はじめに
インターネットを探し回ったのですが、Microsoft Cognitive Serviceの1つであるCustom Speech Serviceの使い方をかみ砕いてブログなどで書いてくれているサイトが日本語では存在しませんでした。
結構よくできたサービスなのに、そんなに人気ないんだっけ?
最近本気でこのサービスを検証する機会があり、理解を深めることができたので、使い方を共有しようと思います。
Custom Speech Serviceの概要
MicrosoftのAIサービス的な位置づけのCognitive Serviceの中の一つであるCustom Speech Serviceは、音声の言葉をテキストに変えてくれるサービスです。別のCognitive Serviceである普通の音声認識サービス(Bing Speech API)は世の中一般的な用語しか取り込まれておらず、特定の商品名や社内用語、人の名前などは取り込まれてませんが、このCustom Speech Serviceでは自ら用語を追加することができます。なので例えば、「Mitsubishi UFJ Finnancial Group」という音声をBing Speech APIに聞かせると、「Mitsubishi left Jay Financial Group」になってしまいますが、Custom Speech Serviceで用語追加しておくと正しく認識できるようになります。
ざっとGoogleやWatsonなどを調べたところだと、大手の音声認識サービスで用語追加が提供されているのは、Microsoftだけだと思われます。
※Googleは用語を事前登録ではなく、問合せ時に都度送れば認識してくれるようでした。用語が大量になるとこの仕様って無理がありますよね。
現状の大きな欠点は、いまのところ日本語に対応していないってとこです。
とはいえ、英語でも役に立つシーンは多いと思うので便利です。
Custom Speech Serviceの良いとこ悪いとこ ※私の勝手な感想
良いとこ
1.新しい用語の学習データを作るのが簡単
テキストデータを追加すればよい。音声認識の学習だから、音声データがいるんじゃないか?と普通考えますが、テキストで渡せば学習してくれます。おそらくServiceの向こう側でテキストから音声合成して学習させてくれてるようです。また文章でテキストを渡すことが推奨されていますが、単語で渡しても学習してくれます。
なので、社内の商品マスタや組織マスタ、社員マスタなどから用語を抜いてきて、学習データが作れます。
2.会話に特化したモデルが容易されている
