はじめに
ByteTrackとは,2021年10月にarXivに投稿された複数物体追跡(Multiple Object Tracking)の分野でSOTA(state of the art)を達成したアルゴリズムです.
なんでByteという名前がついているのかは良くわかりません...
ByteDanceが開発に関わっているからかな?そこらへんの真偽は不明です.
どのBounding boxもトラックを構成する重要な要素であるという考え方をもとに,その様子がまるでコンピュータにおける重要な要素であるByte(8bit)のようだからByteと名付けられたそうです.(よくわかりません)
本記事ではByteTrackの内容についてざっくりと,片手間程度に理解できるように,あくまで私調べ,私が噛み砕いた内容を記載しています.詳細な内容を厳密に知りたい場合は原著論文を参考にしてください.
原著論文はこちらから.
ByteTrackのGitHubはこちらから.

こちらのgifは実際に自分で収録したカメラ映像にBYTETrackを適用した様子です.オクルージョンにも対応できている様子が確認できますが,ここら辺の仕組みは自分の研究内容に関わるので目処が立ったら執筆します.
!!警告!!
当記事で使用している図やgifは論文から引用したもの以外全て自分で作ったものです.他で無断転載する等の行為はおやめください.
ByteTrackとは
まずはByteTrackのabstract(要約)をご覧ください.(執筆する事情で少しだけ訳を変えていますが,原著論文の意味を超えていることはありません)
複数物体追跡は映像の中の物体のBounding boxとIDを推定するタスクである.多くの手法は,物体を検出する際に閾値よりも大きいscoreを持つboxのみをIDと対応付けする.この閾値処理により,例えば部分的に隠れている(オクルージョン)物体などの低scoreの物体は,検出から棄却されてしまっている,しかしこれらの物体は部分的に隠れているとはいえ実際にそこにあるのは間違いがないので,単純に閾値処理により棄却するのは精度の低下につながる.この問題を解決するため,我々は単純,効果的でかつ汎用的な手法を考案した.低いscoreの物体に対しても単純に棄却するのではなくそれらを活用するような手法である.この手法を9つの異なる検出器に適用したところ,どの検出器もIDF1(MOT評価指標の1つ)の向上が見られた.我々はこの単純で強力なトラッカーをByteTrackと名付けた.MOT17のテストデータでMOTAが80.3,IDF1が77.3,HOTAが63.1を達成した.
要するに,
・今までのアルゴリズムとは違って低い検出scoreのBounding Boxも活用するよ
・他の検出器にこのアルゴリズムを適用したら軒並みMOT評価指標の結果が向上したよ
・SOTAを達成したよ
とまぁこんな感じです.
個人的な感想ですが,意外と誰でも思いつきそうな(失礼)やり方だけどとんでもない計算速度と結果を残しているのがすごいなぁと思います.
それでは以下からその詳細について詳しく見ていきます.
ByteTrackの構造
まず,ByteTrackは大まかに以下のような構造/仕組みになっています.以下の図をご覧ください.

大まかに,
- フレームからbounding box,score,classを出力する物体検出器
- その検出結果と,現時点で追跡している物体のIDを紐付けるByte
という構造になっています.
Byteアルゴリズム
Byteアルゴリズムとは一体なんなのかを解説します.
Byteアルゴリズムの大まかな流れは以下の図の通りです.

t-1フレームまでの追跡から,次のtフレーム目での位置をKalman Filterにより予測します.(Kalman Filterの解説はこちら)
その予測されたBounding Boxとtフレーム目での実際の検出結果の重なり度合い(IoU : Intersection over union)をもとに,閾値判定を施しながら一番IoUが大きいもの同士をマッチングします.
ここまでくると従来のトラッカーと何も変わらないように見えますが,ByteアルゴリズムはこのIoUでのマッチングの際に単純だが非常に効果的な工夫を施しています.
その部分について以下で解説します.
