はじめに
- この記事はひとりNEONアドベントカレンダー2020 6日目の記事です
-
昨日の
mul命令とは変わって、今日は比較命令系を紹介する
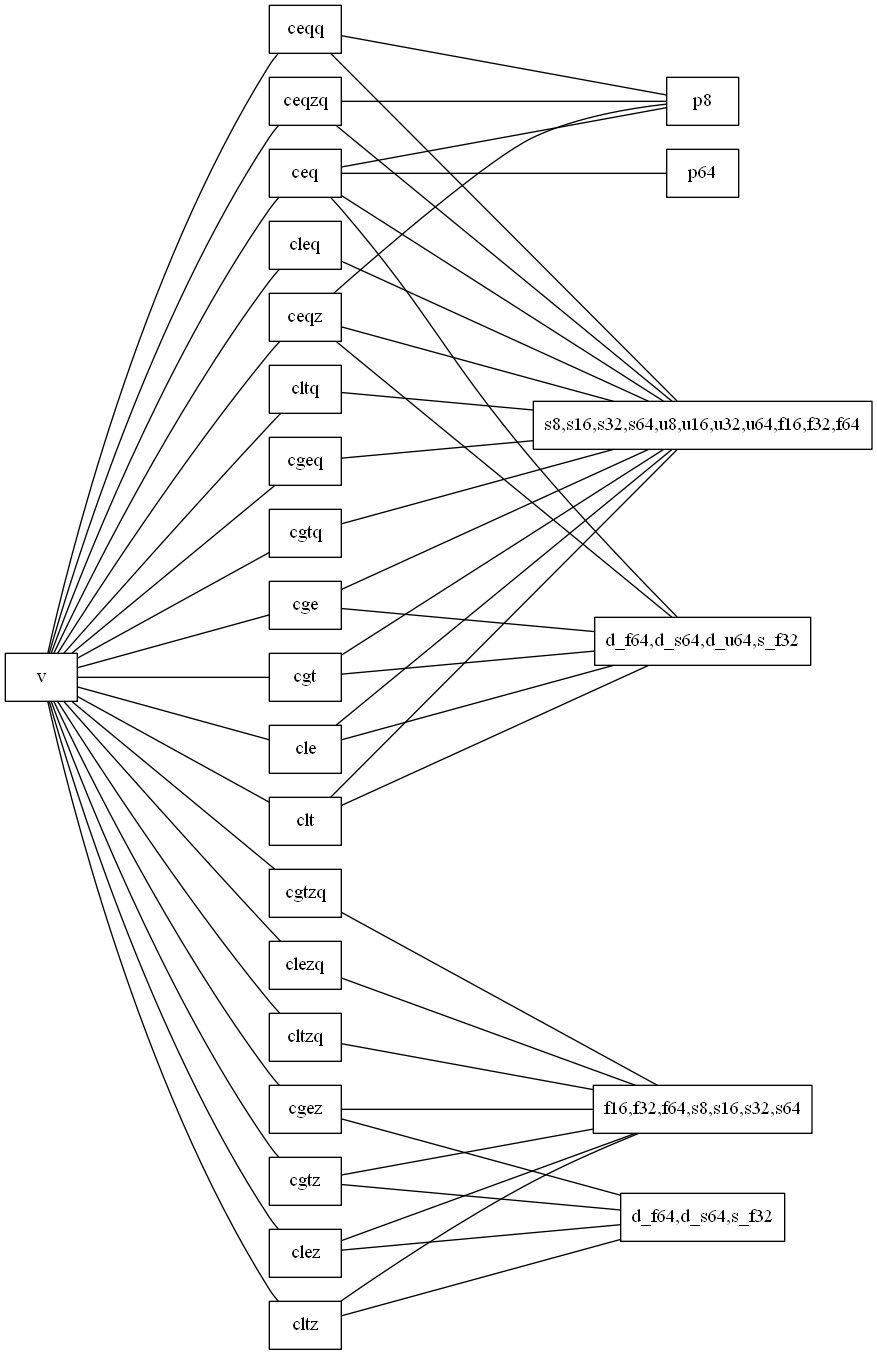
- なんと無しに冒頭に書いてる命令の樹形図、今回が一番きれいに見える。
-
p8、p64の多項式型と単一の引数を取る命令を除去すればもっときれいになるけれど、それだと目的と手段が逆転してきてしまうので・・・
-
$ grep -e ^vceq -e ^vclt -e ^vcgt -e ^vcle -e ^vcge /usr/lib/gcc/aarch64-linux-gnu/7.5.0/include/arm_neon.h | cut -f 1 -d _ | sort | uniq -c
13 vceq
3 vceqd
12 vceqq
1 vceqs
12 vceqz
3 vceqzd
12 vceqzq
1 vceqzs
11 vcge
3 vcged
11 vcgeq
1 vcges
7 vcgez
2 vcgezd
7 vcgezq
1 vcgezs
11 vcgt
3 vcgtd
11 vcgtq
1 vcgts
7 vcgtz
2 vcgtzd
7 vcgtzq
1 vcgtzs
11 vcle
3 vcled
11 vcleq
1 vcles
7 vclez
2 vclezd
7 vclezq
1 vclezs
11 vclt
3 vcltd
11 vcltq
1 vclts
7 vcltz
2 vcltzd
7 vcltzq
1 vcltzs
-
OpenCVの
intrin_neon.hppでも、universal intrinsicでの比較演算子がオーバーロードされている
intrin_neon.hpp
inline _Tpvec operator == (const _Tpvec& a, const _Tpvec& b) \
{ return _Tpvec(cast(vceqq_##suffix(a.val, b.val))); } \
inline _Tpvec operator != (const _Tpvec& a, const _Tpvec& b) \
{ return _Tpvec(cast(vmvnq_##not_suffix(vceqq_##suffix(a.val, b.val)))); } \
inline _Tpvec operator < (const _Tpvec& a, const _Tpvec& b) \
{ return _Tpvec(cast(vcltq_##suffix(a.val, b.val))); } \
inline _Tpvec operator > (const _Tpvec& a, const _Tpvec& b) \
{ return _Tpvec(cast(vcgtq_##suffix(a.val, b.val))); } \
inline _Tpvec operator <= (const _Tpvec& a, const _Tpvec& b) \
{ return _Tpvec(cast(vcleq_##suffix(a.val, b.val))); } \
inline _Tpvec operator >= (const _Tpvec& a, const _Tpvec& b) \
{ return _Tpvec(cast(vcgeq_##suffix(a.val, b.val))); }
早見表
| 命令 | 引数 | 比較処理 |
|---|---|---|
ceq |
a,b
|
a == b |
ceqz |
a |
a == 0 |
cge |
a,b
|
a >= b |
cgez |
a |
