E資格(2022#1)に合格しました。本記事は、受験時の勉強ノートをもとにClaudeを使って整理したものです。今回は深層学習編です。
- 3.深層学習の基礎
- ⑴ 順伝播型ネットワーク
- ⅰ. 多層パーセプトロン
- 全結合層、重み、バイアス
- ⅱ. 出力層と損失関数
- 回帰、平均二乗誤差(MSE)、平均絶対誤差(MAE)、2値分類、バイナリクロスエントロピー、多クラス分類、クロスエントロピー誤差、ソフトマックス関数、one-hotベクトル、マルチラベル分類、順序回帰
- ⅲ. 活性化関数
- シグモイド関数、温度パラメータ、勾配消失、ReLU、Leaky ReLU、GELU、tanh、双曲線関数
- ⑵ 深層モデルのための最適化
- ⅰ. 基本的なアルゴリズム
- 確率的勾配降下法(SGD)、学習率、最急降下法、ミニバッチ、モメンタム、Pathological Curvature、Momentum、Nesterov Accelerated Gradient
- ⅱ. 誤差逆伝播法
- 誤差逆伝播法、連鎖律、偏微分によるデルタ、勾配消失、自動微分、計算グラフ
- ⅲ. 適応的な学習率を持つアルゴリズム
- AdaGrad、RMSProp、Adam
- ⅳ. パラメータの初期化戦略
- Xavier法/Glorot法、Kaiming法/He法
- ⑶ 深層モデルのための正則化
- ⅰ. パラメータノルムペナルティー
- L1正則化、スパース表現、L2正則化、weight decay
- ⅱ. 確率的削除
- ドロップアウト、ドロップコネクト
- ⅲ. 陰的正則化
- 早期終了、バッチサイズ、学習率の調整
- ⑷ 畳み込みニューラルネットワーク
- ⅰ. 畳み込みニューラルネットワーク
- 基本的な畳み込み演算、単純型細胞と複雑型細胞、受容野(receptive field)、特徴マップ、フィルタ、カーネル、パディング、ストライド、im2col、チャネル
- 特別な畳み込み、point-wise畳み込み(1x1畳み込み)、depth-wise畳み込み、グループ化畳み込み、アップサンプリングと逆畳み込み
- プーリング、Max pooling、Lp pooling、Global Average Pooling
- ⑸ リカレントニューラルネットワーク
- ⅰ. リカレントニューラルネットワーク
- 順伝播の計算、逆伝搬の計算(Back Propagation Through Time; BPTT)、双方向RNN
- ⅱ. ゲート機構
- 勾配消失、忘却ゲート、入力ゲート、出力ゲート、LSTM(長期記憶と短期記憶)、GRU、リセットゲート、メモリーセル
- ⅲ. 系列変換
- エンコーダ・デコーダ、sequence-to-sequence(seq2seq)、アテンション(注意)機構
- ⑹ Transformer
- ⅰ. Transformer
- Self-Attention、Scaled Dot-Product Attention、Source Target Attention、Masked Attention、Multi-Head Attention、Positional Encoding
- ⑺ 汎化性能向上のためのテクニック
- ⅰ. データ集合の拡張
- 画像のデータ拡張、ノイズ付与、Random Flip・Erase・Crop・Contrast・Brightness・Rotate、RandAugment、MixUp、自然言語のデータ拡張、EDA、MixUp、音声のデータ拡張、ノイズ付与、ボリューム変更、ピッチシフト、MixUp、SpecAugment
- ⅱ. 正規化
- Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization
- ⅲ. アンサンブル手法
- バギング、ブースティング、ブートストラップ、スタッキング
- ⅳ. ハイパーパラメータの選択
- 基本的なハイパーパラメータ調整、学習率、隠れ層の数 (レイヤー層数)、ユニット数、ドロップアウトの割合、バッチサイズ、ハイパーパラメータの最適化、グリッドサーチ、ランダムサーチ、ベイズ最適化
⑴ 順伝播型ネットワーク
ⅰ. 多層パーセプトロン
キーワード:全結合層、重み、バイアス
■ Multilayer Perceptron
- 入力層+隠れ層+出力層
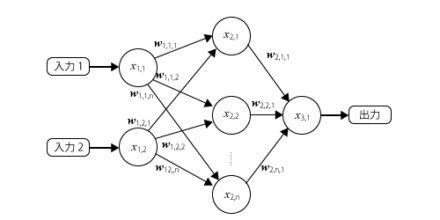
- 入力層+隠れ層+隠れ層+出力層