音声認識と一口にいっても、「機械に1言で命令する音声」「機械に聞いてねという気持ちで発話する音声」「機械を意識せず人と人が会話している音声」などいろんな利用シーンでの音声があり、それぞれに最適化したモデルを使うことで認識精度を高めることができます。音声認識技術は「機械に命令する」というところから始まったので、Microsoftも含めてモデルのデフォルトはこのシナリオに特化した学習がされています。しかし、このモデルでは機械を意識しない人が人に向けて行うスピーチや講義のテキスト化などの利用シーンでは、精度がでません。なので、Microsoftでは会話に特化したモデルが提供されてます。評価したところ、このモデルの違いにより精度が約15%くらいはかわりました。
3.対象の場所での雑音に合わせたノイズキャンセリングができる
音声認識の天敵はノイズによる音声劣化ですが、利用する場所や電話のノイズを学習させることで、キャンセリングができる機能です。この機能、実は僕はまだ検証してないのですが、かなり期待してます。ビジネスでの音声認識の利用シーンを考えると大抵が公共の場所や電話なので、ノイズって必ず問題になると思うんです。
悪いとこ
1.日本語に対応していない
現状、英語・中国・ドイツ語に対応
2.ちょっと高い
この手のサービスにしては、ちょっと高い気がしてしまう値段。
同時に1人で使う分(評価用)には無料。
しかし、同時に4人のプランだと月4万円から、同時に8人だと8万円からでした。
※この料金設定、最近変わったかも。複雑すぎて見積もれない料金設定になってました。
しかし実際に請求される料金をみると1環境で約5万くらいですね。
利用までの手順
1.Custom Speech Serviceに学習モデルを作成し、使えるようにする
1.Azure ポータルからCustom Speech Serviceのサブスクリプションを追加(Free)
2.Custom Speech Service ポータルでAzureで追加したサブスクリプションを設定
3.Custom Speech Serviceに学習データをアップロード(Languege DataSetの作成)
4.Language Modelを作成
5.エンドポイントを作成する
2.アプリを作成する(今回はC#でWindowsのWPF版)
1.サンプルアプリをGithubからダウンロード
2.サンプルアプリのビルド確認
3.サンプルアプリにCustom Speech Serviceのサブスクリプションとエンドポイントを設定する
手順詳細
1.Custom Speech Serviceに学習モデルを作成し、使えるようにする
1.Azure ポータルからCustom Speech Serviceのサブスクリプションを追加(Free)
Azureポータルから、以下のサービス追加する。PlanはFreeのサブスクリプションで良い。
・Azureポータル
https://portal.azure.com/

2.Custom Speech Service ポータルでAzureで追加したサブスクリプションを設定
1.ポータルにログイン
・Custom Speech Service ポータル
