はじめに
- この記事はひとりNEONアドベントカレンダー2020 9日目の記事です
-
昨日は
sub命令を紹介した。 - 今日は基本中の基本、
load命令を紹介する

$ grep ^vld[1234] /usr/lib/gcc/aarch64-linux-gnu/7.5.0/include/arm_neon.h | cut -f 1 -d ' ' | sed -e 's/[supf][0-9]\+//g' | sort | uniq -c
14 vld1_
14 vld1_dup_
14 vld1_lane_
14 vld1q_
14 vld1q_dup_
14 vld1q_lane_
14 vld2_
14 vld2_dup_
1 vld2_lane_##funcsuffix
14 vld2q_
14 vld2q_dup_
1 vld2q_lane_##funcsuffix
14 vld3_
14 vld3_dup_
1 vld3_lane_##funcsuffix
14 vld3q_
14 vld3q_dup_
1 vld3q_lane_##funcsuffix
14 vld4_
14 vld4_dup_
1 vld4_lane_##funcsuffix
14 vld4q_
14 vld4q_dup_
1 vld4q_lane_##funcsuffix
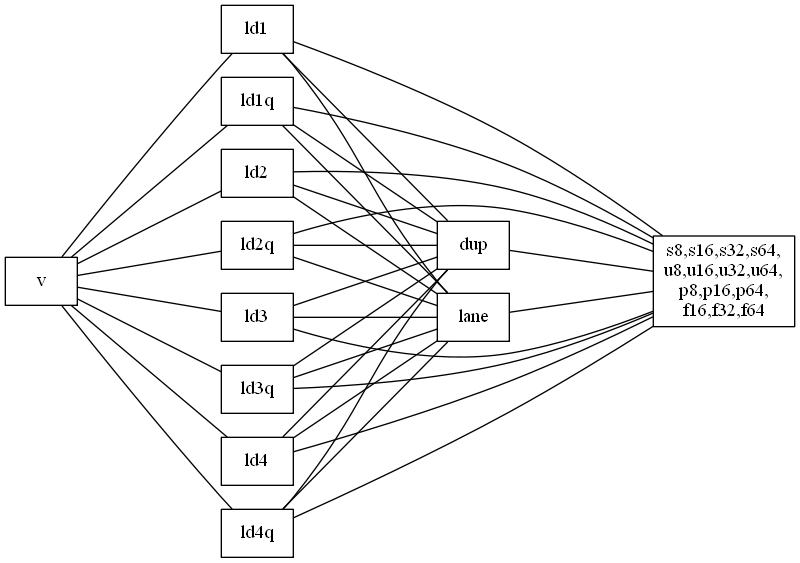
load命令全般の解説
- suffixが全種類ある
- メモリからレジスタに値をロードする
vld1とvld1q(vldnとvldnq)
-
vld1とvld1qが基本形。64bitレジスタと128bitレジスタそれぞれに対応する -
vld2、vld3と数字が増えると、Gatherロードが可能になる - 以下の図は
vld3q_u8を図示したグラフ。- RGBでインターリーブされたメモリ上のデータを、デインタリーブしながらレジスタにロードできる。
- 画像に携わる人間としては神のような命令。
- 以下の図は
vld4q_u8を図示したグラフ。図上部がメモリで図下部がレジスタ- SSEでも
unpack命令を使うことで似たことはできるが、NEONは1命令でできるのでスキ。