ⅱ. 出力層と損失関数
キーワード:回帰、平均二乗誤差(MSE)、平均絶対誤差(MAE)、2値分類、バイナリクロスエントロピー、多クラス分類、クロスエントロピー誤差、ソフトマックス関数、one-hotベクトル、マルチラベル分類、順序回帰
■ 損失関数
\begin{aligned}
&\text{MSE} = \frac{1}{N}\sum_{i=1}^{N}(y_i - \hat{y}_i)^2 \\[4mm]
&\text{Binary Cross-entropy Loss} = -\frac{1}{N}\sum_{i=1}^{N}\left[y_i\log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)\right] \\[4mm]
&\text{Cross-entropy Loss} = -\frac{1}{N}\sum_{i=1}^{N}\sum_{c=1}^{C}y_{i,c}\log(\hat{y}_{i,c}) \\[4mm]
&\text{Total Loss(マルチラベル分類)} = \sum_{j=1}^{K} \text{Binary Cross Entropy}_j \\[4mm]
&\text{Ranking Loss(順序回帰)} = -\frac{1}{N} \sum_{i=1}^{N} \log \frac{1}{\text{rank}_i}
\end{aligned}
■ Label Smoothing
モデルの学習時に、正解ラベルに対して、全てのクラスに少しずつ値を分散させる平滑化処理を行うことで、過学習やモデルの過信を防ぐ。
-
解決できること
- 過学習(Overfitting)の抑制
- モデルの過信(Overconfidence)の軽減
- 汎化性能の向上
- クラス間の関係性を考慮した学習
\begin{array}{ll}
\text{ラベル変換}
& \text{元ラベル } ~ t_k =
\begin{cases}
1 \quad \text{(正解クラス)} \\
0 \quad \text{(不正解クラス)}
\end{cases} \\[4mm]
& \text{平滑化後ラベル } ~
\begin{cases}
1-\epsilon \quad \text{(正解クラス)} \\
\epsilon/(K-1) \quad \text{(不正解クラス)}
\end{cases} \\[4mm]
\text{平滑化ラベル}
& t_k^{LS} = (1-\epsilon)t_k + \epsilon u(k) \\[4mm]
\text{損失関数}
& \mathcal{L} = -\displaystyle\sum_{k=1}^{K} t_k^{LS} \log y_k
\end{array}
ⅲ. 活性化関数
キーワード:シグモイド関数、温度パラメータ、勾配消失、ReLU、Leaky ReLU、GELU、tanh、双曲線関数
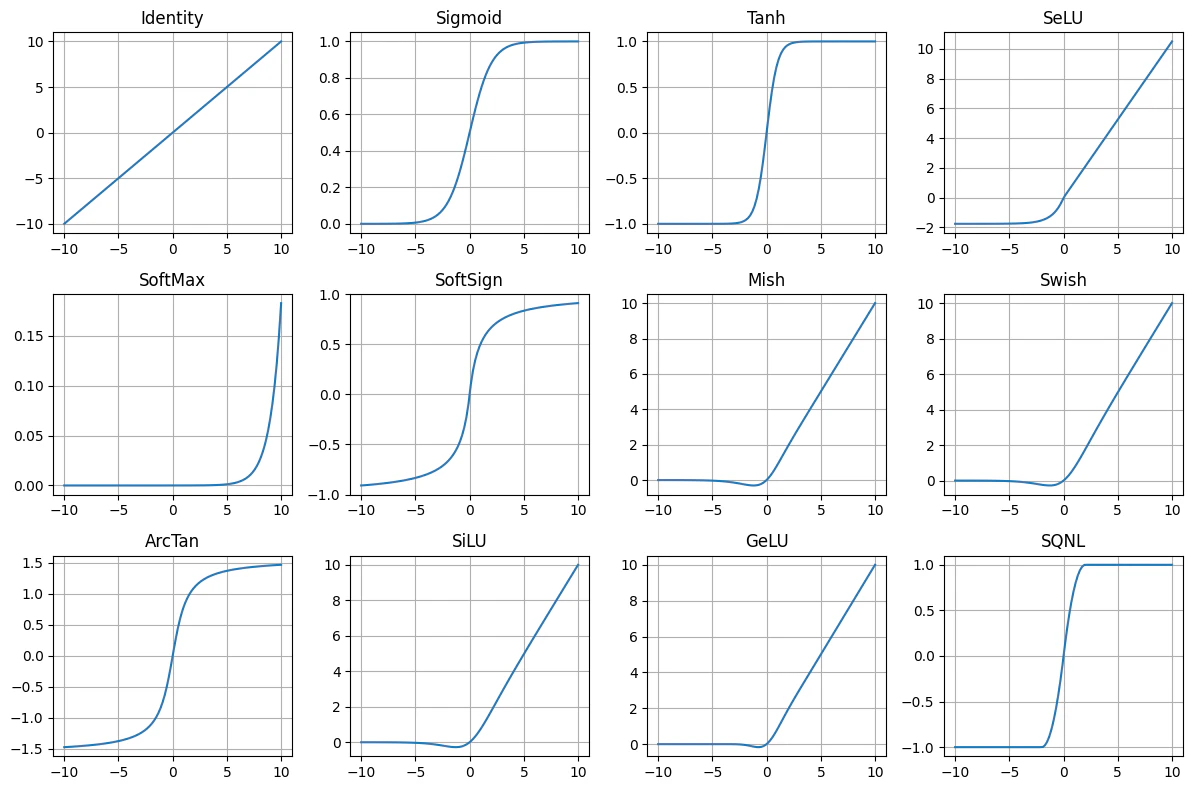
■ 活性化関数(Activation Function)
活性化関数がないと、ニューラルネットワークは単なる線形変換の合成になる。活性化関数により非線形性を導入することで、任意の関数を近似できるようになる。
\begin{aligned}
&\text{Step}
&& f(x) = \begin{cases}
1 & (x > 0) \\
0 & (x \leq 0)
\end{cases}
&& f'(x) = 0\ \text{(通常定義されない)} \\[8mm]
&\text{Identity}
&& f(x) = x
&& f'(x) = 1 \\[8mm]
&\text{Sigmoid}
&& f(x) = \frac{1}{1+e^{-x}}
&& f'(x) = f(x)\left[1 - f(x)\right] \\[8mm]
&\text{Tanh}
&& f(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}
&& f'(x) = 1 - [f(x)]^2 \\[8mm]
&\text{ReLU}
&& f(x) = \max(0, x)
&& f'(x) =
\begin{cases}
1 & (x > 0) \\
0 & (x \leq 0)
\end{cases} \\[8mm]
&\text{Leaky ReLU}
&& f(x) = \max(\alpha x, x)
&& f'(x) =
\begin{cases}
1 & (x > 0) \\
\alpha & (x \leq 0)
\end{cases} \\[8mm]
&\text{ELU}
&& f(x) =
\begin{cases}
x & (x \geq 0) \\
\alpha (e^{x} - 1) & (x < 0)
\end{cases}
&& f'(x) =
\begin{cases}
1 & (x \geq 0) \\
f(x) + \alpha & (x < 0)
\end{cases} \\[8mm]
&\text{GELU}
&& f(x) = x \cdot \Phi(x)
&& f'(x) = \Phi(x) + x\,\phi(x) \\[8mm]
&\text{Swish (SiLU)}
&& f(x) = x \cdot \sigma(x)
&& f'(x) = \sigma(x)\bigl(1 + x(1-\sigma(x))\bigr) \\[8mm]
&\text{Softmax}
&& f_i(\mathbf{x}) = \frac{e^{x_i}}{\sum_j e^{x_j}}
&& \frac{\partial f_i}{\partial x_j} = f_i(\mathbf{x})\left[\delta_{ij} - f_j(\mathbf{x})\right]
\end{aligned}
- $\Phi(x)$:標準正規分布の累積分布関数、$\phi(x)$:その確率密度関数
- $\sigma(x)$:Sigmoid関数
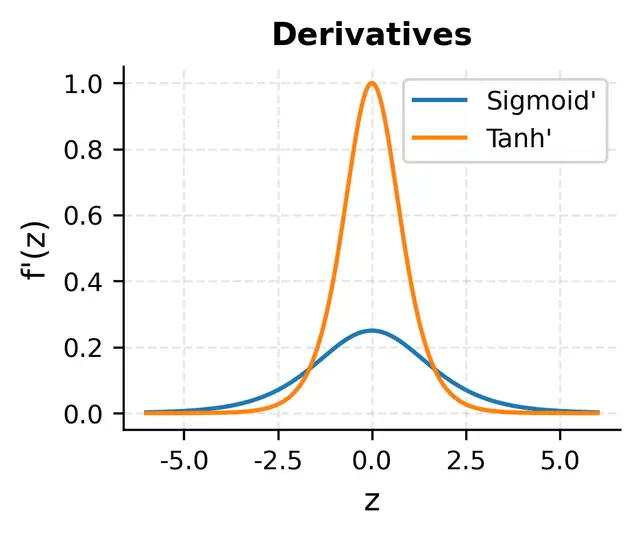
■ 勾配消失・爆発問題
-
Sigmoid関数と勾配消失
- 値域 $f(x) \in (0,1)$、最大値は $f'(x)=0.25$($x=0$ のとき)
- 深層で逆伝播すると導関数の積が $0.25^L$ と急速に小さくなり勾配消失となる
- $x$ が大きいまたは小さいとき $f'(x)\to0$
-
Tanh関数と勾配消失
- 値域 $f(x) \in (-1,1)$、最大値は $f'(x)=1$($x=0$ のとき)
- 多層で飽和領域になると導関数の積が指数的に減少し、勾配消失となる(Sigmoid関数よりマシ)
- $x$ が大きいまたは小さいとき $f(x)\to\pm1$ で $f'(x)\to0$
-
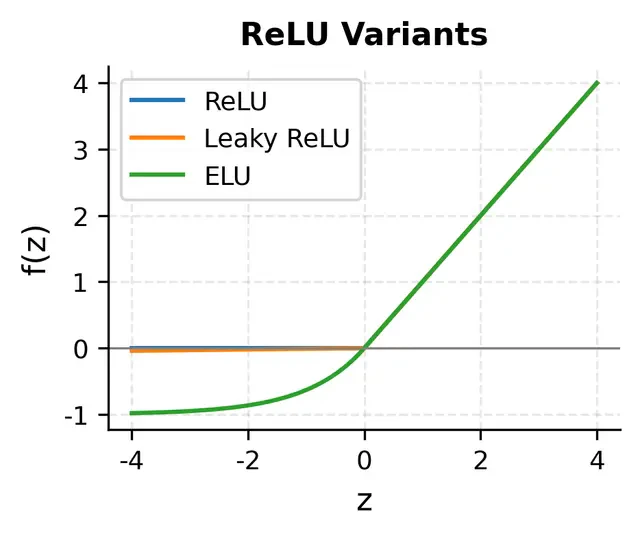
ReLU関数と勾配消失
- $x > 0$ では $f'(x)=1$ なので、勾配が減衰しにくい
- $x \leq 0$ では $f'(x)=0$ のため勾配が消える(dying ReLU問題)
-
Mish・GELU・Swishと勾配消失
- $x \leq 0$ 側に小さな勾配が残るため dying ReLU 問題が起きにくい。
- Mish は YOLOv4 などで成功。自己正則化ReLU。
- GELU は Transformer で使われる。正規分布の累積分布関数 $\Phi(x)$ で近似。
- Swish(SiLU)はEfficientNetなどで使われる。自己ゲーティング。
| Variants | Gradients |
|---|---|
 |
 |
 |
 |
 |
 |
⑵ 深層モデルのための最適化
ⅰ. 基本的なアルゴリズム
キーワード:確率的勾配降下法(SGD)、学習率、最急降下法、ミニバッチ、モメンタム、Pathological Curvature、Momentum、Nesterov Accelerated Gradient
■ ミニバッチ学習
データセット全体を小さなバッチに分割して学習を進める手法で、確率的勾配降下法(SGD)の実用的な実装形態
-
解決できること
- メモリ不足問題の解決
- 学習の高速化(並列計算の活用)
- 局所最適解からの脱出
- 安定した勾配推定とノイズのバランス
-
計算フロー
- データの準備
- 学習データをシャッフルする
- ミニバッチサイズでデータを分割する(例:32, 64など)
- ミニバッチごとの学習処理
- 各エポック(学習周期)で以下を繰り返す
- ミニバッチを1つ選択
- ミニバッチをモデルに入力し、予測値を算出
- 損失(誤差)を計算
- パラメータを更新
- 各エポック(学習周期)で以下を繰り返す
- エポック終了後の評価
- すべてのミニバッチでパラメータ更新後、検証データで性能確認
- 学習率調整や早期終了などの措置
- データの準備