https://cris.ai/
2.ログイン名の横の▼ボタンから、Azureポータルで作った「Subscription」を設定

3.Custom Speech Serviceに学習データをアップロード(Languege DataSetの作成)
1.Adaptation Dataページを開く

2.Language DatasetをImportする。
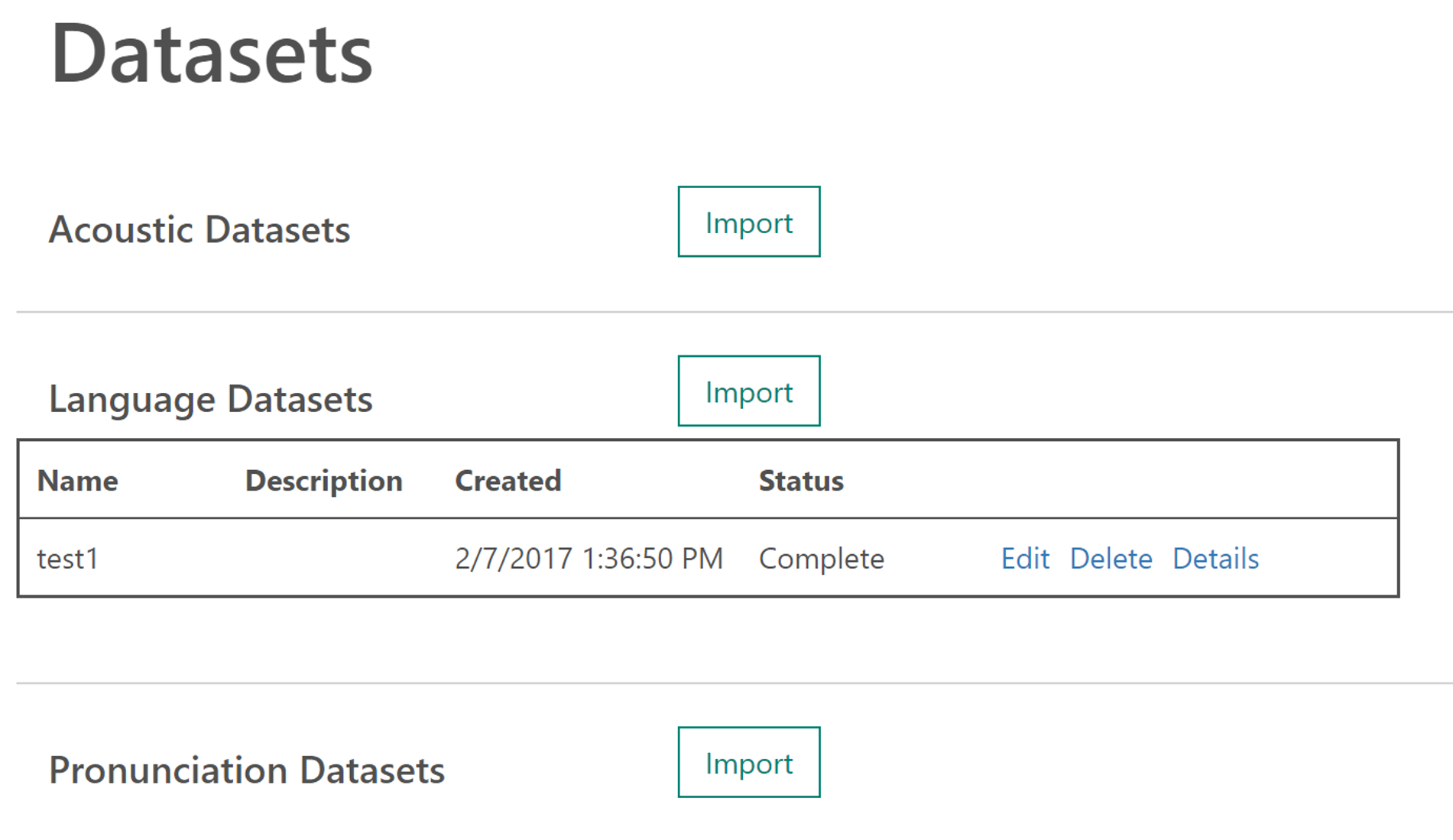
※Importするデータ
細かい作法はあるが、用語含むテキストデータを書くだけでもほとんども用語が取り込める。
テキストの例:AppleのWWDCでの喋りをテキスト化したもの
W W D C 2017 Registration and Attendance Policy
Registration and Tickets
Each ticket to attend W W D C costs 1599 United States dollars ("USD") and includes access to five days of sessions, hands on labs, and special events. Tickets are non refundable.
Due to limited availability, tickets are allocated through a random selection process. In order to be included in the random selection process to buy a ticket to attend WWDC, you must
Be a member of the Apple Developer Program or the Apple Developer Enterprise
・取り込むテキストの作り方の詳細は以下
https://docs.microsoft.com/en-us/azure/cognitive-services/custom-speech-service/customspeech-how-to-topics/cognitive-services-custom-speech-create-language-model
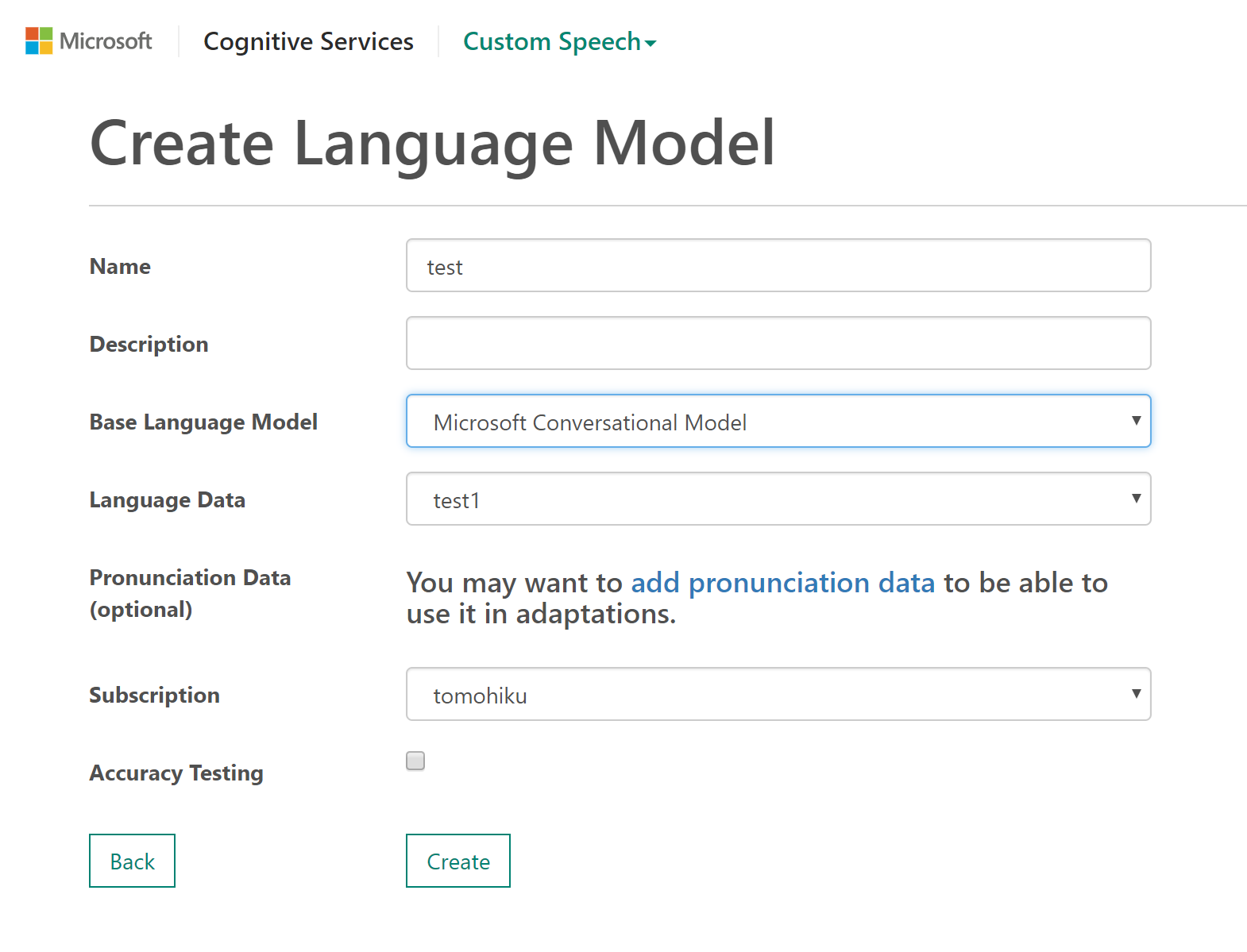
4.Language Modelを作成
3で取り込んだテキストデータを使ってModelを作る。
この手順で注意しないといけないのが、Base language model。会話系の認識だとConversation Model、単文のコマンドであれば、Search & Dictation Model、間違えると精度が大きく変わるので注意。
5.エンドポイントを作成する
この手順はあんまり悩むところないと思う。
