はじめに
前回、なんかうまく行かなかったチャットを通じてのDollyさんとの組み手(格闘か?)、間違いかもしれない点を探りながら対応を修正してみる。そもそも、instruct_pipeline.py で定義されている、InstructionTextGenerationPipeline によって生成されるパイプラインを、当初のchatボットのパイプラインにそのまま使ってしまって、チャットの文言渡しただけで引数の受け渡しがうまくいっているのか?という疑問の解決からスタートし、速度改善の可能性なども検討してみる。
Dollyさんとの付き合い方を調べる ~ Datablicksさんの instruct_pipeline.py で 〜
そりゃそうだ。お互いに全然見も知らぬプログラム同士を組み合わせていきなりどんで動くわけねぇ・・・。ジャイナント馬場さん連れてきて、ハイそれでは所ジョーイチさんと、チャンバラしてくださーいってどんな台本だよ、ってな現場ぐらい動くわけねぇ・・・。えーっと、まず所さん(= チャットプログラム)を置いといて、連れてきた馬場さん(= instruct_pipeline.py)のできることを確認しよう。
早速だが、 馬場さんにはテキストの渡し方のフォーマットがあるようだ。

で、このフォーマットを参照する箇所は、InstructionTextGenerationPipelineクラスの preprocess 関数。
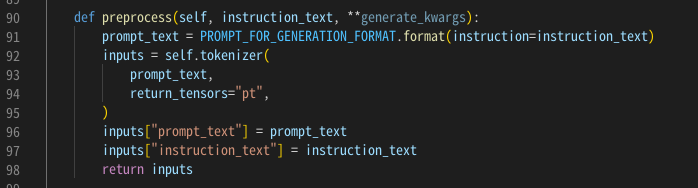
preprocess の引数でinstruction_textを引数にして、馬場さんFORMATに整形して改めてInputno引数(配列)の要素の一つにしてる。ってことは、キーワードを所さんで明示しないでよいってこと。所さんはインストラクション(指示)を文章で書けばよい、と。
それでいってみたところ

時間はかかったけど、こちらの意図した(インストラクションした)とおりにタスクをこなした感がある。
Pipeline
馬場さんは、そもそもどういう素性の人かというと、某団体(=HuggingFace の Transformer)の選手(=Pipeline)である。Transformerの Pipeline を継承した クラスが定義してあるってことよ。Pythonってクラス名の()に親クラス名を書いて継承するのね。そういう書き方から知らずにいじってたよ、わたし。


さて、それでは、 Pipeline の高速化にはどんな方法があるのか。
まずは、推論速度を高速化する手法の調査をしてみた。
うーん、かんたんで効果的っぽいのは、量子化かなぁ。かんたんと判断した理由は、modelの宣言のところでデータタイプの宣言を変えるだけでよさそうだったから。早速試してみた。
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.qint8, device_map="auto")
さっそく、この設定でDollyさんを再起動。
・・・あれ? エラー。
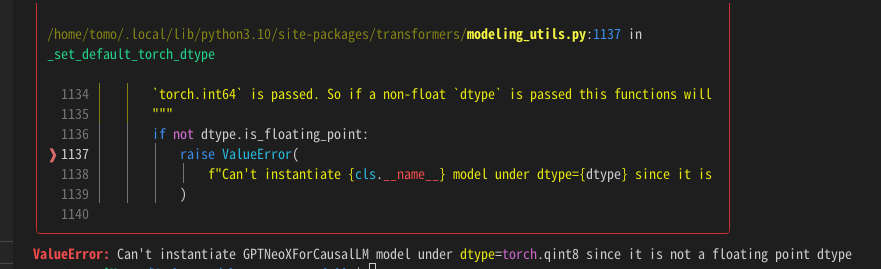
この方法は使えないのか・・・じゃぁ、とりあえず、bfloat16で。
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
さて、これで再起動。
さっきと同じタスクを所さんに入力。返事が返ってくるのがちょっと早くなった。少し時間短縮したきがする・・・。

おや?dtype変更まえと結果が異なるようだが・・・
課題の元のの文章には、実は続きがあって文章が途切れている。その途切れている部分について要約に盛り込んでいたのが、データタイプを変更するまえの応答。「何を言ったか」がわからないのに”なにか言ったぞ”として要約にあげているので、ちょっとセンスがない。データタイプ変更前は、デフォルトなのでなんだかわからないが torch_dtype=torch.bfloat32 だったのか。それに比べると、 torch_dtype=torch.bfloat16 にしたあとのほうが、今回のタスクとは相性がよかったのか、文章の要約としてはうまく抽出している気もする。
dtypeの指定前後とも「3点」に絞って文章を作るタスクをする、という意図(インストラクション)は伝わっているようだ。つまり、dtypeをbfloat16にしても、悪くなさげ、と解釈できる。
まとめ
Dollyさんとのインストラクションを使った付き合い方がわかった。
処理の高速化のためにTransformerでは量子化という手法があり、HuggingFaceのTransformerでは、modelの設定引数のtorch_dtypeをtorch.bfloat16にすることで、処理精度をあまり変えずに処理時間を短縮できそうであることがわかった。
今後は、要約以外のいろいろなタスクをさせてみたい、と思う。
おまけ。
NvidiaのGPUを使っているときにプロセスがメモリを開放してくれないときがあって・・・対処法も調べてみた。なんのことはない、nvidia絡みのプロセスを見つけて kill 斬る