はじめに
Microsoftの音声認識技術を機会あって本気で検証したので、共有しようと思います。
音声認識技術はAIキーワードに含まれる技術の一つなのでAIが流行りだした2年前くらいから話題になり始めたのですが、特にHotになったのは去年2016年の年末にGoogleとMicrosftが立て続けにニューラルネットワークベース(ディープラーニングベース)のAPIを、誰でも使えるサービスとしてリリースしてからだと思います。
GoogleとMicrosoftが発表したニュースのキャッチコピーは認識精度が「人間並みに到達」だったので、かなり強いインパクトを世間に与えたのだろうと思います。私もこのニュースに驚き、強く惹かれました。
●当時のニュース記事
・Microsoft
http://jp.techcrunch.com/2016/10/19/20161018microsoft-hits-a-speech-recognition-milestone-with-a-system-just-as-good-as-human-ears/
・Google
http://ainow.ai/2017/06/08/114071/
また去年の年末の話題は英語での音声認識でしたが、今年の春にはMicrosoftが日本語でのニューラルネットワークベースの音声認識APIを、リリースされ話題になりました。このニュースは「リアルタイム翻訳」という言葉を強く押していましたが、リアルタイム翻訳は「音声認識 + 翻訳」なので音声認識という観点でも大きな技術革新のニュースでした。このニュースのときのキャッチコピーは「ついに日本語のリアルタイム翻訳ができるようになった」だったと思います。