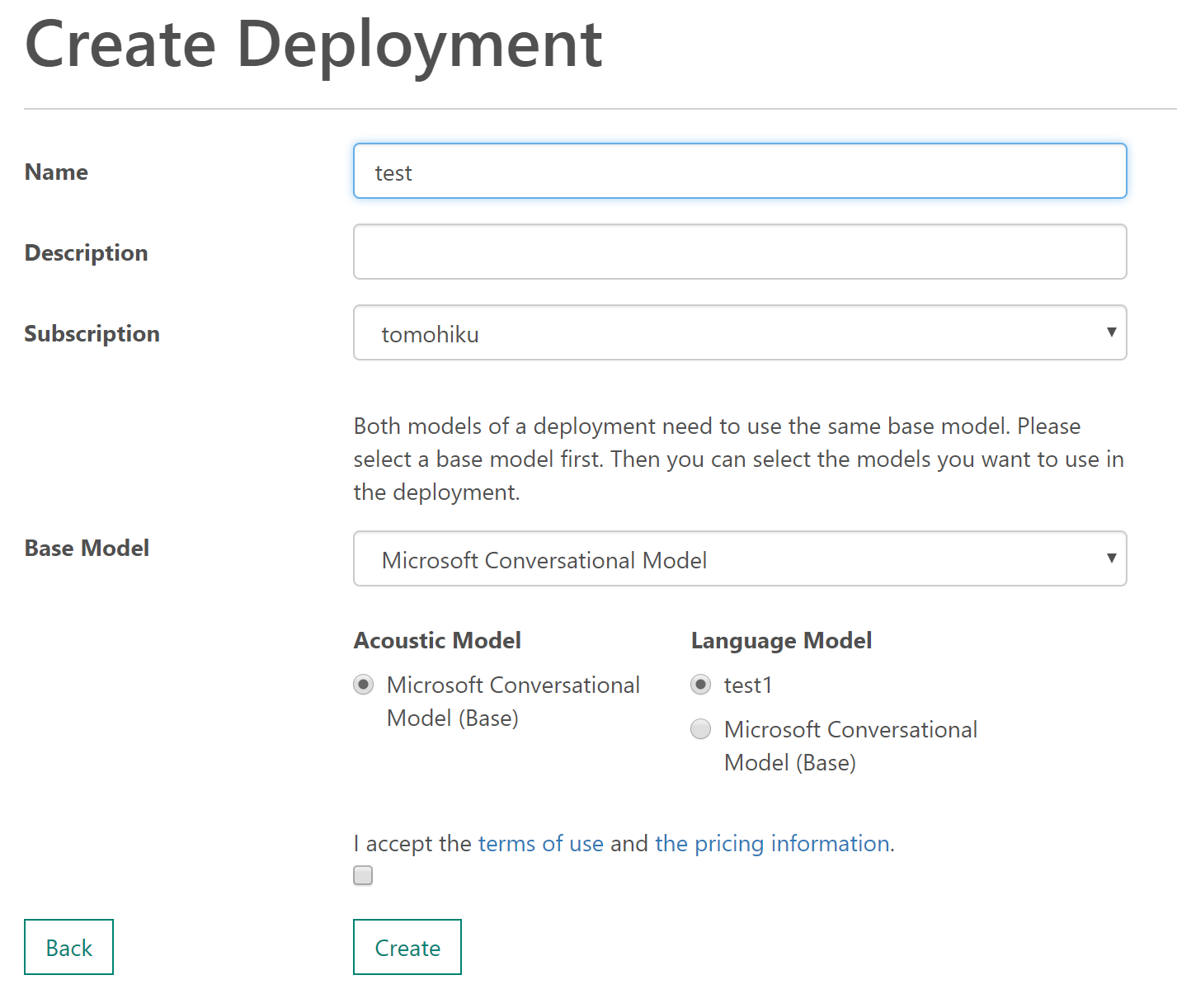
3種類のエンドポイントができ、あとでアプリで使う。
Websocket版で作るのが、一番動作が快適だった。ShortPhaseは15秒以内版、LongPhaseは2分以内版。現状、2分より長く接続しぱなしにできるエディションがない。

※参考
上記と同じような手順説明のある公式サイト
https://docs.microsoft.com/en-us/azure/cognitive-services/custom-speech-service/customspeech-how-to-topics/cognitive-services-custom-speech-create-acoustic-model
2.アプリを作成する(今回はC#でWindowsのWPF版)
1.サンプルアプリをGithubからダウンロード
・サンプルアプリ(WPF版)
https://github.com/Azure-Samples/Cognitive-Speech-STT-Windows
・サンプルアプリ(iOS版)
https://github.com/Azure-Samples/Cognitive-Speech-STT-iOS
※IOS版でもアプリを作りましたが、問題なく動作しました。ただWindows版とは違い、マイクを複数のスレッドで使うことができないようです。
2.サンプルアプリのビルド確認
Visual StudioでSolusionファイルを開き、そのままビルドすれば動作するはずです。
※IOS版だとXcodeですが同様です。
3.サンプルアプリにCustom Speech Serviceのサブスクリプションとエンドポイントを設定する
ここが、すこし情報がないとハマるポイント。Custom Speech Serviceのためのコードは、サンプルコードから非常にわかりにくいです。このわかりにくさだけで、実装をあきらめる人がたくさん出ていそうな気がします。
※IOS版でもほぼ同じコードの箇所がありますので、同様に修正してください
①App.configのAuthenticationUriに、固定のURLを設定する。
これは、Custom Speech Serviceの認証のためのURLです。
※luisAppID、luisSubscriptionIDはLUISという意図分類サービスを使う時は必要ですが音声認識だけ使うときは不要です。
<appSettings>
<add key="luisAppID" value="yourLuisAppID" />
<add key="luisSubscriptionID" value="yourLuisSubsrciptionID" />
<add key="ShortWaveFile" value="whatstheweatherlike.wav" />
