はじめに
最近、画像分類系のアプリを立て続けに5種類くらい開発しました。
そういう状況もあって、画像系のAI技術のおもしろさにハマり、いろいろと研究しています。
中でも特に興味を持っているのが去年くらいから爆発的に流行っているGAN。ニュースでもたびたび取り上げられ、AIテクノロジーの進歩の象徴のように扱われているような感があります。
例えば、以下のようなニュース
- AIが描いた肖像画、約4900万円で落札
- 「どっちの顔が偽物?」GANで生成したフェイク画像を見分ける訓練サイトをワシントン大学教授が公開
- 架空のアイドルを自動生成しまくる「アイドル生成AI」が誕生、どこかで見たことがあるようなないような顔が生成されまくり
- 「写真が証拠になる時代は終わった。」
これはGANのすごさが手軽に体験できるスマフォアプリ。一部無料で使えます。一度使ってみると、その未来感におどろきます。
FaceApp
あと、なんといっても社会的な大問題を引き起こしたDeepFake(アプリ名はFakeApp。すでに公式サイトは消滅している模様)
このニュースのリンク張りたくないので、ググってみてください。
非倫理的な利用の仕方をしたGANで、現在の「AI倫理ブーム」を加速させる要因となった事件です。
「画像判別」の方は普通のエンジニアが利用できるような製品がMicrosoftやGoogleからリリースされたりして普及期に入ってきている感がありますが、それとは違って「画像生成」は、まだ普及段階に入っているようには感じられません。このGAN技術をブログなどに投稿している方たちも研究者っぽい方が多く、投稿内容も「どう使うか」ということより、「どう作るか」がほとんどな気がします。
僕は「どう使うか」を考えるのが好きだし、仕事も「広く業務に役に立つ使い方を考える」のがメインタスクなので、とりあえず「どう作るか」はさっと読み流す程度で、ざっくり使ってみて「どう使えるか」を考えてみました。
やっぱ、アレコレ言う前に「まず使ってみることが大事!」。
ということで環境作って、試してみました。
この記事で書くこと
- GANってどんな種類があるのか?
- どんなことができるのか?
- 学習データはどんな形式で用意したらいいのか?※これが分かればカスタマイズがどこまでできるかザックリわかる。
- 今後の延長戦上でどういうことができそうか?
かなりライトにしか調査していないのと、GANって亜種だらけで混沌としていて複雑で、間違った内容を書いてしまう可能性が大です。間違ってても許してください。そして、指摘して頂けると有難いです。
画像系のテクノロジーをざっくりまとめる(サマリー)
画像系のAI技術は大雑把に分けるとこんな感じ。GANは亜種が大量にあるので、僕が目についた有名どころのみ書いています。
- 画像系AI技術
- 分類
-
Classification
- 写真単位に分類する技術。写真の全体感で分類し、タグ付けしたりして使う。
-
Object Detection