●当時のニュース記事
・Microsoft
https://bita.jp/dml/ms_translator
ニュースは皆の興味を引くために作られているので、嘘ではない範囲で誇張されています。この誇張により皆が抱く期待と実際それらの機能を使ってみた時のギャップが大きく、使ってみた人は少し期待外れな感触を持たれたのではないでしょうか?
ただ、それは現状の音声認識でできることと、まだできないことを理解できていないから期待値が合わず起こっていることで、正しく理解していれば、それらの技術の凄さにも気づけると思います。できることと、まだできないことについてもこの中で説明しようと思います。
この情報を活用され、開発の現場でより良いアプリが生み出されていけばいいなと考えています。
検証の目的と前提事項
目的
・現在、利用可能な音声認識技術の特性や性能を見極め、特にビジネスシーンにおいて利用できるシナリオを探る
対象
・音声認識の最先端を探りたいので日本語ではなく、最も進んでいる英語での音声認識を対象とする
・一般の開発者が利用できるテクノロジーを使う。どっかの研究所でしかできないって話は無しで。
音声認識アプリの実装
検証に利用するテクノロジー
Microsoft Cognitive Services の
- Bing Speech API
音声認識のAPI。世の中一般的な言葉は対応できているが、少し専門用語になると誤認識する。なぜか「CEO」という比較的一般的に感じるワードも誤認識した。 - Custom Speech Service