<add key="LongWaveFile" value="batman.wav" />
<add key="AuthenticationUri" value="https://westus.api.cognitive.microsoft.com/sts/v1.0/issueToken" />
</appSettings>
414行目あたり
◆変更前
this.micClient = SpeechRecognitionServiceFactory.CreateMicrophoneClient(
this.Mode,
this.DefaultLocale,
this.SubscriptionKey);
this.micClient.AuthenticationUri = this.AuthenticationUri;
◆変更後
this.micClient = SpeechRecognitionServiceFactory.CreateMicrophoneClient(
this.Mode,
this.DefaultLocale,
//Custom Speech ServiceのEndpointページに書かれたSubscription Key
this.SubscriptionKey,
//Custom Speech ServiceのサブのKey Azureポータルをみるとわかる。ただ上のSubscription Keyと同じでも動く
this.SubscriptionKey,
//Custom Speech ServiceのEndpointページに書かれたWebSocket for LongDictation mode
"https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.api.cris.ai/ws/cris/speech/recognize/continuous"
);
this.micClient.AuthenticationUri = this.AuthenticationUri;
上記のClientを作っている箇所は4か所あるので、必要に応じて書き換えます。
◆Clientを作っている箇所
CreateMicrophoneRecoClient() //マイクからの音声を音声認識する
CreateMicrophoneRecoClientWithIntent() //マイクからの音声を音声認識し、LUIS(意図解析サービス)に渡す
CreateDataRecoClient() //WAVファイルからの音声を音声認識する
CreateDataRecoClientWithIntent() //WAVファイルからの音声を音声認識し、LUIS(意図解析サービス)に渡す
※参考
コードの修正方法を説明してくれている公式サイト