- 写真の中の対象物を検出する技術。大量の写真の中から、「車」が写っている写真だけ抽出するとか。
-
Semantic Segmentation
- 写真に写っているものを範囲別に分ける。上の半分は空で、右側にはビル、下は道路、左には大型トラックとか範囲を判別する。自動運転関連でよくでてくる技術
-
Classification
- 生成
- 線画から主に景色を画像生成するGAN(分類のSemantic Segmentationの逆回しのような画像生成)
- 物体(主に顔)を生成し、その形状を弄る(顔年齢を変える等)ことができるGAN ※実在する人物の顔写真を弄ることもできる
-
Star GAN 2017/11~
- 大量の顔画像を学習し、架空の顔を生成する。また性別度合いや若さ度合いをパラメータで切替えられる。
-
transparent latent-space GAN 2018/09~
- StarGANの亜種。使ってみてもStar GANより優れている点があるのかどうかわからない。しかし、紹介記事が多く知名度が高い。たぶんUIが良かったとかそういう理由で有名になったのだと思われる。確かにjupyterで使えるなどデモ使いやすさはStartGanよりいいかも。
-
Style GAN 2019/02~ by NVIDIA
- 高解像度かつ本物と見分けがつかない高品質な顔写真が生成できる。さらに車や動物、ベッドなど物体も生成できる。2つの写真を合成し、特徴を移植することができる。
-
Star GAN 2017/11~
- 線画から顔を弄る(輪郭、メガネ)GAN (上記2パターンの特徴を足したようなGAN)
-
SC-FE GAN 2019/02
- 線画から顔を生成したり、顔をイラストで書き換えて、メガネを消したりアクセサリーをつけたりできる。
-
SC-FE GAN 2019/02
- 2つの物体の特徴入れ替えるGAN
- 服の生成に特化したファッション業界用のGAN
-
Fashion GAN 2016/11
- 服の着せ替えに特化したファッション業界用のGAN。
-
Fashion GAN 2016/11
- 分類
それぞれのGANの特徴
1. 線画から主に景色を画像生成するGAN(分類のSemantic Segmentationの逆回しのような画像生成)
印象&成熟度
pix2pixからpix2pixHD、Gau GANへと解像度および精度を順当に向上させていっています。画像分類の1つのSemantic Segmentationの逆回しのような画像生成です。ニュースでGau GAN見たときは「おおっ、すごい綺麗で実用レベルだ」と思ったのですが、よくみてみるとまだ荒く違和感アリアリな精度です。
・まずニュースでよくでてくるエディター画面
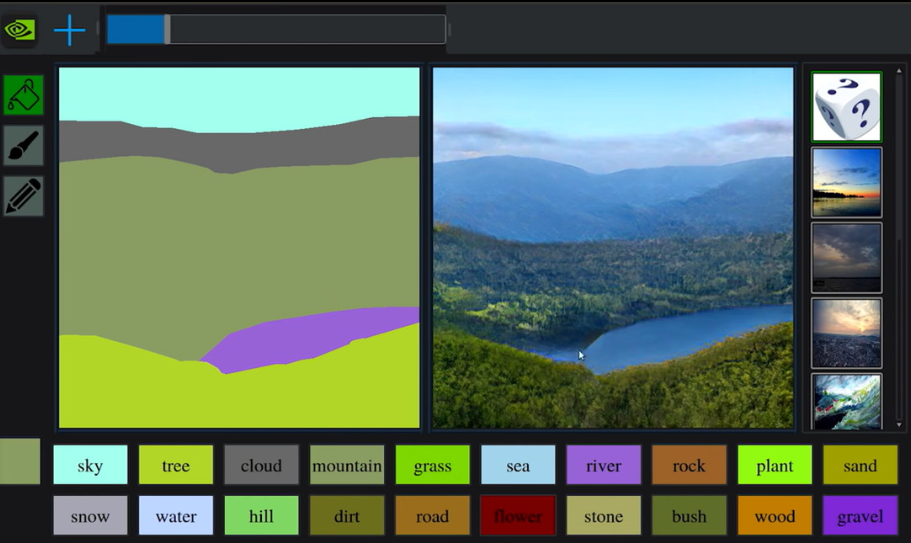
・変換画像

この景色だけ見ると本物と見分けがつかないように感じる。よさげですよね?
