はじめに
- この記事はひとりNEONアドベントカレンダー2020 5日目の記事です
- 昨日は多すぎるadd命令を紹介したが、
mul命令も多すぎである - というわけで今日は乗算の
mul命令(の一部)を紹介する
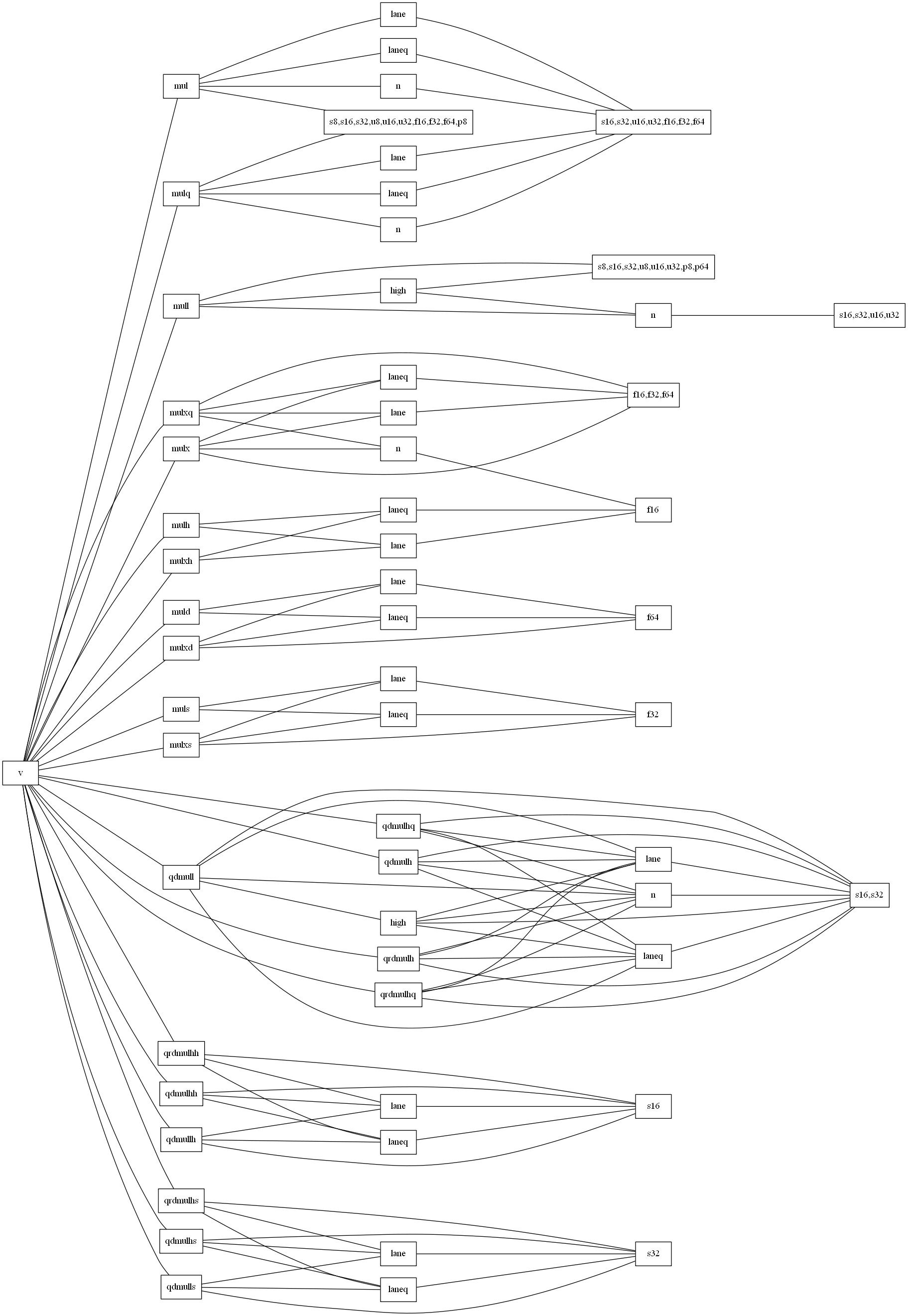
$ egrep ^v.*mul /usr/lib/gcc/aarch64-linux-gnu/7.5.0/include/arm_neon.h | cut -f 1 -d _ | sort | uniq -c
31 vmul
2 vmuld
2 vmulh
24 vmull
31 vmulq
2 vmuls
10 vmulx
3 vmulxd
2 vmulxh
10 vmulxq
3 vmulxs
8 vqdmulh
3 vqdmulhh
8 vqdmulhq
3 vqdmulhs
16 vqdmull
3 vqdmullh
3 vqdmulls
8 vqrdmulh
3 vqrdmulhh
8 vqrdmulhq
3 vqrdmulhs
- 本日は
vmul命令、vmulx命令、vmull命令を紹介する
vmul命令
- 基本的な乗算命令
- 型も、
s8からf64まで、9種類ちゃんと揃えてある- 繰り返しになるが、
vmul_f16、vmulq_f16、及びそれらの派生系命令はArm v8.2 拡張命令である
- 繰り返しになるが、
- 派生型、と記載したけれど、
vmul_lane命令、vmul_n命令が該当する -
vmul_lane命令は、引数を3つとる。1つ目が64bit/128bit幅レジスタ、2つ目が64bit/128bit幅レジスタ、3つ目が指定する要素の位置である- ex1:
vmul_lane_f32 (float32x2_t __a, float32x2_t __b, const int __lane) - ex2:
vmul_laneq_f32 (float32x2_t __a, float32x4_t __b, const int __lane) - ex3:
vmulq_lane_f32 (float32x4_t __a, float32x2_t __b, const int __lane) - ex4:
vmulq_laneq_f32 (float32x4_t __a, float32x4_t __b, const int __lane) - 非常に似た関数シグネチャだが、
qが付く場所と、引数レジスタの幅に注目 - 第3引数の
laneはコンパイル時定数の必要があり、0オリジンで第2引数の要素を指定する - 当然第2引数の範囲外を指定するコンパイルエラーになる
- 第1引数の各要素に、第2引数と第3引数で指定した数値を掛ける。
- ex1:
-
vmul_n命令はvmul_lane命令みたいに面倒なことをしないで、直接乗算する数値を引数にわたす- ex:
vmulq_n_s16 (int16x8_t __a, int16_t __b) - 画像処理屋からすると、フィルタの係数を全画素に乗算する場合とかに使える
- ex:
mul.cpp
float src0[] = { 1.f/0.f, 0.f, -1.f/0.f, 84800.38f,}; // 0番目の要素は正の無限大、2番目の要素は負の無限大
float src1[] = { 0.000f, -3.141592f, 24717.005f, 87145.40f,};
float32x4_t vsrc0 = vld1q_f32(src0);
float32x4_t vsrc1 = vld1q_f32(src1);
float32x4_t vdst = vmulq_f32(vsrc0, vsrc1);
- 演算結果
0:nan
1:-0
2:-inf
3:7.38996e+09
vmulx命令
- 調べたのだが、公式のドキュメント もイマイチ的を得ない
- 個人的に調べた結果を述べると、$0 \times \infty $ が発生した場合、演算結果が
2になるという謎命令
mulx.cpp
float src0[] = { 1.f/0.f, 0.f, -1.f/0.f, 84800.38f,}; // 0番目の要素は正の無限大、2番目の要素は負の無限大
float src1[] = { 0.000f, -3.141592f, 24717.005f, 87145.40f,};
float32x4_t vsrc0 = vld1q_f32(src0);
float32x4_t vsrc1 = vld1q_f32(src1);
float32x4_t vdst = vmulxq_f32(vsrc0, vsrc1);
- 前節のサンプルコードと全く同じデータに対して、
vmulx命令を使用してみた - 演算結果
0:2
1:-0
2:-inf
3:7.38996e+09
- 最初の演算結果が
2になっている - それ以外の結果は
vmul(通常の乗算)と同じ
vmull命令
- おなじみ、末尾に
l(エル)が付いた派生系 - 引数は64bit幅レジスタが2つ。戻り値は128bitレジスタとなる
- ex:
int32x4_t vmull_s16 (int16x4_t a, int16x4_t b) - オーバーフローに配慮した優しい実装となっております
- ex:
-
vmull命令には、vmull_high命令、vmull_n命令の派生系もあり、なんとその組み合わせのvmull_high_n命令もある- 仕組みはそれぞれ単純で、
vmull_high命令では第2引数が128bit幅のレジスタになるが、使われるのは上位64bitだけ -
vmull_n命令では、第2引数がベクトルでなく、単体の数値になる。同じ値を第1引数の各要素に掛け合わせる
- 仕組みはそれぞれ単純で、
おわりに
-
mul命令も多すぎである - 明日も私の予定で、執筆時点では比較命令系を紹介する予定である