a >= 0 |
cgt |
a,b
|
a > b |
cgtz |
a |
a > 0 |
cle |
a,b
|
a <= b |
clez |
a |
a <= 0 |
clt |
a,b
|
a < b |
cltz |
a |
a < 0 |
- しばらく早見表を眺めていると、比較命令の命名規則が見えてくる。
-
vとcompareの頭文字cが頭について、 -
eqがequal -
geがgreater or equal -
gtがgreater than -
leがless or equal -
ltがless than - 命令の種類の後に
zが付くと、0との比較になり、引数として取るのは単一のベクトル -
zがつかない場合は、2つのベクトルを引数にとり、それぞれのベクトル内の要素ごとの比較になる - 最後に
qが付くと、引数は128bit幅のベクトル、qがつかない場合は64bit幅のベクトル
-
使い方
- 比較命令の結果が真の場合、レーン内のbitが全部立つ
- フラグを返すので、処理結果は全て符号なし整数型
-
float32x4_tの引数でも結果はuint32x4_t - 以下のサンプルコードで結果を見てみよう
cmp.cpp
int16_t src0[] = {24, 20, 16, 12, 8, 4, 0, -4,};
int16_t src1[] = {1, 2, 3, 5, 8, 13, 21, 34,};
int16x8_t vsrc0 = vld1q_s16(src0);
int16x8_t vsrc1 = vld1q_s16(src1);
uint16x8_t vceq = vceqq_s16(vsrc0, vsrc1);
uint16x8_t vceqz = vceqzq_s16(vsrc0);
uint16x8_t vcge = vcgeq_s16(vsrc0, vsrc1);
uint16x8_t vcgez = vcgezq_s16(vsrc0);
uint16x8_t vcgt = vcgtq_s16(vsrc0, vsrc1);
uint16x8_t vcgtz = vcgtzq_s16(vsrc0);
uint16x8_t vcle = vcleq_s16(vsrc0, vsrc1);
uint16x8_t vclez = vclezq_s16(vsrc0);
uint16x8_t vclt = vcltq_s16(vsrc0, vsrc1);
uint16x8_t vcltz = vcltzq_s16(vsrc0);
- 実行結果
24 20 16 12 8 4 0 -4 # vsrc0
1 2 3 5 8 13 21 34 # vsrc1
0 0 0 0 ffff 0 0 0 # ceq
0 0 0 0 0 0 ffff 0 # ceqz
ffff ffff ffff ffff ffff 0 0 0 # cge
ffff ffff ffff ffff ffff ffff ffff 0 # cgez
ffff ffff ffff ffff 0 0 0 0 # cgt
ffff ffff ffff ffff ffff ffff 0 0 # cgtz
0 0 0 0 ffff ffff ffff ffff # cle
0 0 0 0 0 0 ffff ffff # clez
0 0 0 0 0 ffff ffff ffff # clt
0 0 0 0 0 0 0 ffff # cltz
- マスクが出来るので、
andやnotのorを取れば、比較結果が真の値だけ取り出すこともできる- レーンごとにbit反転する場合は
mvn命令でbit反転が可能
- レーンごとにbit反転する場合は
おわりに
- 明日も私が執筆の予定で、執筆時点での予定では
div命令系について紹介する