音声認識APIに用語を追加しカスタマイズできるサービス。例えば、関係会社の会社名とか、会社名や商品名って認識してくれないとがっかり感がありますよね。 - Translator Speech API
翻訳サービスの一部の音声認識API(上記APIとは別ラインで開発されているようで物が違う)。
英語の音声認識サービスだとMicrosoftとGoogle、AWSあたりだと思いますが、専門用語を取り込むカスタマイズができるのは現状Microsoftだけだと思われます。ビジネス会話の中では、商品名・組織名・人名・会社名など専門用語が、評価テストで調べたところだと10%以上あるので、用語のカスタマイズでできない時点で、最高でも認識精度は90%超えれないということになります。よって現状はMicrosoftしか、選択肢はないかなと思います。
翻訳は今回対象にしてませんが、翻訳も同じく専門用語を取り込むカスタマイズができるのは現状Microsoftのサービスだけのようです。
コードサンプルと実装方法
今回評価用にWindows版(WPF)とiOS版(Swift + Objective-C)のアプリを作成して評価しました。
結果的に、クラウド側にあるエンジンが同じであるだけあってどちらで作っても同じ精度がでました。
使い勝手としては、やはりスマフォが持ち運びやすく使えるシーンが多いと感じました。
実装方法については別途書いたので、こちらを参照ください。
http://qiita.com/tomohiku/items/ea392330c5ee7021de1f
●Microsoft公式のコードサンプル
○Windows版
