はじめに
- この記事はひとりNEONアドベントカレンダー2020 22日目の記事です
- 昨日はfp16命令を紹介した
- 今日は
zip命令を紹介する - めずらしくこの命令はArm v7とArm v8でintrinsicが違う
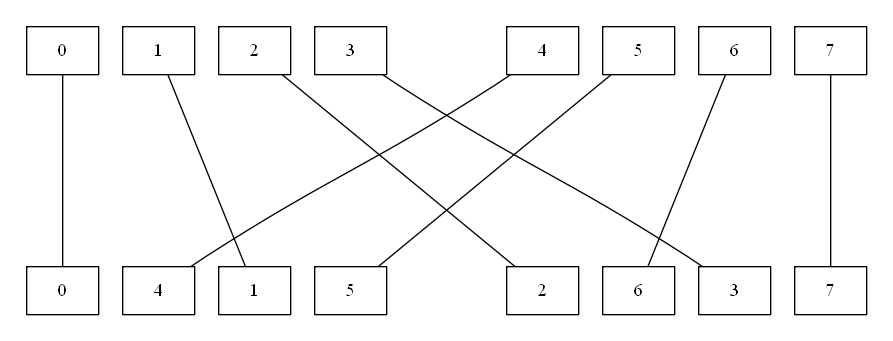
Arm v7の場合
- Raspbian OS 9.9 (Raspberry Pi 3)
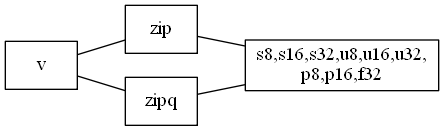
$ grep ^vzip $MY_NEON_FILE | cut -f 1 -d _ | sort | uniq -c
9 vzip
9 vzipq
- シグネチャ(一部修正)
float32x4x2_t vzipq_f32 (float32x4_t __a, float32x4_t __b)
{
Arm v8の場合
- Ubuntu 18.04 (Jetson Nano)
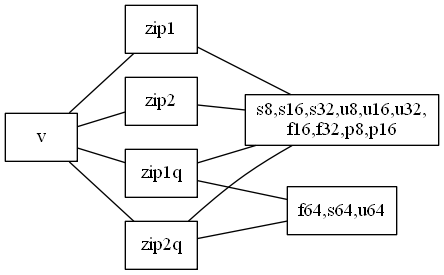
$ grep ^vzip /usr/lib/gcc/aarch64-linux-gnu/7.5.0/include/arm_neon.h | cut -f 1 -d _ | sort | uniq -c
10 vzip1
13 vzip1q
10 vzip2
13 vzip2q
- シグネチャ(一部修正)
float32x4_t vzip1q_f32 (float32x4_t __a, float32x4_t __b)
{
zip命令とzip1命令とzip2命令
- 基本的には2つのベクトル変数を取り、各要素を互い違いにインターリーブする
-
vzipq_f32を例として、色付きで示した下図がわかりやすいと思う。

- suffixが
f32とは言え、レーン単位での並べ替えなので、s32やu32でも動きは変わりない。 - 第1引数の要素0番、第2引数の要素0番、…と続き、第1引数の要素
n-1番、第2引数の要素n-1番(nはレーン数)と続く。 - 128bitベクトルを2つとって、要素を並べ替えるので戻り値も128bitベクトル2つ分になる
- このときの戻り値の扱いで、Arm v7 と Arm v8 で挙動が違う
Arm v7の場合
-
zipq命令の場合、128bit幅ベクトル2つを引数に取り、それぞれの要素をインターリーブする - 例えば、
vzipq_f32命令の場合、戻り値はfloat32x4x2_t型となる- この
x2_tが末尾に付いたやつはload命令の回でも紹介した、ベクトルを複数束ねた構造体である
- この
-
int32x4_t型が引数の場合はint32x4x2_t型が、uint8x16_t型が引数の場合はuint8x16x2_t型が戻り値となる - 128bitベクトル「2つ分」の値を返す必要があるため、構造体で返す形になる
- アセンブラでも同様の挙動が見えて、以下のような命令で表される
float32x4x2_t d = vzipq_f32(a, b);
.s
vzip.32 q10, q11
- アセンブラの
q10とq11はそれぞれ128bit幅レジスタを表す - 2個のオペランドを取るが、出力のオペランドは指定されていない。となると、この命令は破壊的操作を伴う命令で、
q10とq11に結果が書き出される
Arm v8の場合
-
vzip1q命令もvzip2q命令も、どちらも128bit幅ベクトルを2つ引数に取るが、Arm v7と違い、戻り値は128bit幅ベクトル1つ分である - 前述の図で説明すると、インターリーブしたベクトルのうち、片方だけが出力される
- 下図は
vipz1q命令を表した場合
- 下図は
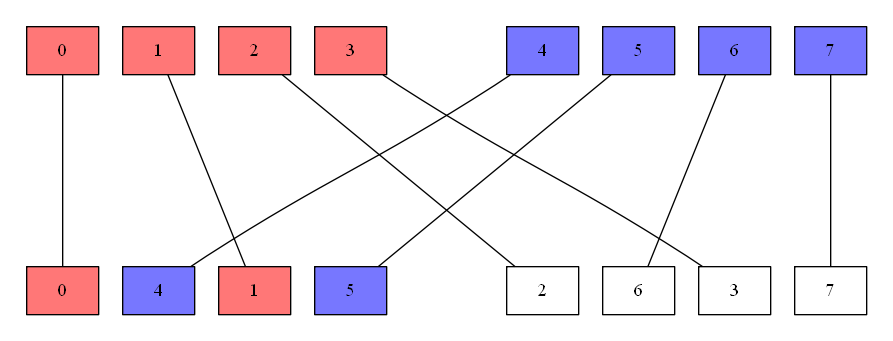
- これは、アセンブラでも確認できる
float32x4x2_t d = vzipq_f32(a, b);
- 本来、
zipq命令はArm v8のgccのintrinsicには無いのだが、利便性を考えてか、gccのarm_neon.hでは、マクロで一括宣言されている
arm_neon.h