しかし、その理由は形式が非常に単純だから。少し複雑な風景にします。

なんかぐにゃぐにゃになりました。
ということで、現状は単純な風景では実用レベルですが、少しでも複雑になるとまだ生成精度低いです。
今後に期待ですね。
学習データの形式
以下のように、色がないセグメント分けした図と画像。セグメント分けした図は、画像分類の方の技術で生成できそう。この生成方法なら、大量に作れそう。

2. 物体(主に顔)を生成し、その形状を弄る(顔年齢を変える等)ことができるGAN ※実在する人物の顔写真を弄ることもできる
- Star GAN 2017/11~
- transparent latent-space GAN 2018/09~
- Style GAN 2019/02~ by NVIDIA
印象&成熟度
StarGANから顔などの物体画像の生成が始まって進化してきましたが、このStyle GANがめちゃくちゃすごい!現状、さまざまなGANの中で最も実用に向かって進んでいるGANだと思う。何がすごいって、自然な顔の生成能力と解像度です。例えば以下。


これでもまだMAXの解像度じゃないです。また、自然と人間として受け入れる精度の顔です。偽物の顔とは疑う余地はありません。歯並びがちょっと悪いところとか、かなり本物っぽい。さらに、パラメータで雰囲気を変えれます。以下は雰囲気の変遷をアニメーションGiFにしたもの。

また、以下では2人の顔を混ぜています。最左側4人と最上部3人の顔を混ぜた結果を表しています。それぞれ人の直感的にも、「それらしい」と感じるところがすごい。

ここまではStyle GANの説明ですが、Star GANやTL-GANだとカテゴリーで人の顔を弄れます。
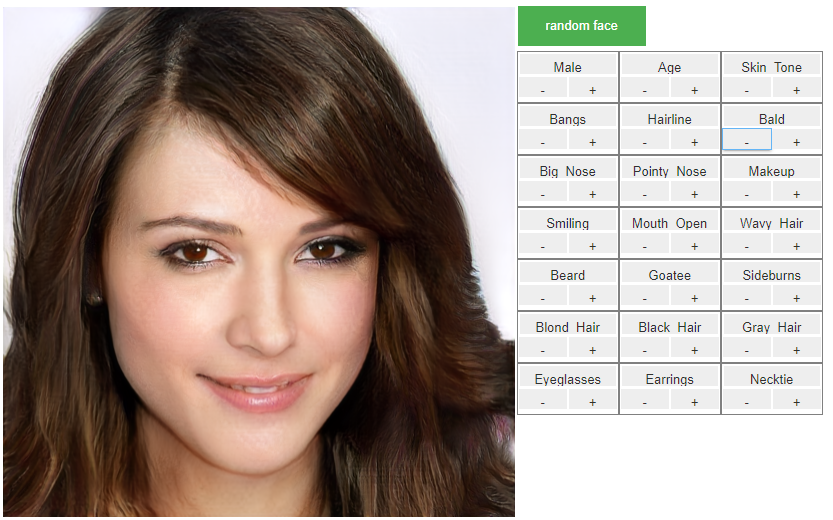
Maleの+ボタンを5回ずつ押して、男性っぽさを加えていきます。

次にAgeの+ボタンを5回ずつ押して、加齢していきます。

学習データの形式
この学習データは有名なLarge-scale CelebFaces Attributes (CelebA) Datasetです。
内容は以下です。
①20万枚くらいのセレブの高画質顔写真(アップ)
②分類情報。「若い⇔老いてる」「女らしい⇔男らしい」などの顔の分類情報。
②があるので、顔を「若い」特徴を付与したり、男から女に変位させたりできます。※Style GANだとできないかも(分類情報に対応するパラメータがない)。Star GANとTL-GANだとこの分類情報を使って、顔を変位させることができる。
まだ僕が確認できてないこと
任意の顔写真をベースに、若さなどのパラメータを変えて顔を弄る方法がわからない。これをしているいる例(FaceAppとか)があるので、このGANで実現できるはずだが、実装コードがまだうまく作れていない。サンプルコードがググっても見つからないので、自分で書いていく必要がありそう。書けたらシェアします。
3.線画から顔を弄る(輪郭、メガネ)GAN (上記2パターンの特徴を足したようなGAN)
- SC-FE GAN 2019/02
印象
人の顔を一度消して、スケッチで書き換えると弄れるGAN。公式サイトで公開されているビデオを見てるとスゲーって思ったのですが、自分でやってみると、大きな欠点が。なんと「僕にはうまくスケッチができない!」ことに気づく。