- SSEでも

- サンプルコード
ld3q.cpp
uint8_t data[] = { 0, 10, 100, 1, 11, 101, 2, 12, 102, 3, 13, 103, 4, 14, 104, 5, 15, 105, 6, 16, 106, 7, 17, 107, 8, 18, 108, 9, 19, 109, 10, 20, 110, 11, 21, 111, 12, 22, 112, 13, 23, 113, 14, 24, 114, 15, 25, 115,};
uint8_t dst[48] = { 255 };
uint8x16x3_t vsrc = vld3q_u8(data);
vst1q_u8(dst , vsrc.val[0]);
vst1q_u8(dst + 16, vsrc.val[1]);
vst1q_u8(dst + 32, vsrc.val[2]);
- 演算結果
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115
-
RGBを模して、3種類の数列を混ぜたデータをdataとして用意 -
vld3q_u8でロードすると、コード上はuint8x16x3_t型を返す。- 特段ヘンテコな型でなく、単純に128bit幅のレジスタを3個束ねた型
- コード上は長さ3の
uint8x16_tの配列を持つ構造体 - GCCが連続した3つのレジスタを確保してくれる(のだと思う)
-
ld3命令は連続した3つのレジスタにメモリからデータを書き込む
arm_neon.h
typedef struct uint8x16x3_t
{
uint8x16_t val[3];
} uint8x16x3_t;
vld1q_dup
- 指定したアドレスから1要素だけロードし、全要素に代入する。
- 画像にかける係数の値をメモリからロードして全画素に適用するときとかに重宝する
vld2q_dup
- gatherロードした上で、各ベクトルの全要素に代入する
-
vld2qでは先頭の2要素、vld3qでは先頭の3要素、vld4qでは先頭の4要素をそれぞれロードする
.cpp
float data[] = { 1.0f, 2.0f, 3.0f, 4.0f, 10.0f, 20.0f, 30.0f, 40.0f};
float res [] = { -1.0f, -1.0f, -1.0f, -1.0f, -1.0f, -1.0f, -1.0f, -1.0f};
float32x4x2_t a;
a.val[0] = vdupq_n_f32 (0.0f);
a.val[1] = vdupq_n_f32 (100.0f); // 0.0f, 0.0f, 0.0f, 0.0f, 100.f, 100.f, 100.f, 100.f
a = vld2q_dup_f32(data); // 1.0f, 1.0f, 1.0f, 1.0f, 2.0f, 2.0f, 2.0f, 2.0f
0:1
1:1
2:1
3:1
4:2
5:2
6:2
7:2
vld1q_lane
.cpp
float data[] = { 1.0, 2.0, 3.0, 4.0};
float res [] = { -1.0f, -1.0f, -1.0f, -1.0f};
float32x4_t a = vdupq_n_f32 (0.0f); // 0.0f, 0.0f, 0.0f, 0.0f
a = vld1q_lane_f32(data, a, 2); // 0.0f, 0.0f, 1.0f, 0.0f
vst1q_f32(res, a);
0:0
1:0
2:1
3:0
- 指定されたメモリアドレスから1要素だけロードし、指定したレーンに上書きする命令。
- 第3引数がレーンを指定し、0 originで指定する。
- 第3引数は即値しか取れず、コンパイル時に固定されてる必要がある。
.cpp
int i = 2;
a = vld1q_lane_f32(data, a, i); // error: argument 3 must be a constant immediate
.cpp
float data[] = { 1.0, 2.0, 3.0, 4.0, 10.0, 20.0, 30.0, 40.0};
float res [] = { -1.0f, -1.0f, -1.0f, -1.0f, -1.0f, -1.0f, -1.0f, -1.0f};
float32x4x2_t a;
a.val[0] = vdupq_n_f32 (0.0f); // 0.0f, 0.0f, 0.0f, 0.0f,
a.val[1] = vdupq_n_f32 (100.0f); // 0.0f, 0.0f, 0.0f, 0.0f, 100.f, 100.f, 100.f, 100.f
a = vld2q_lane_f32(data, a, 2); // 0.0f, 0.0f, 1.0f, 0.0f, 100.f, 100.f, 2.f, 100.f
vst1q_f32(res, a.val[0]);
vst1q_f32(res + 4, a.val[1]);
0:0
1:0
2:1
3:0
4:100
5:100
6:2
7:100
-
vld1q_laneでは先頭の要素だけロードしたが、vld2q_laneでは2番目の要素まで使う。vld3q_lane,vld4q_laneまで同様に使用する要素数が増える - 参考までに、以下が
vld4q命令を示した図

おわりに
- 今日は
load命令とgather命令としての側面を紹介しました - 明日も手島執筆の予定で、
loadの反対のstore命令を紹介します。
-
NEON完全リファレンスを書いているお話 (ヲレの話を聞け〜! 技術の薄い本、著者からのオススメ Advent Calendar 2019 2日目)3 ↩
-
なお、技術書典8に出すとアドベントカレンダーに書いたにも関わらず、この本はまだ書けていない。 ↩