■ SGD with Momentum
| 最適化手法 | 説明 |
|---|---|
| SGD | ランダムに選んだ1サンプルごとにパラメータを更新する基本手法 |
| Momentum | 勾配の流れを考慮し、収束を加速・安定させる手法 |
| Nesterov | 未来の位置での勾配を使い、Momentumをより賢く適用する手法 |
\begin{array}{lll}
\text{SGD}
&\theta_{t+1} = \theta_t - \eta \dfrac{\partial L}{\partial \theta_t}
\\[8mm]
\text{Nesterov}
&v_{t+1} = \alpha v_t - \eta \dfrac{\partial L}{\partial (\theta_t + \alpha v_t)} \\[2mm]
&\theta_{t+1} = \theta_t + v_{t+1}
\\[8mm]
\text{Momentum}
&v_{t+1} = \alpha v_t - \eta \dfrac{\partial L}{\partial \theta_t} \\[2mm]
&\theta_{t+1} = \theta_t + v_{t+1}
\end{array}
ⅱ. 誤差逆伝播法
キーワード:誤差逆伝播法、連鎖律、偏微分によるデルタ、勾配消失、自動微分、計算グラフ
■ Chain Rule
\begin{align*}
&\text{【1変数】} && \\
&\mathcal{L} = g(y), \; y = f(x)
&&\frac{d\mathcal{L}}{dx} = \frac{d\mathcal{L}}{dy} \cdot \frac{dy}{dx} \\[8mm]
&\text{【多変数】} && \\
&\mathcal{L} = g(z), \; z = f(x, y)
&&\frac{\partial \mathcal{L}}{\partial x} = \frac{d\mathcal{L}}{dz} \cdot \frac{\partial z}{\partial x} \\[2mm]
& &&\frac{\partial \mathcal{L}}{\partial y} = \frac{d\mathcal{L}}{dz} \cdot \frac{\partial z}{\partial y} \\[8mm]
&\text{【多層合成】} && \\
&\mathcal{L} = h(w), \; w = g(z), \; z = f(x)
&&\frac{d\mathcal{L}}{dx} = \frac{d\mathcal{L}}{dw} \cdot \frac{dw}{dz} \cdot \frac{dz}{dx} \\[8mm]
&\text{【ベクトル】} && \\
&\mathcal{L} = g(\mathbf{z}), \; \mathbf{z} = f(\mathbf{x})
&&\frac{\partial \mathcal{L}}{\partial \mathbf{x}} = \left(\frac{\partial \mathbf{z}}{\partial \mathbf{x}}\right)^{\top} \frac{\partial \mathcal{L}}{\partial \mathbf{z}}
\end{align*}
■ Backpropagation


- 加算の計算グラフ
z = x + y, \qquad \frac{\partial z}{\partial x} = 1, \qquad \frac{\partial z}{\partial y} = 1

- 乗算の計算グラフ
z = x \cdot y, \qquad \frac{\partial z}{\partial x} = y, \qquad \frac{\partial z}{\partial y} = x

- Affine変換の計算グラフ
\mathbf{Y} = \mathbf{X}\mathbf{W} + \mathbf{B}, \qquad
\frac{\partial L}{\partial \mathbf{X}} = \frac{\partial L}{\partial \mathbf{Y}}\mathbf{W}^{\top}, \qquad
\frac{\partial L}{\partial \mathbf{W}} = \mathbf{X}^{\top}\frac{\partial L}{\partial \mathbf{Y}}, \qquad
\frac{\partial L}{\partial \mathbf{B}} = \frac{\partial L}{\partial \mathbf{Y}}