https://github.com/Azure-Samples/Cognitive-Speech-STT-Windows
○iOS版
https://github.com/Azure-Samples/Cognitive-Speech-STT-iOS
音声認識のテスト結果
評価の指標
音声認識の世界でグローバル標準になっている単語誤り率 (word error rate:WER)という指標で精度評価。この指標は要するに、単語単位の間違いの数の割合。
細かくいうと認識誤り、単語が足りない、不正文字が追加されているなどのパターンごとに係数があってやや複雑なのですが、「間違っている単語の割合」だと考えてほぼ間違いありません。
WERが0.15だと、15%が間違いという意味で85%が正解しているということ。
だいたい正解率が85%を超えてくると、実用的ではないかと言われており、
実際に使ってみてもその閾値くらいから使えるように感じました。
テスト結果
まずは、
- 用語を学ばせないでテストした結果(ニュース記事や英語学習教材などを使っている)
1人でのスピーチだとWERが0.2以下なので、正解率が80%を超えてきている。しかし、複数人でのディスカッションでは正解率は80%を下回る。
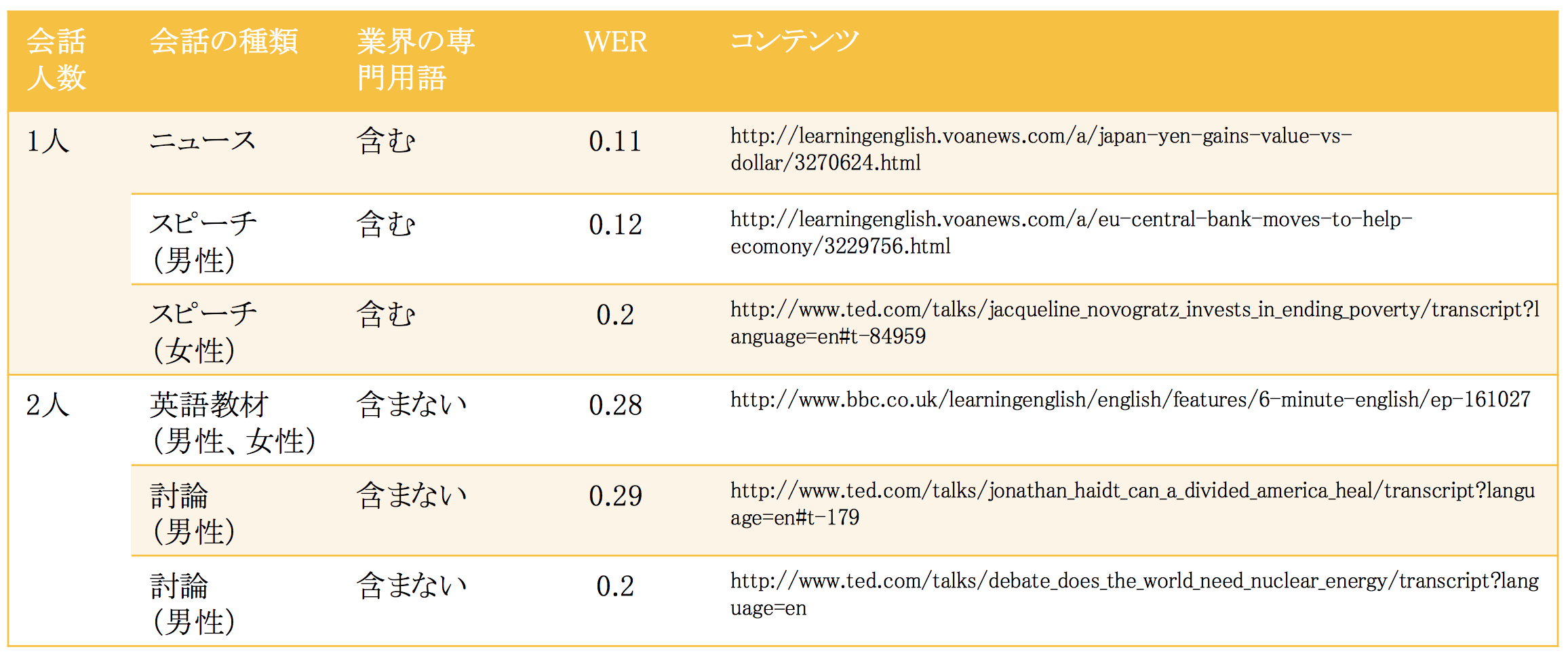
これは良い状況で録音された音声でやっているので、上記の結果は実際にマイクの前で話した時に比べて良い数字になっている。しかし、1人で話している場合は、体感では80%を大きく上回る正答率がでているように感じ、実用に耐えれるレベルだと感じた。逆にディスカッションでは60%の正解率くらいに感じ、ちょっとまだまだかなといった印象。