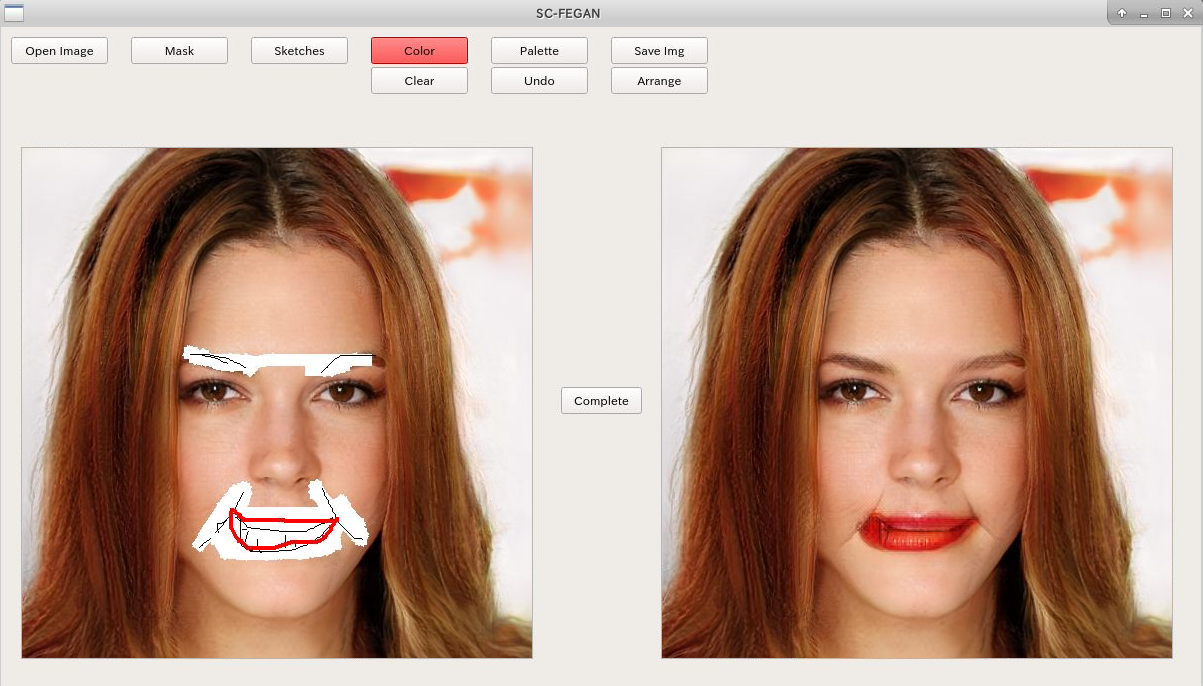
取返しがつかないくらいブサイクにしてしまい、悲しい気分になりました。ちなみに元の写真は生成した架空顔なので、傷つく人はいない、、、はず。
成熟度
うまくスケッチをすれば、うまく良い顔になり、実用的なのだろうと思われるが、絵心の問題でわからず。。。デフォルトで上手なスケッチを書き込んでくれるようにしてほしい。というかデフォルトで書き込まれるのであれば、スケッチじゃなくて、「笑う」とか「口の大きさを+」とかそういうボタンでよいような、StarGAN的なアプローチの方が使いやすいような。。。。
学習データの形式
このGANの学習は自分で試してないので、詳細は理解しきれてないのですが、公式サイトを見る限り、以下のように画像と、スケッチとカラーの3つが1セットとしているようです。おぉ、なんか作るの超絶大変そうな気がする。あえて、人間的な複雑な手法である「スケッチ」である必要があるのか?と少し思いました。

4.2つの物体の特徴入れ替えるGAN
Cycle GANとInsta GANの大まかな違い
Cycle GANの進化版がInsta GAN。Cycle GANは同じ形状のものしか置き換えできなかった(例えば、馬を縞馬にするなど)。しかし、Insta GANでは形状を変えて置き換えることができる。
印象
もっとも倫理問題になりやすいGAN。現在存在するものを別のものに置き換える技術なので、実在する人の顔や体を入れ替えたりすると嫌悪感を喚起し、たちまち倫理問題になる。使い方を考えて世の中に発表されていかないと、規制対象になる可能性がある。あの大問題となったDeepFakeもおそらくこの技術で実装されている。
成熟度
解像度が低ければそこそこ精度が高く見えるが、解像度を上げると違和感がまだ強くある。GauGANやStyleGANのような精度&解像度になってくれば、実用的になってきそう。
現状のInsta GANの画質。


こっちがCycle GAN。
Cycle GANってインターネット上には小さい写真しかないので、すげーって思うのですが、自分で生成してみて拡大してみたら、ちょっとガッカリする。

学習データの形式
以下のように写真+マスクを「変換元」「変換先」の双方用意する必要がある。枚数は数千枚くらいらしい。これで、変換元「羊」の特徴と、変換先「キリン」の特徴を学習し、変換できるようにする。
動画から静止画を切り出して作ると効率がよいはず。しかし、マスクが自動で生成できないとかなりキツイので、Object Detectionや背景削除するツールを併用してマスクする必要がある。例えば、DeepFakeの顔置き換えは、顔の輪郭を認識させてマスクを自動生成している。

DeepFakeの代表格アプリのFakeAppの仕組み
FakeAppはすでに公式サイトが閉鎖されているが、以前はフリーソフトとしてWindowsアプリでダウンロードできた。丁寧な作成手順がYouTube動画で作成されており、実装ための閾が低かったため広く普及した。
■大まかな手順(ただし、FakeAppでは以下の手順は、ほとんど自動化されている)
※繰り返しますが正確には不明。大筋は私の予想。
①「ベースになる動画」と「置き換えたい顔の写った動画」を用意する。
②それぞれの動画を静止画に切り出す。通常動画は秒間30枚もしくは秒間60枚の静止画なので、適した枚数に切り出す。