ⅲ. 適応的な学習率を持つアルゴリズム
キーワード:AdaGrad、RMSProp、Adam
■ 適応的な最適化アルゴリズム
| 最適化手法 | 説明 |
|---|---|
| AdaGrad | パラメータごとに学習率を自動調整し、動きが激しい部分を抑制 |
| RMSprop | 最近の勾配情報で学習率を動的調整し、AdaGradの欠点を解消 |
| Adam | Momentum+RMSpropのハイブリッドで学習率や方向を自動調整する |
| AdamW | Weight Decayを改善したAdam。正則化を勾配ではなく更新時に直接適用 |
| Lion | 符号ベースの更新とMomentumを組み合わせた軽量・高速な最適化手法 |
\begin{array}{lll}
\text{AdaGrad}
&h_{t+1} = h_t + \dfrac{\partial L}{\partial \theta_t} \odot \dfrac{\partial L}{\partial \theta_t}\\[2mm]
&\theta_{t+1} = \theta_t - \eta \dfrac{1}{\sqrt{h_{t+1}} + \epsilon} \odot \dfrac{\partial L}{\partial \theta_t}\\[8mm]
\text{RMSprop}
&h_{t+1} = \rho h_t + (1-\rho)\dfrac{\partial L}{\partial \theta_t} \odot \dfrac{\partial L}{\partial \theta_t}\\[2mm]
&\theta_{t+1} = \theta_t - \eta \dfrac{1}{\sqrt{h_{t+1} + \epsilon}} \odot \dfrac{\partial L}{\partial \theta_t}\\[8mm]
\text{Adam}
&m_{t+1} = \beta_1 m_t + (1-\beta_1) \dfrac{\partial L}{\partial \theta_t}\\[2mm]
&v_{t+1} = \beta_2 v_t + (1-\beta_2) \dfrac{\partial L}{\partial \theta_t} \odot \dfrac{\partial L}{\partial \theta_t}\\[2mm]
&\hat{m}_{t+1} = \dfrac{m_{t+1}}{1-\beta_1^{t+1}}\\[2mm]
&\hat{v}_{t+1} = \dfrac{v_{t+1}}{1-\beta_2^{t+1}}\\[2mm]
&\theta_{t+1} = \theta_t - \eta \dfrac{1}{\sqrt{\hat{v}_{t+1}} + \epsilon} \odot \hat{m}_{t+1}\\[8mm]
\text{AdamW}
&m_{t+1} = \beta_1 m_t + (1-\beta_1) \dfrac{\partial L}{\partial \theta_t}\\[2mm]
&v_{t+1} = \beta_2 v_t + (1-\beta_2) \dfrac{\partial L}{\partial \theta_t} \odot \dfrac{\partial L}{\partial \theta_t}\\[2mm]
&\hat{m}_{t+1} = \dfrac{m_{t+1}}{1-\beta_1^{t+1}}\\[2mm]
&\hat{v}_{t+1} = \dfrac{v_{t+1}}{1-\beta_2^{t+1}}\\[2mm]
&\theta_{t+1} = \theta_t - \eta \left(\dfrac{\hat{m}_{t+1}}{\sqrt{\hat{v}_{t+1}} + \epsilon} + \lambda \theta_t\right)\\[8mm]
\text{Lion}
&m_{t+1} = \beta_1 m_t + (1-\beta_1) \dfrac{\partial L}{\partial \theta_t}\\[2mm]
&c_t = \beta_2 m_t + (1-\beta_2) \dfrac{\partial L}{\partial \theta_t}\\[2mm]
&\theta_{t+1} = \theta_t - \eta \left(\text{sign}(c_t) + \lambda \theta_t\right)
\end{array}
- $h$:勾配二乗の累積(AdaGrad)/移動平均(RMSprop)、$m,,v$:勾配の1次・2次モーメント(Adam)
- $\rho$:RMSprop の減衰率、$\beta_1,\beta_2$:Adam の減衰率(例 $0.9,,0.999$)、$\epsilon$:ゼロ除算防止の微小定数、$\eta$:学習率、$\lambda$:weight decay 係数、$\odot$:要素積
ⅳ. パラメータの初期化戦略
キーワード:Xavier法/Glorot法、Kaiming法/He法
■ Weight Initialization
学習の安定化と効率化のため、各層の重みパラメータを適切な分布で初期化する手法
-
解決できること
- 勾配消失・爆発問題の防止
- 学習の収束速度の向上
- 対称性の破れ(Symmetry Breaking)
- 層間の活性化スケールの適切な維持
-
Xavier/Glorot
https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
Sigmoid/tanh などで使用
w \sim \mathcal{N}\left(0, \, \sigma^2\right)
, \quad
\sigma = \sqrt{\frac{2}{n_{\text{in}} + n_{\text{out}}}} \;\text{(Xavier)}
, \quad
\sigma = \sqrt{\frac{1}{n_{\text{in}}}} \;\text{(LeCun)}
-
Kaiming/He
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/He_Delving_Deep_into_2015_CVPR_paper.pdf
ReLU系 などで使用
w \sim \mathcal{N}\left(0, \, \sigma^2\right)
, \quad
\sigma = \sqrt{\frac{2}{n_{\text{in}}}}
$n_{\text{in}}$: 入力側ノード数
$n_{\text{out}}$: 出力側ノード数
⑶ 深層モデルのための正則化
ⅰ. パラメータノルムペナルティー
キーワード:L1正則化、スパース表現、L2正則化、weight decay
■ L1 and L2 regularization
損失関数に重みパラメータのペナルティ項を追加することで、モデルの複雑さを制御し過学習を抑制する正則化手法
-
解決できること
- 過学習(Overfitting)の抑制
- モデルの汎化性能向上
- 特徴選択(L1)とスムージング(L2)
- 重みの爆発的増加の防止
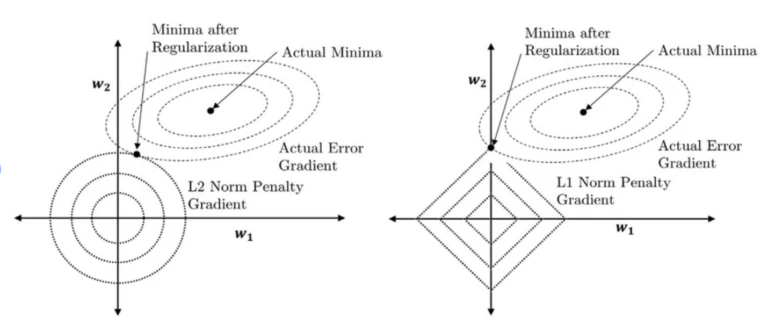
■ weight decay
学習時におけるパラメータ更新の際に、L2ノルムペナルティを加えることで、重みパラメータが大きくなりすぎるのを抑え、複雑すぎないモデルとなり、本質的な特徴だけを学習するようになる。
-
解決できること
- 過学習(Overfitting)の抑制
- 重みの爆発的増大の防止
- モデルの汎化性能向上
- シンプルで効果的な正則化
\begin{array}{ll}
\text{損失関数の拡張} & \mathcal{L}_{\text{total}} = \mathcal{L}_{\text{data}} + \cfrac{\lambda}{2} \|\mathbf{W}\|^2 \\[4mm]
\text{勾配計算}
& \cfrac{\partial \mathcal{L}_{\text{total}}}{\partial \mathbf{W}} = \cfrac{\partial \mathcal{L}_{\text{data}}}{\partial \mathbf{W}} + \lambda \mathbf{W}
\end{array}
ⅱ. 確率的削除
キーワード:ドロップアウト、ドロップコネクト
■ Dropout
https://jmlr.org/papers/v15/srivastava14a.html
学習時にランダムにニューロンを無効化(ドロップ)することで、ニューロン間の共適応を防ぎ汎化性能を向上させる正則化手法
-
解決できること
- 過学習(Overfitting)の抑制
- ニューロン間の共適応(Co-adaptation)の防止
- アンサンブル効果による汎化性能向上
- 特定のニューロンへの過度な依存の回避
\begin{aligned}
&\mathbf{h}^{(pre)} = \text{ReLU}(\mathbf{W}_1 \mathbf{x} + \mathbf{b}_1) \\[4mm]
&\mathbf{h} = \text{Dropout}(\mathbf{h}^{(pre)}) \\[4mm]
&\mathbf{y} = f(\mathbf{W}_2 \mathbf{h} + \mathbf{b}_2)
\end{aligned}
- 計算フロー
- 初期設定 ドロップアウト率 $p$ を設定
- サンプリング ドロップアウトしない確率 $q$ の二項分布に従う乱数でサンプリング
- 学習 $r_j^{(l)}$(0 or 1)を インプットベクトル $y_j^{(l)}$ にかけてマスキング
- 推論 推論時はドロップアウトをしないが、学習と比べて大きくなりすぎないように $q$ をかける
- 勾配計算 学習時の勾配計算は、$r_j^{(l)}=1$ の場合のみ計算
\begin{array}{ll}
\text{サンプリング} & \text{ドロップアウト確率 } p \\[2mm]
&\text{ドロップアウトしない確率 } q = 1-p \\[2mm]
& r_j^{(l)} \sim \mathrm{Bernoulli}(q) \\[8mm]
\text{マスキング}
& \tilde{y}^{(l)}_j = r_j^{(l)} \cdot y_j^{(l)} \\[8mm]
\text{全結合}
& z_i^{(l+1)} = {\bf{w}}_i^{(l+1)} \cdot \widetilde{\bf{y}}^{(l)} + b_i^{(l+1)} \\[8mm]
\text{活性化出力}
& y_i^{(l+1)} = f(z_i^{(l+1)}) \\[8mm]
\text{推論}
& W_{test}^{(l)}=qW^{(l)} \\[8mm]
\text{勾配計算}
& \cfrac{\partial \mathcal{L}}{\partial y_j^{(l)}}
= r_j^{(l)} \cdot \cfrac{\partial \mathcal{L}}{\partial \tilde{y}_j^{(l)}}
\end{array}
-
メモ
- CNNの入力である画像は隣接画素に相関があるので、ランダムにドロップアウトしたとしてもその周りのピクセルで補間できてしまうため、正則化の効果が限定的となる。そのため、ドロップアウトは全結合層に入れる。

■ DropConnect
ニューロンではなく重み(接続)をランダムにドロップする正則化手法で、Dropoutの変種として重み行列に直接マスクを適用する
-
解決できること
- 過学習(Overfitting)の抑制
- 重み間の共適応の防止
- Dropoutより細粒度な正則化
- モデルの冗長性の削減
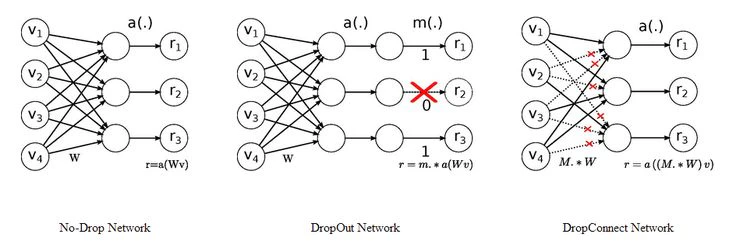
ⅲ. 陰的正則化
キーワード:早期終了、バッチサイズ、学習率の調整
■ Early Stopping
検証データの性能が悪化し始めた時点で学習を停止させる手法で、過学習を防ぎ最適な汎化性能を持つモデルを取得する
-
解決できること
- 過学習(Overfitting)の防止
- 最適な学習時期の自動決定
- 無駄な計算時間の削減
- モデルの汎化性能の最大化
- 計算フロー
- 各エポック後に検証データで性能評価
- 検証性能が改善したらモデルを保存
- 改善が止まったらカウンタを増加
- Patience回数連続で改善なし→学習停止
- 最良の検証性能を持つモデルを最終モデルとする