2. 用語を学ばせてテストした結果
組織名、人名、商品名などを学習させてテストした結果のWER。
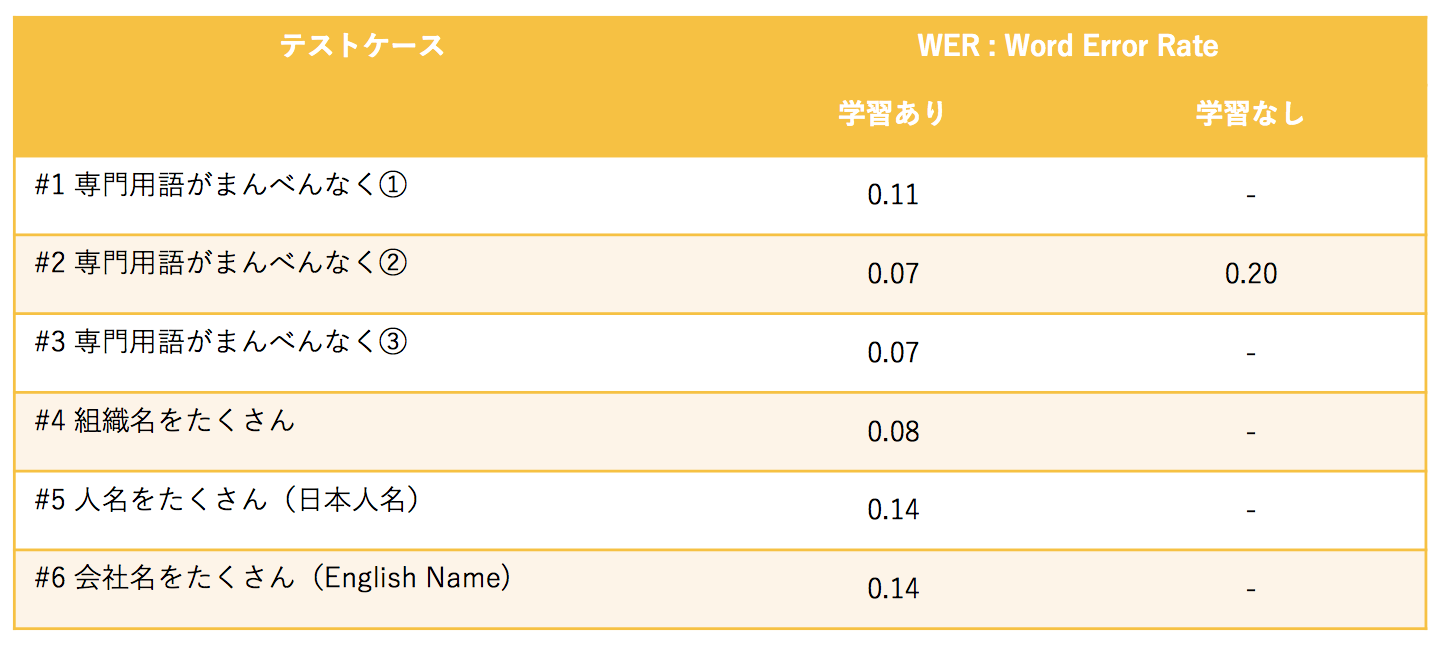
おおよそWERが0.1程度改善しており、正答率は90%を超えるものもでてきた。ここまで精度がでれば、文章の中で正しく発音されないようなワード、例えば「And」や「On」や複数型と単数形の語尾のSが違うなどが誤りの中心になってくるので実質誤りはほとんど無いレベルでだと感じる。
また、WERのテスト結果としては記載できるものがないが、ディスカッションではやはり顕著によくない結果であった。やはり体感60%くらいに感じた。
現状の音声認識技術の特性や性能のまとめ
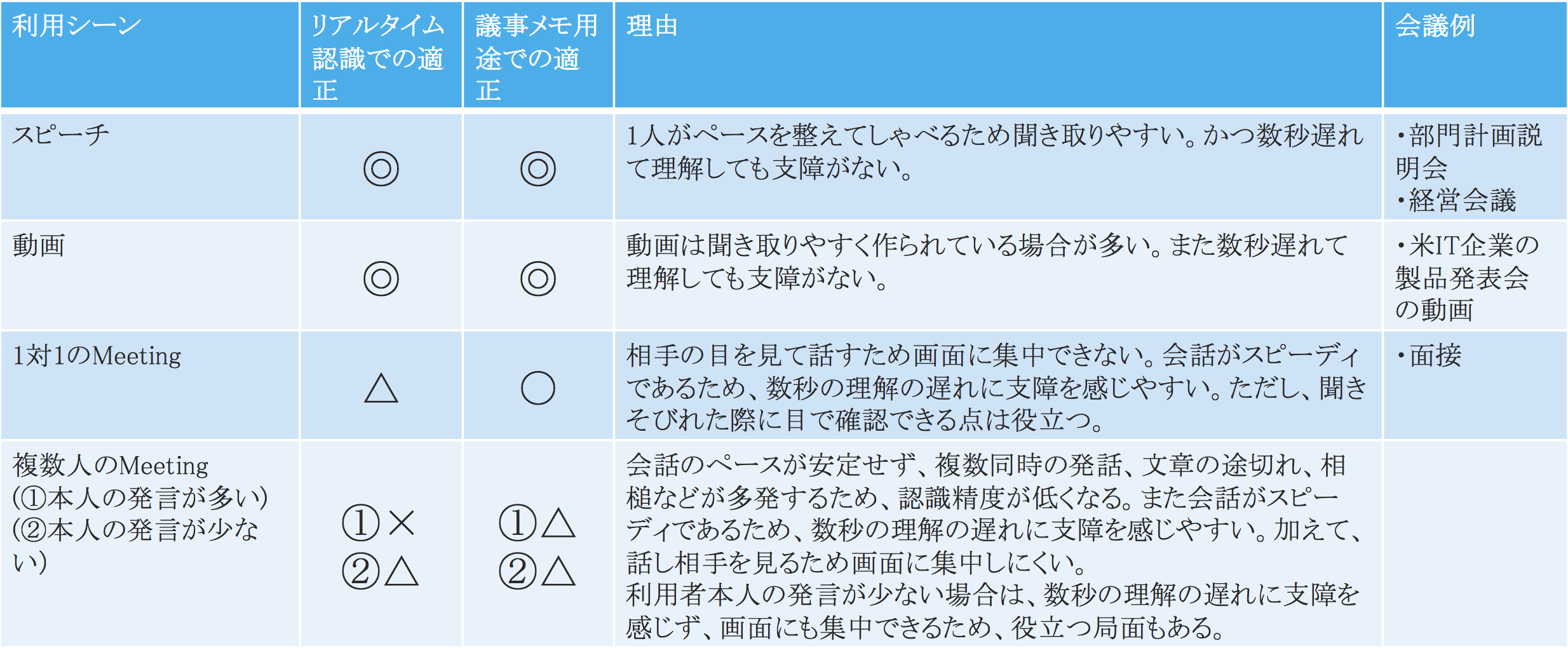
会話シナリオ別の精度評価
「スピーチ」や「動画の視聴」という利用シーンは、「1人が安定した口調で乱れの少ない文章を話す」場合が多いため、実用的だと考えられる。しかし、Meetingでの利用はまだ実用的なレベルではない(△)という評価をしている。
誤認識を発生させる要因
誤認識を発生させる要因を分析したところ、表にある項目が考えられた。

Microsoftの製品開発部門に問合せてみたところ、この表のようなことは、もちろん把握しているらしく洗練中とのことでした。特に訛りは対応が済み始めており、専門用語を取り込めない方の製品Bing Speech APIでは、すでに5カ国分の訛りに対応していた。