Byteアルゴリズムの工夫点
通常のトラッカーではIoUでのマッチングは一回で終わらせますが,Byteアルゴリズムはこれを二段階に分割してマッチングを行っています.
以下の図をご覧ください.
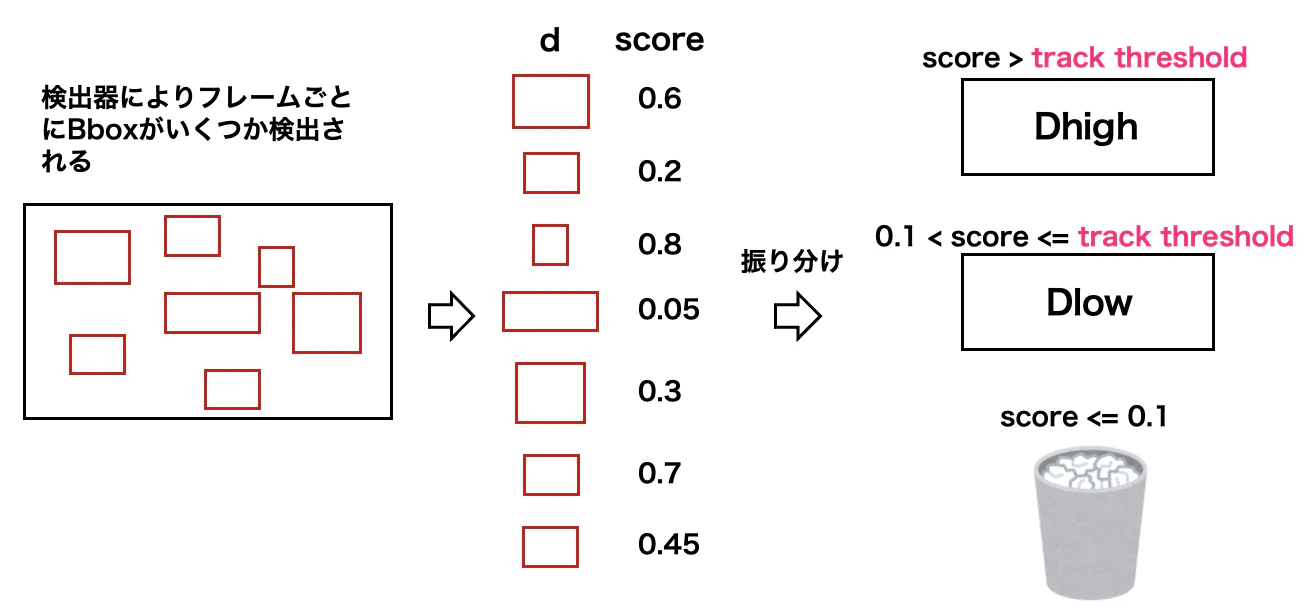
まず,検出器から得られたフレーム内のbounding boxを,そのscoreを利用して
- $D_{high}$
- $D_{low}$
- 棄却
のいずれかに振り分けます.振り分ける際には,閾値を利用します.
図中に0.1という閾値が見られると思いますが,こちらに関しては元のコードを参照した際にマジックナンバーとして設定されていたため開発した方がなぜ0.1にしたのかはわかりません...申し訳ございません.論文中には0.2と書かれていましたが,その理由は書かれておらず,コードにはなぜか0.1と書いてあったのでそのまま使用しています.実際に0.1で動かしたところ正常に動作することは確認済みです.
(ByteTrackのGitHubはこちら.)
この処理により得られた
- $D_{high}$
- $D_{low}$
を,次の処理で用いることになります.以下の図をご覧ください.