⑷ 畳み込みニューラルネットワーク
ⅰ. 畳み込みニューラルネットワーク
キーワード:基本的な畳み込み演算、単純型細胞と複雑型細胞、受容野(receptive field)、特徴マップ、フィルタ、カーネル、パディング、ストライド、im2col、チャネル、特別な畳み込み、point-wise畳み込み(1x1畳み込み)、depth-wise畳み込み、グループ化畳み込み、アップサンプリングと逆畳み込み、プーリング、Max pooling、Lp pooling、Global Average Pooling
■ Convolutional Neural Network
- 計算フロー
- Convolution 入力 $X$ にフィルター $W$ を適用し、特徴マップ $Y$ を抽出
- ReLU 活性化関数により、特徴マップ行列 $Y$ を活性化
- Max Pooling 各領域ごとに最大値を抽出し特徴マップ $X$ を出力 $Y$ へ圧縮
- …1~3を繰り返す
- Flatten 特徴マップ $X$ を全結合層へ入力できるようにベクトル $x_\mathrm{flat}$ へ変換
- Fully Connected $x_\mathrm{flat}$ を用いて重み $W$・バイアス $b$ で線形結合
- 出力層 最終的な予測 $\hat{y}$ を計算
- 学習 損失関数の勾配を利用した誤差逆伝播と更新式でパラメータを最適化
-
メモ
- 人間の神経細胞の単純型細胞と複雑型細胞を模したアプローチ方法
- 畳み込み層:画像の特徴(濃淡のパターン等)を検出する単純型細胞型
- プーリング層:物体の一つが変動しても同一の物体とみなす複雑型細胞型
- 人間の神経細胞の単純型細胞と複雑型細胞を模したアプローチ方法