③静止画にした後、顔を中心に画像をトリムする。顔のドアップ写真にする。
④それぞれの動画に、対象者以外の顔が写っていたら削除する
→ここまでの手順で、「ベースになる動画の顔」と「置き換えたい顔」の静止画が大量に作成できる。
⑤「ベースになる顔」と「置き換えたい顔」の静止画から、顔の輪郭でマスクを作成
⑥GANに学習させる
⑦静止画のまま、GANで顔を置き換える。
⑧置き換えられた静止画を、動画に戻す。
5.服の生成に特化したファッション業界用のGAN
Fashion GAN 2016/11
印象&成熟度
まだ普及期に入っていない現在の段階でここまで活用方法が明確なGANは珍しい。ただ、あまり調べてきれてないが、開発があまり進んでいないように感じる。他のGANに比べても早期から開発が進められていたが、いったん関連技術のCycle GANやInsta GANの進化を待ってるんじゃないかと勝手に思っている。あまり目覚ましい成果は上げられてなさそうだが、ファッションに関する画像データセットの充実度合いはすばらしい。
DeepFashion Dataset
データセットを使うためには管理者への申請が必要なので、ちょっとめんどい。。
学習データの形式
調べてないですが、たぶんCycle GAN、Insta GANの類似だと想像される。
GAN技術の延長戦上にあるもの
NVIDIAが実現しようとしていること(かなり個人的な見解)
前章でざっとGANを列挙しましたが、特に注目してもらいたいのがNVIDIAの研究所が発表しているGAN。誰かが0を1にしたGAN技術を、NVIDIAが1を10に改善していっています。エンジニアじゃない人は「せこい」とか言いそうですが、技術の進歩としては賢い戦略でイノベーティブなGANの技術の大きく高め、GAN領域におけるNVIDIAの存在感を増やしていっています。
そして、NVIDIAは「景色を作るGANのGauGAN」と「顔などの物体をリアル作るGANのStyle GAN」を、本物と見分けがつかないレベルまで改善できてきています。NVIDIAはゲーム業界を中心とする会社なので、この延長線上にあるものは、やはりゲームのリアル化だと思います。現状のゲームは3DCGで作られていてかなりリアルに近くなっていますが、このGANが適用できるようになったら、まさに実写レベルまでゲームの映像はリアルに近くなるでしょう。リアルと見分けがつかない人を操作して、リアルと見分けがつかない景色を歩くようなゲームが登場することになると予想されます。
ちなみに現状の3DCG界で最高峰のリアル系CGは以下。(たぶん)
Saya(https://www.youtube.com/watch?v=GCICGJhfjM0)
最近だと
Liam(https://www.instagram.com/liam_nikuro/)
このCG技術もすごすぎますが、僅差でStyle GANで生成した顔の方がより本物っぽい気がします。しかし、大きな違いは「作るのに必要なスキル」と「生成するスピード」です。SayaはプロCGデザイナーの夫婦が2人で、かなり膨大な時間をかけて作っているはず。Style GANはスキルがなくても、(私のマシンで)30秒で画像が作れます。動画で作るためには秒間30回の画像生成が必要なので、リアルタイムレンダリングではまだ使えないかもしれませんが、プリレンダリングであれば十分作れると思います。現状の技術では、顔の向き変更した画像などは作れそうですが、繊細な表情などの顔の変化は作れないんじゃないかなって思います。しかし、時間の問題でしょうね。近いうちにGANで生成した映像がでてくるでしょう。肖像権とかないし、好みに合わせて顔のパターンを変えれるので革新的なんじゃないでしょうか?