https://docs.microsoft.com/ja-jp/azure/cognitive-services/custom-speech-service/customspeech-how-to-topics/cognitive-services-custom-speech-use-endpoint
おわりに
世の中ではChat Botが流行っており、私も何度か開発を行いましたが、実は私自身Chat Botの将来性には疑問を感じています。なぜかというと、LINEなどでいろんなChat Botを体験しましたが私自身が「楽しい」とまったく感じないからです。それは私がもうおっさん化していて若い人の気持ちがわからないからじゃないかと思い、20代の人にも意見を聞いて回ったのですが、やっぱ若い人もLINEのChat Botは、ほぼ使わない、むしろウザイという意見がほとんどでした。Chat Botで私が成功しているのは「ヤマト運輸」と「りんな」くらいじゃないかと。。。
・ヤマト運輸
http://www.kuronekoyamato.co.jp/ytc/campaign/renkei/LINE/
※宅配の前日に配達時間の確認をしてくれ、Line内で簡単に配達時間の変更ができるという秀逸なBot
・りんな
http://www.rinna.jp/
Chat BotというプラットフォームってIT業界は流行らせたいかもだけど、実質使い勝手がいまいちすぎないかと思ってます。
しかし、音声コマンドのプラットフォームには未来があると思ってます。Amazon EchoやGoogle Home、AppleのHomePod、MicrosoftのInvokeあたりが先導していくであろう領域です。なぜかっていうとChat Botは入力がめんどくさいけど、声でしゃべるのは簡単だよね。入力者へ課するストレスがすごく小さいと感じます。例えば「この部屋の電気を消して」「テレビつけて」「6チャンネルに変えて」とか言って、リモコン替わりになるだけでも便利な気がします。慣れるまで少し時間かかるかもですが、慣れれば音声は潜在能力が高いのでは?と感じてます。実際、アメリカではChat Bot以上に流行りまくってますしね。
そういう音声の世界になった時に、今回紹介した専門用語の取り込みができる音声認識は必須機能になってくると思います。特にビジネスの中で使うのであれば、自分の会社のサービスや商品名を音声認識してほしいというニーズは間違いなく生まれてくるでしょう。Amazon EchoとGoogle Homeがもうすぐ日本でリリースされるはずです。Amazon EchoだとAmazonの音声認識、Google EchoだとGoogleの音声認識を使う必要がありそうですが、たぶんビジネスではそれらのデバイスではなく、電話やPCなどの別のプラットフォームを使うシーンがほとんどだと思われるので、Microsoftの音声認識が優秀であれば選択肢として有望かなと考えています。