# define __DEFINTERLEAVE(op, rettype, intype, funcsuffix, Q) \
__extension__ extern __inline rettype \
__attribute__ ((__always_inline__, __gnu_inline__, __artificial__)) \
v ## op ## Q ## _ ## funcsuffix (intype a, intype b) \
{ \
return (rettype) {v ## op ## 1 ## Q ## _ ## funcsuffix (a, b), \
v ## op ## 2 ## Q ## _ ## funcsuffix (a, b)}; \
}
- これにより、
vzipq命令はvzip1q命令とvzip2q命令を連続して呼ぶコードに変わる - アセンブラを見ると、
zip1命令とzip2命令は、Arm v7のときと違い、3オペランドを取る
.s
zip1 v2.4s, v2.4s, v3.4s
mov v0.16b, v2.16b
:
zip2 v2.4s, v2.4s, v3.4s
mov v1.16b, v2.16b
- これは、先頭から出力先、第1引数、第2引数で表される
- ここでは
zip1命令の出力結果はv2レジスタに書き出されるが、その後v0レジスタに退避されている - また、
zip2命令の出力結果はv2レジスタに書き出された後、v1レジスタに退避されている
OpenCVでの利用
- 実際にOpenCVで使われている部分を見てみよう
- いくつか利用されている箇所があるが、RGBをYUV(YCrCb)に変換するコードで使われている
imgproc/src/color_yuv.simd.hpp
# if CV_SIMD
const int vsize = v_uint8::nlanes;
const int descaleShift = 1 << (shift-1);
v_int16 bg2y;
v_int16 r12y;
v_int16 dummy;
v_zip(vx_setall_s16((short)C0), vx_setall_s16((short)C1), bg2y, dummy);
v_zip(vx_setall_s16((short)C2), vx_setall_s16( 1), r12y, dummy);
- 最後2行に出てくる
v_zipは、OpenCVのUniversal Intrinsicという名前のラッパーであり、Arm環境下では、以下の通り、zipq命令か、zip1qとzip2q命令が呼ばれる
intrin_neon.hpp
# if defined(__aarch64__) || defined(_M_ARM64)
# define OPENCV_HAL_IMPL_NEON_UNPACKS(_Tpvec, suffix) \
inline void v_zip(const v_##_Tpvec& a0, const v_##_Tpvec& a1, v_##_Tpvec& b0, v_##_Tpvec& b1) \
{ \
b0.val = vzip1q_##suffix(a0.val, a1.val); \
b1.val = vzip2q_##suffix(a0.val, a1.val); \
} \
:
# else
# define OPENCV_HAL_IMPL_NEON_UNPACKS(_Tpvec, suffix) \
inline void v_zip(const v_##_Tpvec& a0, const v_##_Tpvec& a1, v_##_Tpvec& b0, v_##_Tpvec& b1) \
{ \
_Tpvec##x2_t p = vzipq_##suffix(a0.val, a1.val); \
b0.val = p.val[0]; \
b1.val = p.val[1]; \
} \
- ここでは、
RGBのうち、GとB要素、R要素と1をそれぞれインターリーブしている - これにより、
v_dotprod命令で係数と掛け合わせた上で和を取る操作を行っている -
v_dotprod命令の特性上、同じ画素の要素が横並びである必要があるため、vld3命令で要素ごとにメモリからロードした後、zip命令でインターリーブするというちょっと面倒くさいことをしている
おわりに
- 今日は
zip命令を紹介した - 明日は転置の
transpose命令を紹介する - 残り日数的に、なんとか完走できそう!?