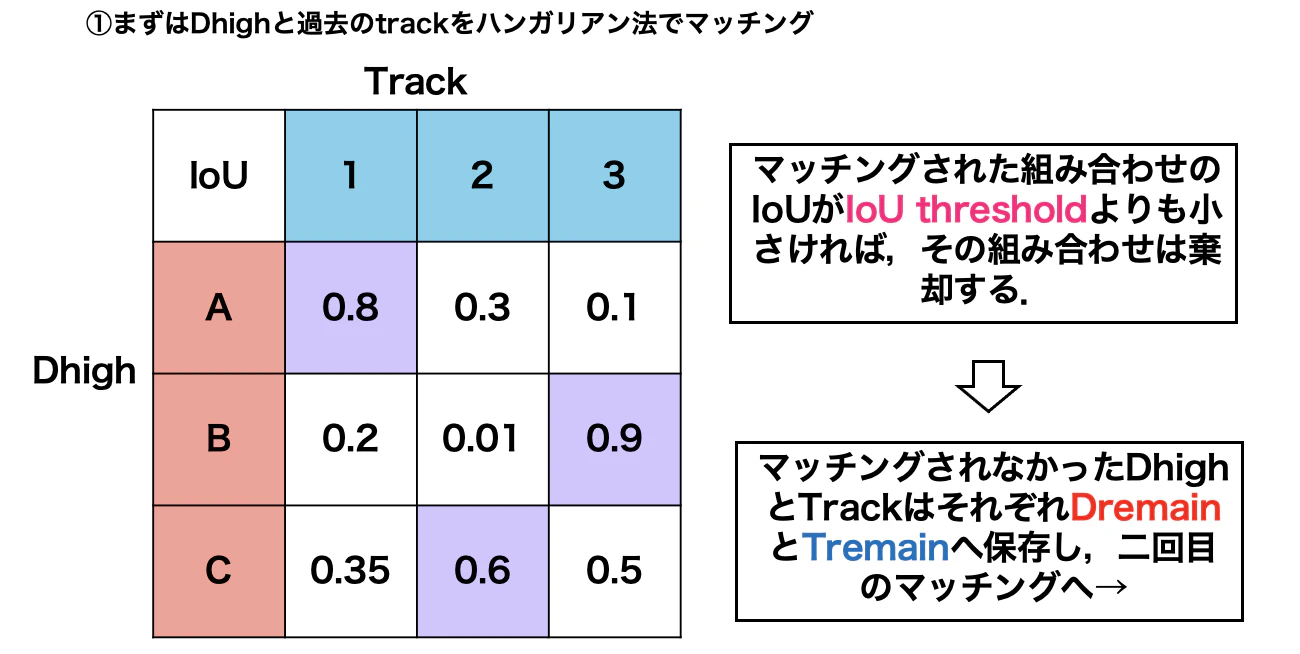
こちらが一段階目のマッチングです.一段階目のマッチングでは$D_{high}$と1フレーム前までのtrackとのマッチを行います.
ここで用いられているマッチングアルゴリズムはハンガリアン法です.(ハンガリアン法の解説はこちら)
そうして得られたマッチングは新たにtrackに加えることでtrackを更新します.
マッチングされなかった$D_{high}$は$D_{remain}$へ,マッチングされなかったtrackは$T_{remain}$へ保存します.
こうして得られた$T_{remain}$と,$D_{low}$を二段階目のマッチングに使用します.以下の図をご覧ください.

このマッチングもハンガリアン法で行います.
得られたマッチングは新たにtrackに加えることでtrackを更新し,マッチングされなかったtrackは$T_{re-remain}$へ保存し,trackから$T_{re-remain}$は削除します.
(正確には$T_{re-remain}$は$T_{lost}$という消失された検出として保存され,30フレームだけ保持されます.)
最後に,$D_{remain}$の中でtrack threshold + 0.1よりもscoreが大きいものは,新たにフレームに入ってきた新規車両としてtrackに保存し,更新します.
この図の中でも0.5という閾値が出てきていますが,こちらも元コードにマジックナンバーとして扱われていた数字で,0.5にした意図は計りかねますが,0.5で動作することは確認済みです.