■ Convolution(畳み込み演算)
入力データに対してフィルタ(カーネル)をスライドさせながら局所的な特徴を抽出する演算で、CNNの中核となる操作
-
解決できること
- 画像の局所的パターン(エッジ、テクスチャ等)の検出
- パラメータ数の大幅削減(重み共有)
- 平行移動不変性(Translation Invariance)の獲得
- 空間的階層構造の学習
\begin{array}{lll}
F(x, y) = \displaystyle\sum_{i} \sum_{j} I(x+i, y+j) * K(i, j)
\end{array}
■ Stride and Padding
畳み込み演算における空間サイズの制御パラメータで、Strideはフィルタの移動幅、Paddingは入力の周囲への値追加を行う
-
解決できること
- 出力特徴マップのサイズ制御
- ダウンサンプリング(Stride)
- 境界情報の保持(Padding)
- 計算量とメモリ使用量の調整
\begin{array}{lll}
H_{out} = \cfrac{H_{in} + 2P - F}{S} + 1\\[4mm]
W_{out} = \cfrac{W_{in} + 2P - F}{S} + 1
\end{array}
■ 特殊な畳み込み演算
| 演算タイプ | 主な用途 | 計算量 | 受容野 | 代表的モデル |
|---|---|---|---|---|
| Standard Conv | 基本的特徴抽出 | 高 | 固定 | LeNet, VGG, ResNet |
| Pointwise Conv | チャネル統合 | 低 | なし | MobileNet, Inception |
| Depthwise Conv | 空間フィルタリング | 極低 | 固定 | MobileNet, Xception |
| Grouped Conv | 効率的特徴抽出 | 中 | 固定 | AlexNet, ResNeXt |
| Dilated Conv | 広域文脈取得 | 中 | 可変大 | DeepLab, WaveNet |
| Deformable Conv | 適応的サンプリング | 高 | 適応的 | DCN, DCNv2 |
| Transposed Conv | アップサンプリング | 高 | 逆方向 | U-Net, GAN, FCN |
■ Pointwise Convolution (1×1畳み込み)
チャネル方向の線形結合を行う演算で、チャネル数の調整や次元削減に使用
-
解決できること
- チャネル間の情報統合
- 計算コストを抑えた次元削減・拡張
- 非線形性の追加(活性化関数と組み合わせ)
- MobileNetなどの効率的アーキテクチャの実現
$$F_c(x, y) = \displaystyle\sum_{c'=0}^{C-1} I_{c'}(x, y) \cdot W_{c,c'}$$
■ Depthwise Convolution (深さ方向畳み込み)
各チャネルを独立に空間方向の畳み込みを行う演算
-
解決できること
- 空間フィルタリングとチャネルミキシングの分離
- パラメータ数と計算量の大幅削減
- MobileNetやEfficientNetでの軽量化
- Depthwise Separable Convolutionの構成要素
$$F_c(x, y) = \displaystyle\sum_{i=0}^{h-1} \sum_{j=0}^{w-1} I_c(x+i, y+j) \cdot K_c(i, j)$$
■ Grouped Convolution (グループ畳み込み)
入力チャネルを複数のグループに分割し、各グループ内で独立に畳み込みを行う演算
-
解決できること
- 計算量とメモリ使用量の削減
- モデルの並列化効率の向上
- 特徴の多様性確保(AlexNet、ResNeXt等で使用)
- チャネル間の疎な接続による正則化効果
$$F(x, y) = \displaystyle\sum_{g=1}^{G} \sum_{c=1}^{C_g} I_g(x, y) * K_g \quad (G: \text{グループ数})$$
■ Dilated Convolution (拡張畳み込み)
フィルタの要素間に空白を挿入して受容野を拡大する演算
-
解決できること
- パラメータ増加なしでの受容野拡大
- 解像度を保ったまま広範囲の文脈情報取得
- セグメンテーションタスクでの精度向上(DeepLab等)
- プーリング層の削減による情報損失の抑制
$$F(x, y) = \displaystyle\sum_{i} \displaystyle\sum_{j} I(x+r \cdot i, y+r \cdot j) \cdot K(i, j) \quad (r: \text{dilation rate})$$
■ Deformable Convolution (変形可能畳み込み)
サンプリング位置を学習可能なオフセットで動的に調整する演算
-
解決できること
- 幾何学的変形への適応性向上
- 不規則な形状やスケール変化への対応
- 物体検出・セグメンテーションの精度向上
- 固定的なグリッド構造の制約からの解放
$$F(x, y) = \displaystyle\sum_{i} \displaystyle\sum_{j} I(x+i+\Delta x_{i,j}, y+j+\Delta y_{i,j}) \cdot K(i, j)$$
■ Transposed Convolution (転置畳み込み)
畳み込みの逆操作として空間解像度を拡大する演算(デコンボリューションとも呼ばれる)
-
解決できること
- 画像のアップサンプリング(解像度復元)
- セグメンテーションのデコーダ部での特徴マップ拡大
- GANの生成器での画像生成
- オートエンコーダの再構成処理
$$F(x, y) = \displaystyle\sum_{i} \displaystyle\sum_{j} I\left(\left\lfloor\frac{x-i}{s}\right\rfloor, \left\lfloor\frac{y-j}{s}\right\rfloor\right) \cdot K(i, j) \quad (s: \text{stride})$$
■ Depthwise Separable Convolution と計算量
\begin{array}{lll}
\text{Conv.}
&K^2C_{in}C_{out}HW\\[4mm]
\text{Depthwise Conv.}
&K^2C_{out}HW\\[4mm]
\text{Pointwise Conv.}
&C_{in}C_{out}HW\\[4mm]
\text{DepthwiseSeparable Conv.}
&K^2C_{in}HW + C_{in}C_{out}HW\\[4mm]
\text{比較}
&
\cfrac{K^2C_{out}HW}{K^2C_{in}C_{out}HW} + \cfrac{C_{in}C_{out}HW}{K^2C_{in}C_{out}HW} = \cfrac{1}{C_{in}} + \cfrac{1}{K^2}
\end{array}
■ Pooling(プーリング演算)
\scriptsize \begin{bmatrix}
1 & 3 & 2 & 1 \\
2 & 9 & 1 & 1 \\
1 & 3 & 2 & 3 \\
5 & 6 & 1 & 2 \\
\end{bmatrix}
\underrightarrow{\text{max pooling}}
\begin{bmatrix}
9 & 2 \\
6 & 3
\end{bmatrix}
\qquad\qquad
\scriptsize \begin{bmatrix}
1 & 3 & 2 & 1 \\
2 & 9 & 1 & 1 \\
1 & 3 & 2 & 3 \\
5 & 6 & 1 & 2 \\
\end{bmatrix}
\underrightarrow{\text{average pooling}}
\begin{bmatrix}
3.75 & 1.25 \\
3.75 & 2
\end{bmatrix}
| 演算タイプ | 特徴の保持 | 計算量 | ロバスト性 | 用途 |
|---|---|---|---|---|
| Max Pooling | 顕著な特徴 | 低 | 高 | 一般的なCNN、物体検出 |
| Average Pooling | 全体的特徴 | 低 | 中 | スムーズな特徴、分類 |
| Global Average Pooling | チャネル統計 | 極低 | 中 | 分類の最終層、CAM |
| Global Max Pooling | 最大活性化 | 極低 | 高 | テクスチャ認識 |
| Lp Pooling | 調整可能 | 中 | 中〜高 | 柔軟な特徴抽出 |
| Spatial Pyramid Pooling | マルチスケール | 中 | 高 | 物体検出、任意サイズ入力 |
■ Max Pooling (最大値プーリング)
局所領域内の最大値を選択することで特徴マップをダウンサンプリングする演算
-
解決できること
- 空間次元の削減による計算量の削減
- 位置ずれに対するロバスト性の向上
- 最も顕著な特徴の抽出
- 過学習の抑制(小さな変動の無視)
$$F(x, y) = \max_{i \in [0, h)} \max_{j \in [0, w)} I(x \cdot s + i, y \cdot s + j)$$
$$\text{where } s: \text{stride}, h \times w: \text{pooling window size}$$
■ Average Pooling (平均値プーリング)
局所領域内の平均値を計算することで特徴マップをダウンサンプリングする演算
-
解決できること
- より滑らかな特徴表現の獲得
- 外れ値の影響を軽減
- 背景情報を含む全体的な特徴の保持
- Max Poolingより穏やかなダウンサンプリング
$$F(x, y) = \frac{1}{h \cdot w} \sum_{i=0}^{h-1} \sum_{j=0}^{w-1} I(x \cdot s + i, y \cdot s + j)$$
$$\text{where } s: \text{stride}, h \times w: \text{pooling window size}$$
■ Global Average Pooling (GAP / 全体平均プーリング)
特徴マップ全体の平均値を計算し、各チャネルを1つの値に集約する演算
-
解決できること
- 全結合層の代替によるパラメータ数の大幅削減
- 過学習の抑制効果
- 入力サイズへの依存性の排除
- クラス活性化マップ(CAM)の生成
$$F_c = \frac{1}{H \cdot W} \sum_{x=0}^{H-1} \sum_{y=0}^{W-1} I_c(x, y)$$
$$\text{where } c: \text{channel index}, H \times W: \text{entire feature map size}$$
■ Global Max Pooling (GMP / 全体最大値プーリング)
特徴マップ全体の最大値を選択し、各チャネルを1つの値に集約する演算
-
解決できること
- 最も顕著な特徴の抽出
- スパースな特徴表現の獲得
- 位置情報の完全な抽象化
- テクスチャ認識タスクでの有効性
$$F_c = \max_{x \in [0, H)} \max_{y \in [0, W)} I_c(x, y)$$
$$\text{where } c: \text{channel index}, H \times W: \text{entire feature map size}$$
■ Lp Pooling (Lp ノルムプーリング)
局所領域内のLpノルムを計算することで特徴マップをダウンサンプリングする演算
-
解決できること
- Max Pooling (p→∞) と Average Pooling (p=1) の一般化
- pの値による特徴抽出の柔軟な調整
- より表現力の高いプーリング操作
- タスクに応じた最適なpの学習可能性
$$F(x, y) = \left( \frac{1}{h \cdot w} \sum_{i=0}^{h-1} \sum_{j=0}^{w-1} |I(x \cdot s + i, y \cdot s + j)|^p \right)^{1/p}$$
$$\text{where } p \geq 1, \quad p=1: \text{Average Pooling}, \quad p \to \infty: \text{Max Pooling}$$
■ Spatial Pyramid Pooling (SPP / 空間ピラミッドプーリング)
異なるスケールで複数のプーリングを行い、固定長の特徴ベクトルを生成する演算
-
解決できること
- 任意サイズの入力画像への対応
- マルチスケール特徴の統合
- 物体検出での領域提案処理の効率化
- 空間的な階層構造の表現
F = \text{Concat}(\text{Pool}_{n_1 \times n_1}, \text{Pool}_{n_2 \times n_2}, \ldots, \text{Pool}_{n_k \times n_k})
$$\text{各レベル } n_i \text{ で特徴マップを } n_i \times n_i \text{ グリッドに分割してプーリング}$$
⑸ リカレントニューラルネットワーク
ⅰ. リカレントニューラルネットワーク
キーワード:順伝播の計算、逆伝搬の計算(Back Propagation Through Time; BPTT)、双方向RNN
■ RNN (基本RNN)
前の時刻の隠れ状態を現在の入力と組み合わせて次の状態を計算する、最も基本的な再帰的ニューラルネットワーク
-
解決できること
- 可変長の系列データの処理
- 時系列パターンの学習
- 文脈情報の保持
- 自然言語処理や音声認識への応用
-
メモ
- 勾配消失・爆発問題により長期依存関係の学習が困難
$$h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b_h)$$
$$y_t = W_{hy} h_t + b_y$$
$$\text{where } h_t: \text{hidden state}, x_t: \text{input}, y_t: \text{output}$$

■ Bidirectional RNN (BiRNN / 双方向RNN)
順方向と逆方向の両方から系列を処理し、過去と未来の文脈を統合するRNN
-
解決できること
- 過去と未来両方の文脈情報の活用
- 系列全体の情報に基づく予測
- 自然言語処理での文脈理解の向上
- 音声認識や機械翻訳の精度向上
\overrightarrow{h}_t = f(\overrightarrow{W} x_t + \overrightarrow{V} \overrightarrow{h}_{t-1} + \overrightarrow{b}) \quad \text{(forward direction)}
\overleftarrow{h}_t = f(\overleftarrow{W} x_t + \overleftarrow{V} \overleftarrow{h}_{t+1} + \overleftarrow{b}) \quad \text{(backward direction)}
h_t = [\overrightarrow{h}_t; \overleftarrow{h}_t] \quad \text{(concatenation)}
y_t = g(W_y h_t + b_y) \quad \text{(output)}
\begin{array}{ll}
\text{RNN}
&H_t^{(l)} = \phi_l(H_t^{(l-1)} W_{\textrm{xh}}^{(l)} + H_{t-1}^{(l)} W_{\textrm{hh}}^{(l)} + b_\textrm{h}^{(l)}),
\\[2mm]
&O_t = H_t^{(L)} W_{hq} + b_q \\[4mm]
\text{BiRNN}
&\overrightarrow{H}_t = \phi(X_t W_{xh}^{(f)} + \overrightarrow{H}_{t-1} W_{hh}^{(f)} + b_h^{(f)})
\\[2mm]
&\overleftarrow{H}_t = \phi(X_t W_{xh}^{(b)} + \overleftarrow{H}_{t+1} W_{hh}^{(b)} + b_h^{(b)})
\\[2mm]
&O_t = H_t W_{hq} + b_q
\end{array}


