前提
- terraform 0.12以降の書き方を含みません。
書くこと
- (利用者向けの)BigQuery周りの権限管理をterraformで管理する方法(一例)
- ※一例なので、良い方法は常に模索したい。
書かないこと
- terrformの基本的な使い方
設定方針
- 分析基盤の考え方は、過去の記事をご参考に。
- 分析基盤において、利用者向け以外のdatasetは、利用者に対して隠したい。
- 分析基盤の利用者(≠管理・運用者)に対して、集計結果のテーブル群のあるdataset「data_mart」へのRead権限を渡す。
- 同時に利用者が自由にテーブルを作成できるdataset「sandbox」へのRead& Write権限を渡す。
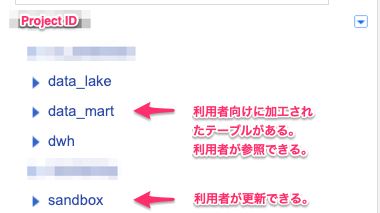
- この場合、利用者を登録する際には、IAM「BigQueryのjobUser」と各datasetにユーザID毎の共有権限を設定する必要がある。(←ここを楽にコードで管理しておきたい。)
設定方法
事前準備
- IAMやdatasetを発行できるサービスアカウントの作成と、秘密鍵の作成
- サービスアカウントに必要な役割
- Project IAM 管理者(※強い権限なので、扱い注意)
- BigQuery データオーナー
- 編集者
- サービスアカウントに必要な役割
terraformテンプレートファイルの作成(一例)
構成
- ただし、terraform.tfstateに関するファイルは下記に含みません。
├─ config.tf
├─ iam.tf
├─ bq_dataset.tf
└─ variables.tf
config.tf
- GCP上の設定内容を編集する用
config.tf
provider "google" {
project = "<your project name>"
region = "<your region>"
credentials = "<サービスアカウントの秘密鍵のjsonファイルのパス>"
}
iam.tf
- IAM権限のうち、BigQueryのjobUserに関して編集するため用
iam.tf
resource "google_project_iam_binding" "bigquery-job-user" {
project = "<your project name>"
role = "roles/bigquery.jobUser"
members = [for s in "${var.user_list}" : format("user:%s", s)]
}
bq_dataset.tf
- BigQueryのdatasetの共有権限に関して編集するため用
- リソース名「datamart」、「sandbox」は適宜変更ください
- defaultで設定されているはずの、projectOwners/projectReaders/projectWritersの設定を引き続き残す場合は、これも記述しておきます。
bq_dataset.tf
resource "google_bigquery_dataset" "datamart" {
dataset_id = "data_mart"
project = "<your project name>"
description = "<description>"
location = "<your location>"
access {
role = "OWNER"
special_group = "projectOwners"
}
access {
role = "READER"
special_group = "projectReaders"
}
access {
role = "WRITER"
special_group = "projectWriters"
}
dynamic "access" {
for_each = var.user_list
content {
role = "READER"
user_by_email = access.value
}
}
}
resource "google_bigquery_dataset" "sandbox" {
dataset_id = "sandbox"
project = "<your project name>"
description = "<description>"
location = "<your location>"
access {
role = "OWNER"
special_group = "projectOwners"
}
access {
role = "READER"
special_group = "projectReaders"
}
access {
role = "WRITER"
special_group = "projectWriters"
}
dynamic "access" {
for_each = var.user_list
content {
role = "WRITER"
user_by_email = access.value
}
}
}
variables.tf
- defaultに、利用者のGoogleアカウントIDを追加していく方針
variables.tf
variable user_list {
type = list(string)
description = "list of user list"
default = [
<user1@xxx.xxx>,
<user2@xxx.xxx>,
...
]
}
terraformを操作して、利用者をIAMとdatasetに追加。
初回実行時は、terraformファイルのあるフォルダで初期化を実行
terraform init
ファイルの変更差分をチェック
terraform plan
変更ファイルの内容を本番に適用
terraform apply
環境にアカウントが反映されたことをIAM画面やdataset共有リストで確認
(Google Cloud consoleやBigQuery Consoleで確認。)
もし既に、利用済みのIAM役割や共有設定済みのdatasetをterraformで管理したい場合は、、、
"terraform import"コマンドで、tfstateファイルへのimportを行う
terraform import google_project_iam_binding.bigquery-job-user "<your project name> roles/bigquery.jobUser"
terraform import google_bigquery_dataset.datamart data_mart
terraform import google_bigquery_dataset.sandbox sandbox
"terraform plan"コマンドを繰り返しながら、差分を解消する
- iam.tfのリソース「google_project_iam_binding.bigquery-job-user」のmembers, bq_dataset.tfのリソース「google_bigquery_dataset.data_mart/sandboxのaccessに差分のあるユーザを追加します。
差分が解消されたら、"terraform apply"
参考
-
データレイク構築後の四方山話 P36
- 利用者の権限管理とポリシーの考え方が参考になります。
- terraform周りのドキュメント