最近 Qiita で parallel_tests による RSpec の並行実行を導入したので、どういう設定をしたかをまとめます。
なぜ parallel_tests を導入したか
そもそもの導入のモチベーションは「CI にかかる時間と料金を減らせる」ということです。
Qiita では CI 実行に GitHub Actions を利用していますが、デフォルトのランナー (実行マシン) が CPU 2 Core になっています。(Ref: GitHub ホステッド ランナーの概要 - GitHub Docs)

RSpec を並列実行することで、複数 CPU を有効活用して、マシン台数を増やさずにより高速にテストを完了させることができるようになり、その分料金も抑えられます。Qiita でも parallel_tests 導入後は、 RSpec を実行する CI の時間と費用がおおよそ 60 ~ 70% 程度まで減らすことができました。
設定でやや面倒なところはありますが、その分の価値はあったかなと思います。
設定で行った工夫
各種データベースの接続先を分ける, 名前空間を分けた
まずやるべきでほとんどこれに尽きるのですが、 MySQL, PostgreSQL, SQLite, Redis, Elasticsearch, ...etc の各種データベースを、テストプロセス間で分離することが必要です。
これの目的は、テスト間のデータの競合が起こらないようにすることです。ほとんど同じ設定のアプリケーションを複数並列で動かすので、データベースの同じ箇所を参照していると、もう片方に内容を書き換えられたりして flaky test の温床になります。
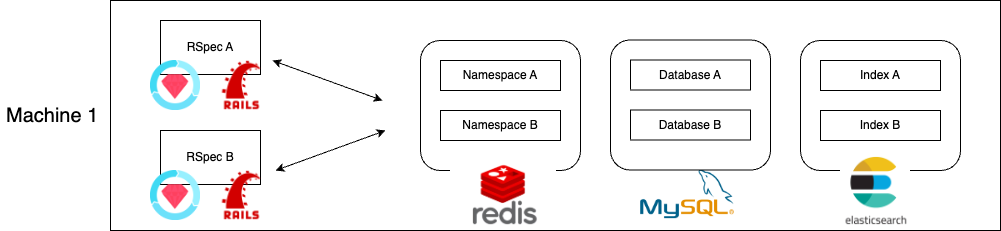
parallel_tests では ENV['TEST_ENV_NUMBER'] というテストプロセスごとに異なる値が (以下のように) 振られています。これを使って接続先や名前空間を分けました。
- 1つめ: (空) or
1 - 2つめ:
2 - 3つめ:
3 - ...
- nつめ:
n
MySQL, PostgreSQL などの RDBMS の場合は、非常に簡単で、以下のように database.yml で書いてあげるだけです。paralell_tests がセットアップする Rake Task (parallel:setup など) も用意してくれていたり、至れり尽くせりです。
test:
database: yourproject_test<%= ENV['TEST_ENV_NUMBER'] %>
Redis, Elasticsearch などは、それぞれで分け方や設定方法を考える必要があります。データベースやライブラリレベルでの分離機構を使う、複数個起動する、 prefix や suffix をつける、などで、互いに干渉しないようにしました。
分離が徹底できるように接続先の設定が DRY になるように都度リファクタリングしたり、とかも考慮したほうが良いでしょう。
# redis は複数の database を持つ (※上限あり)
redis_client = Redis.new(db: (ENV['TEST_ENV_NUMBER']&.to_i || 0))
# redis-namespace 使っているならそれを使うのもあり
redis_client = Redis::Namespace.new(ENV['TEST_ENV_NUMBER'] || '0', redis: redis_connection)
# elasticsearch の例
es_client = Elasticsearch::Client.new(...)
