書に入れる順番で優先順位が変わるので順番も注意。「Web」「Webサイト」を「Web Site」に置き換える辞書にいれて「Webサイト」の文字列を入力すると、「Web Site サイト」と出力される場合がある。これは「Webサイト」で置き換えられず「Web」が優先して置き換わったためです。
辞書の取得
日本では国立機関や大学などで自然言語処理の研究がたくさん実施されており、そのアウトプットである辞書データが多く公開されています。そのため、有難いことにその辞書を利用させて頂くことができます。本当に感謝しています。以下は上から順にお勧めです。ライセンスに注意してご利用ください。
1. 同義語辞書・漢字送り仮名(例:借入、借り入れ → 借入れ)
2. 修飾詞・動詞などの活用形(例:会った、会い、会え → 会う )
- Mecab IPA辞書 Mecabに標準搭載されている辞書
3. 話し言葉や流行り言葉(例:チョベリグ、インスタ映え )
- mecab-ipadic-NEologd これはほぼ必須の辞書。この辞書を作る仕組みを作った人すごすぎです。
3. 類義語・略語(例:O365 → Office365)
自組織内でしか使われない専門用語は自組織内で作るしかありません。しかし、一般的な類義語は外から取得できます。
4. 分類するために、不要な単語を除去する・ストップワード(除外ワード)辞書(例:あのね、あー)
世の中的によく使われるといわれるストップワード辞書。
ストップワードについてはたくさん検証したんですが、僕としては入れない方がよいという結論にいたりました。
少ない学習データだと精度上がるのですが、多くなってくるとガクッと精度が落ちます。
ストップワードは無しがお勧めです。
3. アプリでモデルを使う
分類器を使うためのチャットボットアプリを開発する必要がありますが、この投稿では細かくは触れません。Cognitive Toolkitでは、いろんな言語で学習させたデータモデルを使えるようになっています。チャットボットで使うことを考えるとWebAPI化した方が使いやすいので、C#からデータモデル呼ぶのが一番容易かなと思います。僕が作った実装もC#でWebAPIです。
さいきんWinMLやONNXなどが出てきてWindowsアプリや、iOSアプリ,Androidアプリでもデータモデルが使えるようになってきました。モデルのファイルサイズはせいぜい数MByteが多いと思うので、Windowsアプリや、iOSアプリ,Androidアプリにいれてしまうっていうのも便利かもしれないです。
運用コストについて
データモデルに関する運用作業には次のような作業があります。
- 業務が増加に伴って「質問と回答のペア」を増やす
2. ペアを増やすたびに15パターンくらいの言い回しを作る - 正答率の低い「質問と回答のペア」をチューニングする
2. ログを分析して回答の確立が60~80%くらいのゾーンを人力でチェックし、学習データを追加する。60~80%を選ぶ理由はデータモデルが自信があまりないが過半数が正答しているゾーンであるから。0~60%は、誤字や間違いが多すぎてチェックの時間がかかりすぎるのでコスパが悪い。
3. 導入初期は件数が少なければログをすべてチェックした方がよい - 辞書を更新する
2. ログを分析して標準化すべきワードをみつけ、辞書に追加する
3. 外部サイトが取得した辞書を更新する。
導入時に正答精度を高くしておけば、時間を経てもそれほど下がることはないので、大きな作業量が必要な運用作業はないと考えています。ただし、前提となるのは人が判断しないといけないところ以外は、自動化していることです。「運用コストが大きい」といっているチームは、自動化が進んでいないことが多いように感じます。データモデルをチューニングするのはデータサイエンティストっぽい人が多く、アプリ開発者が入っていない場合があります。僕のようなアプリ開発者だと進めていく上で自動化できる作業は自動化しないと気か済まないのですが、データサイエンティストっぽい人は自動化が苦手な場合が多いので注意です。
同じことができる製品
「Deep Learningコードを書くのではなくて、もっと簡単に同じことができる製品ないの?」ということをよく聞かれます。今回紹介したようなDeep Learningツールで実装する方法は僕も複雑すぎるなと思っていて、なんとかなんないのかと何度も調べてきました。弊社でもそうですがいろんな会社が特定業務を一緒に乗せたソリューションとして作っているものはいくつかありそうですが、QAチャットボット開発を容易にするプラットフォームとしての製品は現時点では無いと思います。
よく周りから言われるのは、Microsoft Cognitive ServicesのLUISですが、これは大量のクラスに分類するために作られておらず、最大500クラスまでです。(こないだまで20だったのですが、かなり増えました)なので少ない数のQAなら良いかもですが、将来的にQAが増えていったときに対応できない製品はNGじゃないかなと思います。
別の製品でいい線いってるのは、Microsoft Cognitive ServicesのQA Makerかなと思ってます。ただQnA Makerは「大事な機能がまだ足りない」と「Previewなので制限が厳しすぎてまだ使えない」という問題があります。「大事な機能」っていうのは、前章で述べたチューニングポイント2つ「学習データの整備」と「Training処理のチューニング」のうち、前者のチューニングを行う機能です。自前で前者だけ作れば割と使えそうなので、こないだ作ってみたのですがQA MakerがPreview版で制約に「1分間に10回しか問い合わせれない」とか「学習データが少ししか入れれない」とかがあり、それが致命的な制約なので動かせず断念しました。製品化して制約が外れれば、使えそうな気がします。早く「学習データの整備」関連機能を実装してほしいですね。そうなればQAチャットボットの普及は飛躍的に加速すると思います。
最後に
2017年の後半の数か月、この自然言語分類器を実装するために関連する本をたくさん読み、たくさん試行錯誤しました。夢で何度もDeep Learningのイメージがでてくるくらい没頭して過ごして、身体的にはぼろぼろになって辛かったのですが、非常に面白い時間でした。これらの技術がAI(人工知能)系と呼ばれる所以が、Deep Learningをやっていると実感できます。分類器が出す答えが、人間のソレとすごく似ていて、その類似性に驚き、感動する日々でした。今回扱ったのは、Deep Learningの中でも自然言語分類なので、学習データとその予測結果の因果関係が非常にわかりやすいです。データモデルが出した答えの理由が、学習データを見ればなんとなく理解できます。データモデルをチューニングする作業は子供にモノを教えるのと似ていて、間違ったことを教えると間違った答えをします。最近、ウチの7歳の子が、「砂糖を食べすぎると骨が解ける」という昔流行った迷信をどこかで聞いてきて、妻も聞いたことがあるらしく同調していたので厳しい口調で正しました。間違った知識は間違った答えを作ってしまうので、僕は許容できないです。間違ったことをそのままにすることにストレスを感じる人は、多いのではないでしょうか?そういう人は自然言語分類のチューニングに向いていると思います。文章の論理性が乱れているのが、気になって仕方ないので直しまくっているうちにデータモデルは正しい知識を学び、賢くなってくれます。そして、自分の意図が反映されていくので育てたデータモデルに少し愛着を感じるようになります。アプリケーションを開発した時も同じように愛着を持つのですが、アプリケーションの場合は、中身を詳細まで理解してしまっているので「作った」という感覚なのですが、データモデルの場合は中身がブラックボックスなモノに方向性を伝えていって成果がでるようにするので「育てた」という言葉がしっくりくる気がします。AI系の技術ってのは面白いですね。久々に没頭できて感動する面白いテクノロジーでした。