はじめに
- この記事はひとりNEONアドベントカレンダー2020 23日目の記事です
-
昨日は
zip命令を紹介した - 今日は、転置命令の
trn命令1を紹介する - 多分に
zip命令とかぶる部分があるのだが、分量の問題で分けた
arm_neon.hpp
__extension__ extern __inline float32x4x2_t
__attribute__ ((__always_inline__, __gnu_inline__, __artificial__))
vtrnq_f32 (float32x4_t a, float32x4_t b)
{
return (float32x4x2_t) {vtrn1q_f32 (a, b), vtrn2q_f32 (a, b)};
}
"転置"たる所以
- この命令は、2つのベクトルを引数に取るが、他の記事で使ってるような、
srcとdstの組み合わせだとあまり伝わらないので、下図のように引数ベクトルを上下に並べる - 下図では128bitベクトルを2つ取り、32bit幅のレーン4つで分けられている状況(
float32x4_tなど)を表している - 処理前
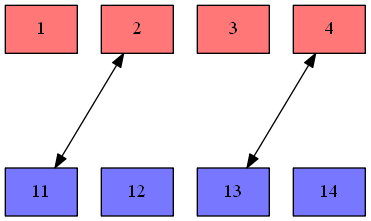
- 演算結果
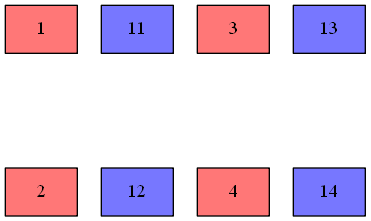
- 参考までに、
int8x16_t型を引数に取る場合は、以下のような結果になる

- このように、2つのベクトル引数を、$2\times2$行列の集合とみなし、要素を転置する
-
zip命令と同じく、128bitベクトル2つを引数に取り、128bitベクトル2つ分の結果を返す命令で、返し方がArm v7 とArm v8で違う
Arm v7 の場合
-
zip命令のときと同じように、戻り値はx2_tが末尾に付いた形になる
trn.cpp
int16x8_t src0, src1;
int16x8x2_t dst = vtrnq_s16(src0, src1);
-
zip命令と同じく、アセンブラでは2レジスタを引数にとり、破壊的操作によりレジスタの内容は結果で上書きされる
Arm v8 の場合
-
trn命令はラッパーとして提供されるが、Arm v8では正しくはtrn1命令とtrn2命令で提供される -
trn1命令では、先程の前半だけ、trn2命令では後半だけ処理される
float32x4_tの転置
- 転置行列が必要な場面として真面目に考えられるのは、
floatを16個集めて$4\times4$行列としてレジスタ内に格納した上で転置する場合である2 - 昔拙wikiで解説したことがあるが、、その時の結論は、
- 最高速を考えるならばインラインアセンブラだが、使い勝手が良くない
-
vget_lowとvget_highとvcombineを組み合わせてレジスタを連結し直す方が、ポータビリティ(Arm v7とArm v8間)が良いので、おすすめ - であった
- しかし、その当時の結論としてはArm v7のNEONに64bit幅の
trn命令がなかったためであり、あればそれに越したことはなかった - そして、このアドベントカレンダーを書いていて64bit幅の
trn命令がArm v8に存在することを発見したので、4年越しに書き換えることにした
trn.cpp
float src[] = { 1.0, 2.0, 3.0, 4.0, 11.0, 12.0, 13.0, 14.0, 100.0,101.0,102.0,103.0, 999.0,998.0,997.0,996.0,};
float dst[16] = { 0 };
float32x4_t vsrc0 = vld1q_f32(src);
float32x4_t vsrc1 = vld1q_f32(src + 4);
float32x4_t vsrc2 = vld1q_f32(src + 8);
float32x4_t vsrc3 = vld1q_f32(src + 12);
float32x4_t vsrc00 = vtrn1q_f32(vsrc0, vsrc1);
float32x4_t vsrc01 = vtrn2q_f32(vsrc0, vsrc1);
float32x4_t vsrc10 = vtrn1q_f32(vsrc2, vsrc3);
float32x4_t vsrc11 = vtrn2q_f32(vsrc2, vsrc3);
float64x2_t vdst0 = vtrn1q_f64(vreinterpretq_f64_f32(vsrc00), vreinterpretq_f64_f32(vsrc10));
float64x2_t vdst1 = vtrn1q_f64(vreinterpretq_f64_f32(vsrc01), vreinterpretq_f64_f32(vsrc11));
float64x2_t vdst2 = vtrn2q_f64(vreinterpretq_f64_f32(vsrc00), vreinterpretq_f64_f32(vsrc10));
float64x2_t vdst3 = vtrn2q_f64(vreinterpretq_f64_f32(vsrc01), vreinterpretq_f64_f32(vsrc11));
vst1q_f32(dst, vreinterpretq_f32_f64(vdst0));
vst1q_f32(dst + 4, vreinterpretq_f32_f64(vdst1));
vst1q_f32(dst + 8, vreinterpretq_f32_f64(vdst2));
vst1q_f32(dst + 12, vreinterpretq_f32_f64(vdst3));
- 実行結果
src:
[1 2 3 4]
[11 12 13 14]
[100 101 102 103]
[999 998 997 996]
dst:
[1 11 100 999]
[2 12 101 998]
[3 13 102 997]
[4 14 103 996]
- ツッコミを入れるならば、
trn1q_f64などの命令はArm v7には存在しないので、その時点でポータビリティもへったくれも無い - ならば、インラインアセンブラで書いてもポータビリティの観点からは同じ
- なお、レイテンシのレベルでまだ最適化の余地は残っていると思う
おわりに
- 転置命令と呼ばれる
trn、trn1、trn2命令を紹介した - 図は、実は各要素を左右反転して表示するのが正しい(0番要素が一番右側、最後の要素が一番左側)
- 要素をまたいだbit shiftとかすると挙動が分かる
- が、そこは本編とは関係ないので割愛する
- 明日も手島の執筆の予定で、ポエムを書く予定です