ⅱ. ゲート機構
キーワード:勾配消失、忘却ゲート、入力ゲート、出力ゲート、LSTM(長期記憶と短期記憶)、GRU、リセットゲート、メモリーセル
■ LSTM (Long Short-Term Memory)
ゲート機構により長期依存関係を学習可能にした改良型RNN
-
解決できること
- 長期依存関係の学習
- 勾配消失問題の大幅な軽減
- 重要な情報の選択的保持
- 系列データの長期記憶
\begin{array}{lll}
\text{LSTMセル}
&i_t = \sigma(W_{xi} x_t + W_{hi} h_{t-1} + b_i)\\[2mm]
&f_t = \sigma(W_{xf} x_t + W_{hf} h_{t-1} + b_f)\\[2mm]
&o_t = \sigma(W_{xo} x_t + W_{ho} h_{t-1} + b_o)\\[2mm]
&\tilde{c}_t = \tanh(W_{xc} x_t + W_{hc} h_{t-1} + b_c) \\[2mm]
&c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t \\[2mm]
&h_t = o_t \odot \tanh(c_t)
\end{array}
Forget Gate: 過去の情報をどれだけ忘れるか
Input Gate: 新しい情報をどれだけ取り込むか
Output Gate: 隠れ状態をどれだけ出力するか
Cell State: 長期記憶を保持

■ GRU (Gated Recurrent Unit)
LSTMを簡略化し、計算効率を向上させたゲート付きRNN
-
解決できること
- LSTMと同等の性能をより少ないパラメータで実現
- 計算コストの削減
- 学習速度の向上
- 中規模データでの効率的な学習
\begin{array}{lll}
\text{GRUセル}
&z_t = \sigma(W_{xz} x_t + W_{hz} h_{t-1} + b_z)\\[2mm]
&r_t = \sigma(W_{xr} x_t + W_{hr} h_{t-1} + b_r)\\[2mm]
&\tilde{h}_t = \tanh\left(W_{xh} x_t + W_{hh}\left(r_t \odot h_{t-1}\right) + b_h\right)\\[2mm]
&h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t
\end{array}
Update Gate: 過去の情報と新しい情報の混合比率
Reset Gate: 過去の情報をどれだけリセットするか
セル状態と隠れ状態が統合されている

ⅲ. 系列変換
キーワード:エンコーダ・デコーダ、sequence-to-sequence(seq2seq)、アテンション(注意)機構
■ Encoder-Decoder (エンコーダ・デコーダ)
入力系列を固定長ベクトルに圧縮(エンコード)し、それを別の系列に展開(デコード)するアーキテクチャ
-
解決できること
- 可変長入力から可変長出力への変換
- 機械翻訳、要約生成、対話システム
- 系列間の変換タスク全般
- 入力と出力の長さが異なる問題への対応
-
メモ
- 入力系列全体を固定長ベクトルに圧縮するため、長い系列で情報損失が発生する
- 計算フロー
- エンコーダ 入力 $x_t$ から隠れ表現 $h_t$ を生成する。全系列の隠れ表現 $h_1,\ldots,h_T$ から特徴ベクトル(コンテキスト)$c$ を抽出
- デコーダ 前時刻の出力 $y_{t^\prime-1}$(教師強制)と特徴ベクトル $c$、前時刻のデコーダ隠れ状態 $s_{t^\prime-1}$ を入力し、 現時刻の隠れ状態 $s_{t^\prime}$ を生成
- 出力層 デコーダの隠れ状態 $s_{t^\prime}$ から最終的な予測 $\hat{y}_{t^\prime}$ を計算
- 学習 損失関数の勾配を利用した誤差逆伝播と更新式でパラメータを最適化
\begin{array}{lll}
\text{Encoder}
&h_t = f(x_t, h_{t-1}), \quad c = q(h_1, \ldots, h_T)\\[4mm]
\text{Decoder}
&s_{t^\prime} = g(y_{t^\prime-1}, c, s_{t^\prime-1}).
\end{array}



■ Additive Attention (Bahdanau Attention)
クエリとキーを結合してから非線形変換を行い、アテンションスコアを計算する方式
-
解決できること
- 機械翻訳での動的なアライメント学習
- 長い系列での情報損失の軽減
- エンコーダの全状態を活用した文脈理解
- 注意重みの可視化による解釈性向上
- 計算フロー
- Attention Score スコア関数で Attention Score を計算
- Attention Weight ソフトマックスで Attention Weight を生成
- Weighted Sum Attention Weight で重み付き和(コンテキストベクトル)を生成
- Output コンテキストベクトルとデコーダの状態からアウトプットを生成
\begin{aligned}
&\text{Score Function} \qquad
&& \text{score}(h_j^{enc}, s_{t-1}^{dec}) = v^T \tanh(W_h h_j^{enc} + W_s s_{t-1}^{dec}) \\[8mm]
&\text{Attention Score} \qquad
&& e_{j,t} = \text{score}(h_j^{enc}, s_{t-1}^{dec}) \\[8mm]
&\text{Attention Weight} \qquad
&& \alpha_{j,t} = \frac{\exp(e_{j,t})}{\sum_{k=1}^{T} \exp(e_{k,t})} \\[8mm]
&\text{Context Vector} \qquad
&& c_t = \sum_{j=1}^{T} \alpha_{j,t} \cdot h_j^{enc} \\[8mm]
&\text{Decoder Update} \qquad
&& s_t^{dec} = \text{RNN}(y_{t-1}, s_{t-1}^{dec}, c_t) \\[8mm]
&\text{Output} \qquad
&& y_t = f(s_t^{dec}, c_t, y_{t-1})
\end{aligned}
- $h_j^{enc}$: エンコーダの隠れ状態(キー・バリュー)
- $s_{t-1}^{dec}$: 前の時刻のデコーダ状態(クエリ)
- $c_t$: コンテキストベクトル(重要情報の集約)
- $v \in \mathbb{R}^{d_a}$, $W_h \in \mathbb{R}^{d_a \times d_h}$, $W_s \in \mathbb{R}^{d_a \times d_s}$