es_client.get(index: "test#{ENV['TEST_ENV_NUMBER']}-my_index", id: id)
また https://github.com/grosser/parallel_tests/wiki に様々なライブラリやツール向けのプラクティスがあるので見ておくと良いです。
※ テスト後のクリーンアップ処理にも注意
RDBMS だったら DatabaseCleaner や rollback 等だったりあるいは自前で、テストが終わる度に、テスト前の状態に戻したり、データを削除する、という処理を入れていることが多いと思います。
特に自前でやっている際に、適切な範囲を消去できているか注意が必要です。(他のテストプロセスの分まで消去してないか、 ENV['TEST_ENV_NUMBER'] のあるなしを双方ケアできているかなどを確認しておいたほうが良いです。)
# NG (他のテストプロセスの分も消してしまう)
redis_client.del('*')
# OK
redis_client.del("test#{ENV['TEST_ENV_NUMBER']}-*")
実行時間で同じぐらいになるようにテストを分割するようにする
parallel_tests に限らず、複数マシンで分割しているときでもそうなのですが、テストの分割の仕方が悪いと高速化のメリットが薄れてしまいます。
例えば、以下の図は過去の Qiita の複数マシンでの CI 実行時間ログなのですが、早いものと遅いものでかなりのばらつきがあり、台数ほどの高速化の恩恵を受けられていません。
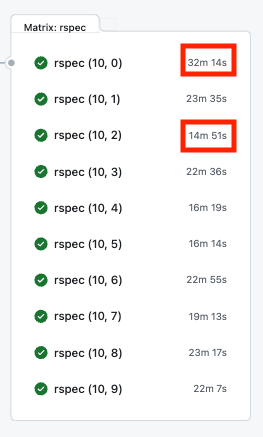
これを改善するために Qiita では実行時間ベースのテスト分割を導入していたのですが、これを parallel_tests でも扱えるように拡張を行いました。
詳細は 複数台で parallel_tests を動かす場合でも、実行時間ベースでテストを分割できるようにする #Ruby - Qiita にまとめたので、詳しくはそちらを見てください。
導入後のテスト失敗に備えた準備 & 周知を行った
並列実行なので、謎の失敗が発生する可能性はどうしてもあります。そうしたときに対処できるように、 parallel_tests 導入の際は、社内アナウンスと大まかな仕組みの説明を行いました。

ただこれらのテストのデバッグは結構大変なこともあるので、一部テストを切り戻す (parallel_tests ではなく通常の RSpec を使う) 準備も事前に行っていました。 (ただ、今回は運良く、実際に切り戻しが必要なケースは出てきませんでした)
準備した方法ですが、 parallel_tests ではそういう設定を提供していないので、 RSpec の tag を利用しました。
it '並列実行したくないやつ', :no_parallel do
end
parallel_tests を使いたくないケースで no_parallel タグを付けて、
- parallel_tests で
no_parallelタグがついてないテストを実行 - その後 rspec で
no_parallelタグがついてるもののみを実行
という2段構えを用意して、一部テストを切り戻す準備は行っていました。
ただ、正しい切り戻し範囲を把握するのは難しい (落ちたテストが悪いのではなく、別のテストが干渉していることがあるため) ので、事前に念入りに動作確認したり、導入範囲を限定したり、切り戻しの可能性を極力減らしておいたほうが良いです。
その他細かい工夫
ここからは、割と細かめな工夫です。
公式ドキュメントや Issue を見ておく
導入する際に、 Readme や wiki を見ておくのがおすすめです。色々なツールへの対応方法が幅広く書いてあります。
- https://github.com/grosser/parallel_tests/blob/master/Readme.md
- https://github.com/grosser/parallel_tests/wiki
設定で詰まったときも、過去の Issue も見ておくと良いです。広く使われているからか、過去のトラブルシュート事例が結構載っている印象です。
カバレッジデータ、各種ログ等の出力先を分けて、merge する
各種計測やロギングのために、RSpec のログやカバレッジも出力先が被らないようにし、 merge する必要がありました。
出力先を分けるために、TEST_ENV_NUMBER 環境変数を使う他、コマンドライン引数に \$TEST_ENV_NUMBER を渡すときに各テストプロセスで実行する際に異なる値を入れてくれます。
parallel_rspec \
--runtime-log runtime.log \
--format RspecJunitFormatter --out rspec-\$TEST_ENV_NUMBER.xml \
-- spec/hoge_spec.rb spec/fuga_spec.rb
(ちなみに、simplecov は parallel_tests からの実行を検知して、自動で出力を分離し、 merge を行ってくれます。賢い。)
Spring に対応するために、テスト前に接続をリセットする
開発環境用のプリローダーとして使われている Spring ですが、あらかじめ初期化した (initializer などの読み込みなど) プロセスを fork して利用するという性質上、 TEST_ENV_NUMBER が接続先に反映されていないことがあります。
database に関しては、 DocSpring/spring-commands-parallel-tests がケアしてくれるのでこれを導入するとよいですが、それ以外は自分で Spring 対応をする必要があります。
Spring には after_fork という、「プロセスの fork ~ 渡されたコマンドの実行」 の間にフックを仕掛けることができるので、これを Rails の initialzer として仕込んで対策します。
Qiita では、 Redis の設定がうまく反映されないことがあったので、以下のように、 Redis を再接続するようなコードを実行するようにしました。
# これを initializer として書いておく
Spring.after_fork do
Qiita::RedisConnections.reset
end