非人道的な内容のゲームに使う人もでてくるだろうから、倫理的問題を一度クリアしなきゃいけない局面がありそうですが、普及すると思います。
この技術で作れそうなモノのアイディア
データの収集方法の難易度はとりあえず考えるのは抜きにして実現できそうなこと、作れそうなモノを列挙してみます。ただし、間違っている可能性もあります。
※とりあえず、倫理的な側面は無視してみる。本当は最近AI技術をやってて結構真剣に倫理を考えているのですが。
- パワポで使うようなアイコンイラストを生成できる。さらに表情のあるアニメにできる。(Style GANの延長線上)
- 「激しく戦っている風のかわいいイラスト」とかそういうオーダーでアイコンイラストを大量生成できる。
- アニメを実写っぽくにしてみたりできる。例えば「ダンボのアニメが、実写版になった」みたいなことを、トトロでやってみたりできる(GauGANかInsta GANの延長線上)
- 新海誠を超える実写に近い背景になる。まぁ、実写に近いと良いってわけでもないと思いますが、やってみると面白いかも。
- 逆に子供の運動会の動画を、アニメ化してみたり、実写映画のブルース・リーの戦闘などをアニメ化して北斗の拳との違いを楽しんでみるとか。(GauGANかCycle GANの延長線上)
- ドラマの出演者を全員知り合いにしてみる(Cycle GANの延長線上)
- DeepFake的な使い方
- 他人の顔を全員イケメン&美人にする。(Style GANの延長線上)
- ホロレンズのようなARデバイスを組み合わせて、リアルタイムに他人をイケメン&美人顔生成していく。完全オリジナルの顔にするのではなく、オリジナルの顔にイケメン&美人の特徴を増し増しにして顔生成する。ただリアルタイムで違和感なく画像の置き換えをするにはイノーベーション級の処理速度の改善がいりそう。
- 顔ではなく体に適用すると「マジカルたるルートくん」のみえっちんが作れる。FashionGANを作るより簡単なので画質は低いが今の技術で十分できるはず。(Insta GANそのもの。Insta GANの延長線上)
- 動物園に設置して、象をマンモスにしたり、狼をサーベルタイガーにしてみる(GauGANかInsta GANの延長線上)
- Google Mapとか撮影された写真の顔に肖像権などの対策にモザイクをつけているが、それをモザイクではなく自然なサングラス&マスクにする(Style GANの延長線上)
- 逆にモザイクは全般的に逆戻し(推定して生成)できるようになる(GauGANかCycle GANの延長線上)
- プリクラで撮影した顔を弄る機能が、もっと自然で、もっとがっつり編集できるようになる
- 整形外科で、整形後の顔がシミュレートできる
- 映画やドラマに写っている広告を書き換えられる。公の場で撮影した映像の背景などの編集が楽になる
- Microsoftの大型イベントで前の方に座っている記者達が全員Macだったという事件(?)が以前あった。そういうときは、MacをSurfaceに書き換えてしまるよね?映像上は。