(ByteTrackのGitHubはこちら.)
この処理を毎フレーム繰り返し,動画全体でトラッキングを行うのがByteアルゴリズムです.
評価
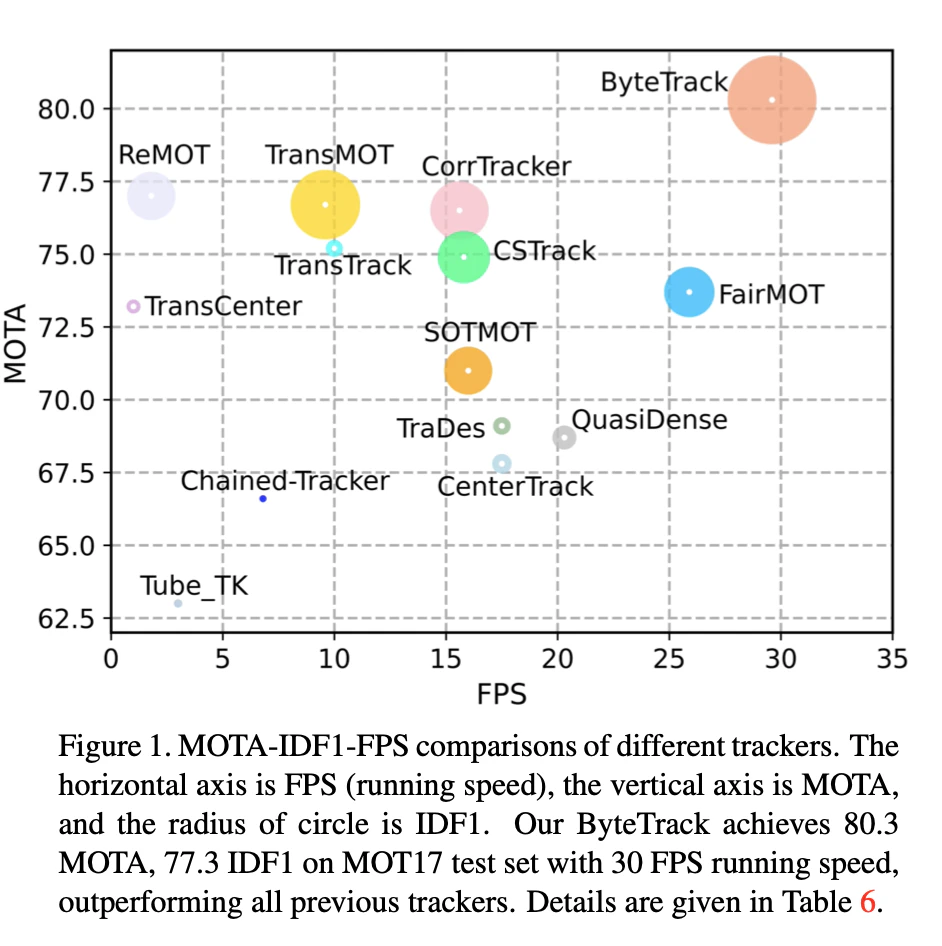
(原著論文から引用しています.)
みてわかる通り,fps,MOTA,IDF1いずれもSOTAを達成していることがわかります.
おわりに
以上がByteアルゴリズムの全容の大雑把な解説でした.
実際に動かしてみた感想ですが,本当に安定していて本当に早い.YOLOX自体早いアルゴリズムではないために,こんな単純な対応付けアルゴリズムでSOTAを達成しているのがまだまだ未来を感じさせますね.
大学で物体追跡の研究をしているのですが,このアルゴリズムを導入したところスコアが大幅に飛躍しました.
これから検出器の進化と共にさらに精度の向上が見込めますので,とても楽しみです.
本記事が初めての執筆で,至らないところ,ミス等色々あるかもしれません.
ご意見等,ご指摘等ありましたらコメントしていただけると幸いです.よろしくお願いいたします.