開発チームの頑張りに期待するとして、まだ対応していない上記は、せめて誤認識が発生した時に理由をアプリの画面に通知してあげることで、誤認識により利用者に与えてしまう「イラッと感」を軽減するようにした。
例えば「騒音が大きく、聞き取りが行いにくい状況になっています」とか「音量が小さく聞き取れません」などと行ったメッセージをアプリ画面に出すことで原因がわかり、ストレス度合いが下がると考えられる。
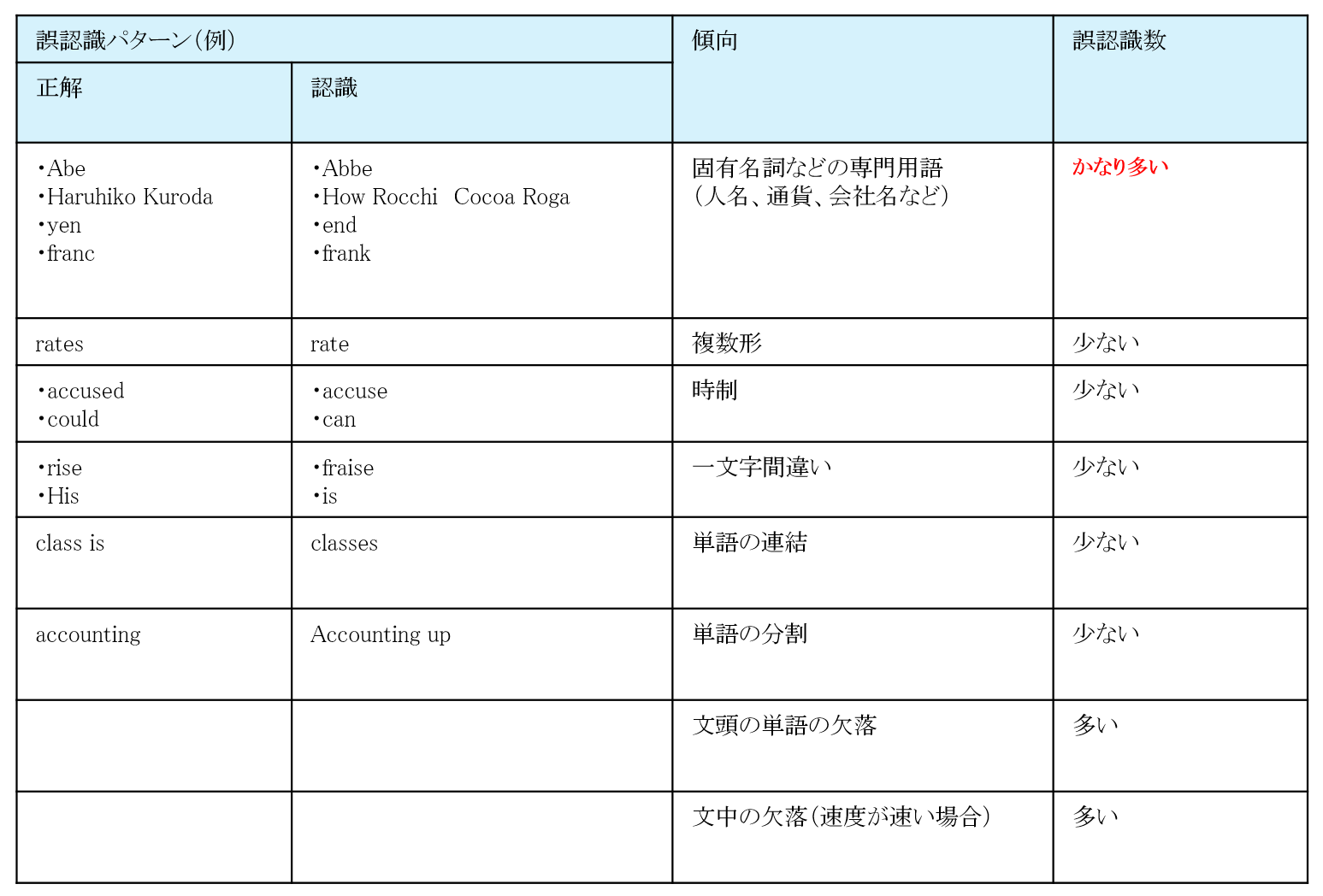
誤認識の多いパターン
専門用語の取り込みを行っていない場合の誤認識パターンをまとめた結果
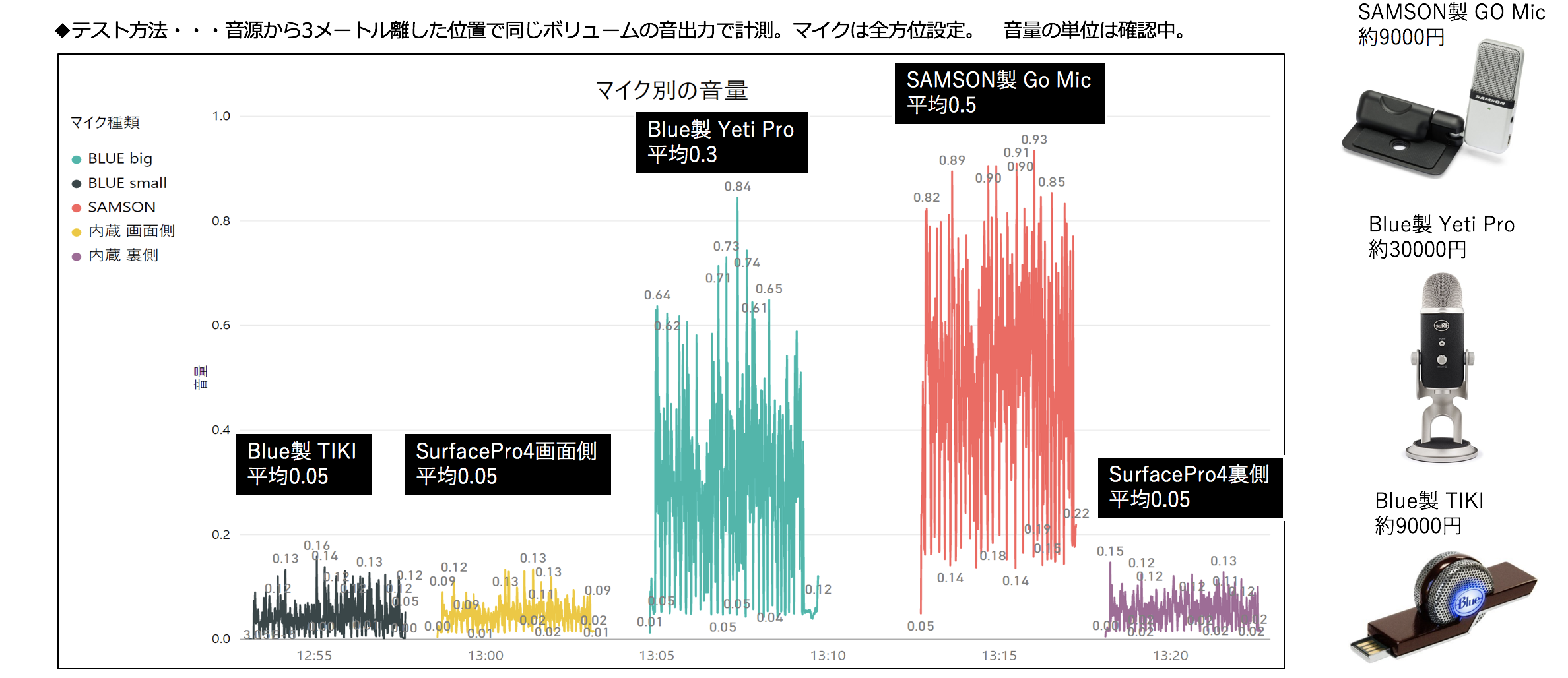
マイク
前で述べた音声認識の精度に影響与える要因のうち、おそらく音量が最も影響力が大きい。その音量はマイクを変えることにより改善できる。とはいえ、音声認識するのってモバイルな状況でやりたいので、持ち運びが嫌になる大きいマイクは当然NGだと考えている。なので、小型でストレスなく持ち運べるマイクだと、どの製品が良さそうかいくつか買って評価してみた。その結果が以下。すると、圧倒的な結果がでました「SAMSON製 Go Mic」すげぇ!確かにインターネットでも人気がすごく高かったように感じる。マイクってスペックの数字だけだとよくわからないけれど、比較してみると差が大きいもんなんですね。
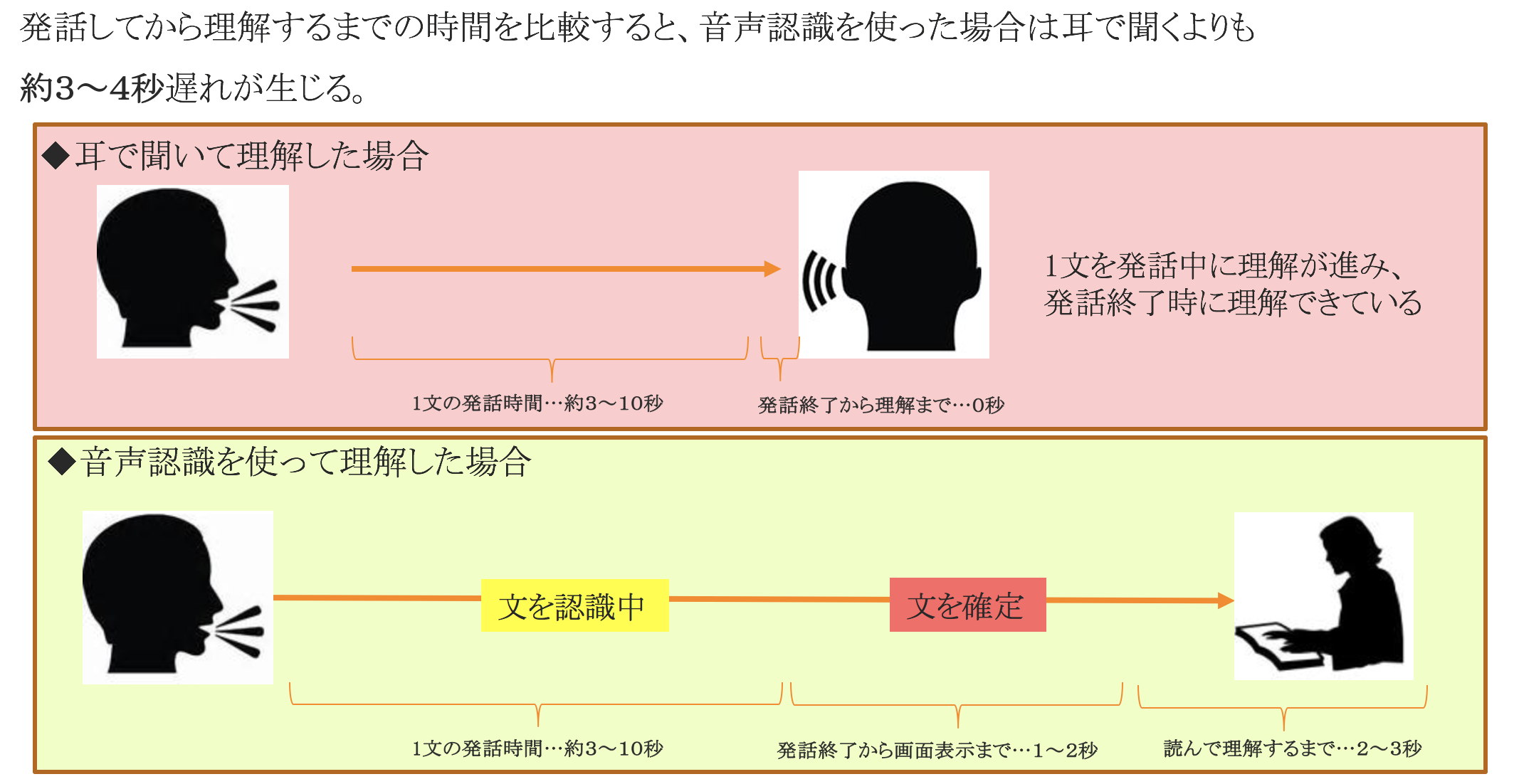
リアルタイム認識でのタイムラグ
映画の字幕は発話する前にテキストが表示されますが、これは音声認識なので当たり前ですが発話してからしか表示されません。そのタイムラグがリアルタイム認識ではやや障害になります。特にディスカッションのような会話では3〜4秒のタイムラグは、会話の円滑さを損なってしまうので、注意する必要があります。