これらのGANの動作環境の作り方
GPU前提だったり、NVIDIA CUDAが必須だったりとGithubからCloneしてきたPythonコードが実行できる環境を作るのは、やや難易度高いです。僕も最初、悪戦苦闘してどのサービスがいいのか探し回りました。最終的に落ち着いたのは、AzureのData Science Virtual MachinesでGPUつきのUbuntu VMを作るという手順です。
すでに開発環境が全部作られており、かつJupyterも実行されているので、超楽です。
価格はそこそこ高いですが、VMを細かく停止して節約するしかないです。
終わりに
AIって処理速度や継続性(休まず稼働)は人間の能力を超えるけど、精度(正解率など)に関して超えることはほとんど無いと悲観してました。しかし、それは「判別」系のAI能力であって、画像生成のような「生成」系は人間を遥か超えていくと感じました。例えば写真と見分けがつかないのような絵って人間には書けないですよね。レンブラントなどの天才画家であったとしても、ピクセル単位で書いているってことはないでしょう。画像だけではなく、3Dの画像や文章、音声、将棋の次の手など新しいモノを生み出す生成能力は、人間の能力はそれほど高くなく、AIが特に活躍できる領域であると思われます。
この領域は今年もホットな領域になりそうなので、引き続き注視し、次の驚きを楽しみにしていたいと思います。
--2019/4/26追記--
この「終わりに」を一昨日書いてから、本当に人間の画像生成能力は、AIに勝てないんだろうかと疑問に思いました。
僕は10代くらいまで明晰夢ができて、そのあとずっとできなくなってたのですが、最近たまに起こるようになりました(月1回くらいかな)。明晰夢とは要するに夢の中で夢にいることを自覚して行動できること。映像でいうと「インセプション」という映画ででてきたような感じ。あの映画はきっと明晰夢が上手にできる人が考えていると思います。映画で説明されている「無意識が夢に与えてくる影響」などがリアルなので。
以前まで夢の中で意識的に物体な景色を生成しようと考えたこともなく、ただ無意識が作り出したいろんなパプニングに巻き込まれるだけだったのですが、今はいろんなことを実験して遊んでいます。今ハマっていることは「景色や物体の生成」で、かなりカラフルできめ細かくリアルに想像したものが生成できます。
このことから考えると、人間はリアルの世界で画像を物理的なモノ「画像や動画」にアウトプットすることはできないが、頭の中では生成できてるんではないかと思います。ということでAIに負けてないはず!
起きている時に夢で生成した映像が見れないのか悔しいのですが、見れるようにならないか研究してます。クイズ番組の東大王で、目でみた映像を記憶し、あとで瞼の裏で見返せる人がいました。それができるんだったら生成した映像も瞼の裏で見れるんじゃないかと思うので、なんとか僕もできるようにならないか、鍛えられないか研究中です。脳波を解析する技術が進んだら、人間が明晰夢で作った映像をアウトプットできるようならないだろうか。明晰夢がコントロールできるようになって、VRゲームを作っていけるようになったら、めっちゃ面白そうだなぁ。
AI系技術をやっていると、いつも最後に感想として思うことですが、
「やっぱ人間の知能ってすごい!」