Microsoftの音声認識技術APIで注意すべき点
MicrosoftのBing Speech APIとCustom Speech Serviceは、インタラクティブモードやカンバセーションモード、ディクテーションモードと3つのモードにわかれており、これらを利用シーンに合わせて適切に使ってあげないと精度が上がらないので注意です。AIデータモデルを作る上での学習データがそれぞれ違うようで、そのため精度も大きく違ってきます。今回行った評価はすべてカンバセーションモードで行いました。
3つのモードを簡単にいうとこんな感じです。
1.インタラクティブモード
相手が機械だとわかった上で話す声の認識。短い言葉のやりとり。Siri,Alexa,Cortanaと話す時ような感じ。
2.ディクテーションモード
相手が機械だとわかった上で話す声の認識。長文の入力。LINEの入力で1〜3行くらいのやや長めの文字を入力する感じ。
3.カンバセーションモード
機械相手ではなく、人どおしの会話として話す声の認識。

まとめ
まだ未熟なところもある音声認識技術ですが、近い未来にどんなシーンであってもほぼ完璧に聞き取ってくれるようになるだろうという感触を感じました。今、Amazon Echoなどの音声認識デバイスが次世代期待されるプラットフォームとして流行っているので、MicrosoftやGoogle、Amazon、Apple、FacebookなどIT系の巨人達は音声認識技術に対してまだしばらくはたくさんの投資を行っていくことでしょう。日本語が世界の音声認識技術から置いていかれている感がありますが、たぶん完全に見捨てられることはなく1〜2年遅れくらいではついていくだろうと私は考えています。
GoogleのサービスでスマフォのGPS情報から、移動した場所を四六時中記録し、過去ログとして参照できるというサービスがあります。デフォルト設定で記録されているので、知らない間に記録が残っている人もたくさんいることでしょう。そのサービスに、例えば「去年の8月7日」で検索すると、その日の何時にどこにいたか見ることができます。このサービスは場所ですが、音声認識の精度が完璧になり、骨伝導とかでマイクもうまく録れるようになったら、「昨年の8月7日の朝10時に、何をしゃべっていたか」も、見直せるようになるんでしょうね。それが個人にとって良いか悪いかは別として、GPS情報と同様に「できるようになると、記録するようになる」のだろうと予測しています。
記録に残したくないことはメールやチャットではなく、直接話すというのがビジネスの基本ですが、その基本も崩れていくでしょう。監視されて怖い未来だなって一瞬思うかもしれないですが、たぶんその怖さはまだ実現してないからであって、実現したら特に怖さを感じなくなくなるだろうと思います。GPSの記録だって数年前はみんな怖がってたけど、今だとあんまり議論になることなく、心の端っこで気にはかけてはいるけれど怖さは感じないでしょう。
ただ、せっかく音声認識でできることが増えるのであれば、生活を豊かにできることに活用しないといけないですね。私達エンジニアが知恵を出して、どうすれば役に立つか考えていかないといけないなって日々思っています。