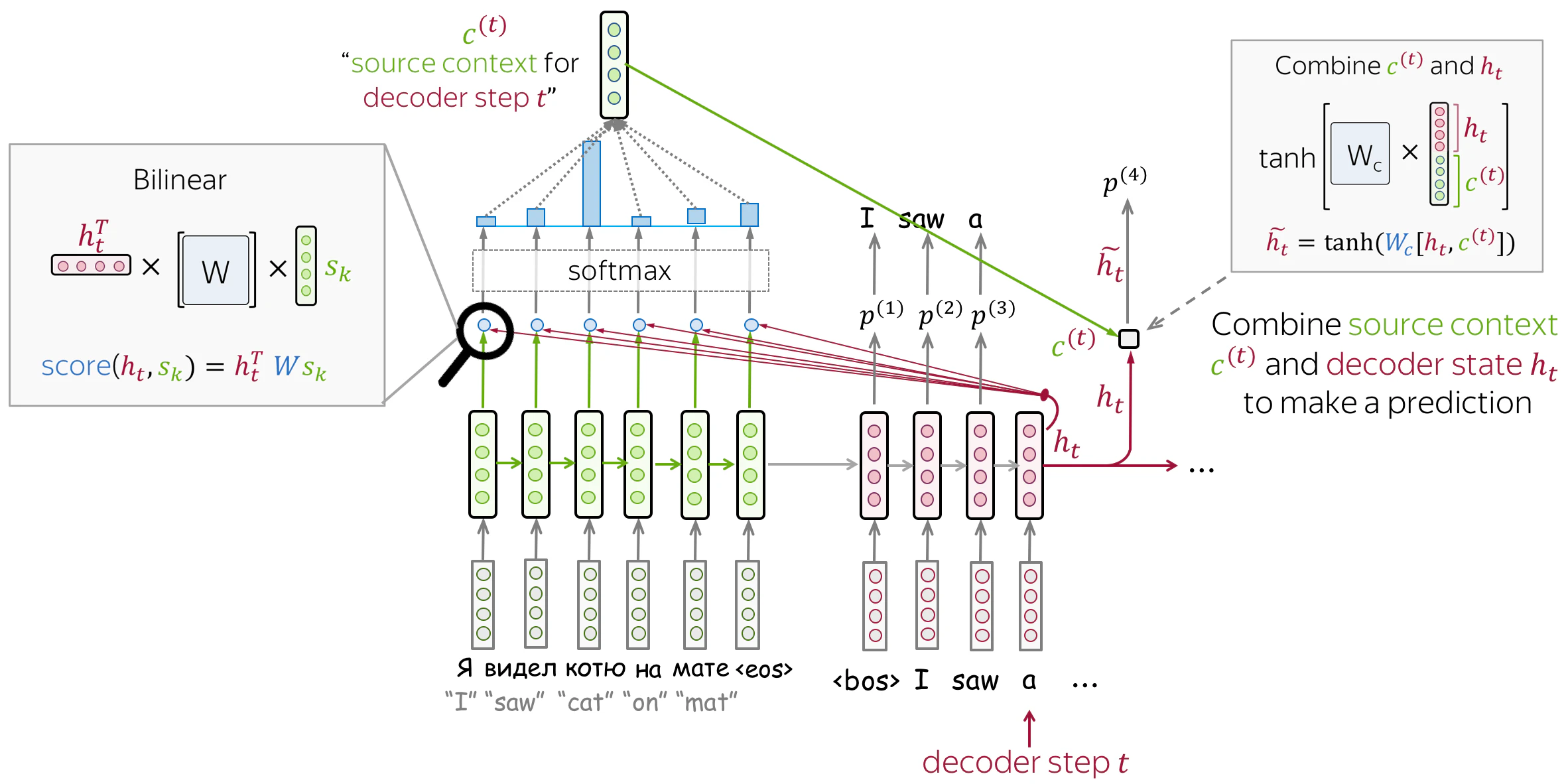
■ Multiplicative Attention (Luong Attention)
クエリとキーの内積を重み行列で変換して注意スコアを計算する方式
-
解決できること
- Additive Attentionより計算効率が高い
- シンプルな構造での効果的な注意機構
- メモリ使用量の削減
- 高速な推論処理
\begin{aligned}
&\text{Decoder Update} \qquad
&& s_t^{dec} = \text{RNN}(y_{t-1}, s_{t-1}^{dec}) \\[8mm]
&\text{Score Function} \qquad
&& \text{score}(h_j^{enc}, s_t^{dec}) = h_j^{enc \top} s_t^{dec} \\[8mm]
&\text{Attention Score} \qquad
&& e_{j,t} = \text{score}(h_j^{enc}, s_t^{dec}) \\[8mm]
&\text{Attention Weight} \qquad
&& \alpha_{j,t} = \frac{\exp(e_{j,t})}{\sum_{k=1}^{T} \exp(e_{k,t})} \\[8mm]
&\text{Context Vector} \qquad
&& c_t = \sum_{j=1}^{T} \alpha_{j,t} \cdot h_j^{enc} \\[8mm]
&\text{Attention Vector} \qquad
&& \tilde{s}_t = \tanh(W_c[s_t^{dec}; c_t]) \\[8mm]
&\text{Output} \qquad
&& y_t = \text{softmax}(W_o \tilde{s}_t)
\end{aligned}
- $h_j^{enc}$: エンコーダの隠れ状態(キー・バリュー)
- $s_t^{dec}$: 現在の時刻のデコーダ状態(クエリ)
- $c_t$: コンテキストベクトル
- $\tilde{s}_t$: アテンションベクトル(最終的な特徴表現)
- スコア関数
\begin{aligned}
&\text{Dot-Product} \qquad
&& \text{score}(h^{(s)}_i, h^{(t)}_j) = h^{(s)}_i \cdot h^{(t)}_j \\[8mm]
&\text{Bilinear} \qquad
&& \text{score}(h^{(s)}_i, h^{(t)}_j) = h^{(s)}_i W h^{(t)}_j \\[8mm]
&\text{Multi-Layer Perceptron} \qquad
&& \text{score}(h^{(s)}_i, h^{(t)}_j) = v^T \tanh(W[h^{(s)}_i; h^{(t)}_j]) \\[4mm]
&&& = v^T \tanh(W_1 h^{(s)}_i + W_2 h^{(t)}_j)
\end{aligned}
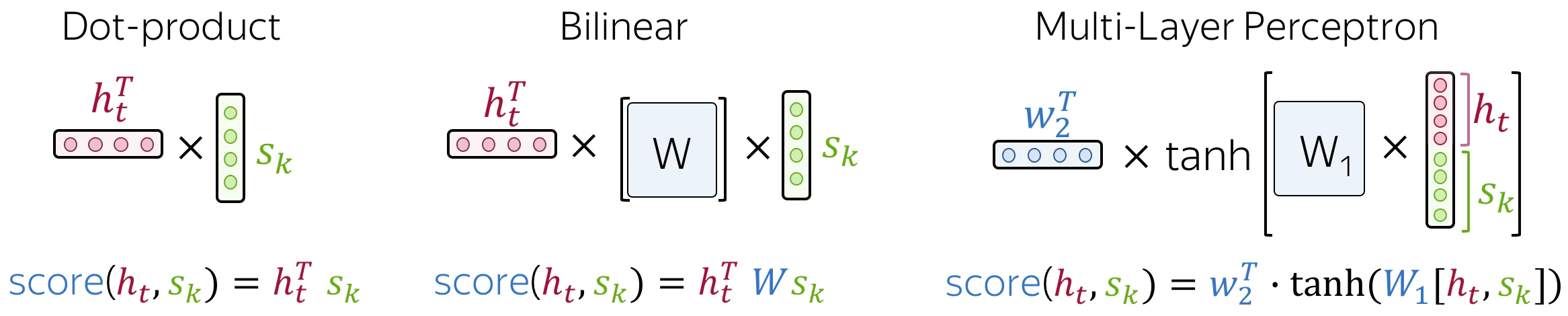
⑹ Transformer
ⅰ. Transformer
キーワード:Self-Attention、Scaled Dot-Product Attention、Source Target Attention、Masked Attention、Multi-Head Attention、Positional Encoding
■ Transformer
Attention機構のみで構成された、系列データ処理のための革新的なニューラルネットワークアーキテクチャ
-
解決できること
- RNN/LSTMの逐次処理の制約を解消し並列処理を実現
- 長距離依存関係の効率的な学習
- 勾配消失問題の回避
- 系列長に対してスケーラブルな処理
- Self-Attentionによる入力全体の文脈理解
- Encoder-Decoder構造による柔軟な系列変換
- 位置エンコーディングによる順序情報の保持

■ Scaled Dot-Product Attention
スケーリング因子を導入し、勾配の安定性を向上させたアテンション
-
解決できること
- 大きな次元でのsoftmaxの飽和問題の軽減
- 勾配の安定化による学習効率の向上
- 並列計算の効率化
\begin{aligned}
&\text{Query, Key, Value} \quad
&& Q \in \mathbb{R}^{n \times d_k}, \quad K \in \mathbb{R}^{m \times d_k}, \quad V \in \mathbb{R}^{m \times d_v} \\[4mm]
&\text{Scaled Dot-Product Attention} \quad
&& Z = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
\end{aligned}
- $Q$: クエリ行列(何を探すか)
- $K$: キー行列(何があるか)
- $V$: バリュー行列(実際の内容)
- $d_k$: キーの次元(スケーリング因子として使用)
- $n$: クエリの数、$m$: キー・バリューの数
-
メモ
- スケーリングの理由 $d_k$が大きいとドット積の分散が大きくなり、softmaxが飽和領域に入るのを防ぐ

■ Source-Target Attention
エンコーダの出力とデコーダの状態間で計算されるAttention
-
解決できること
- エンコーダ-デコーダ間の情報伝達
- 翻訳時のソース文への選択的注目
- マルチモーダル学習(画像-テキストなど)
- 条件付き生成タスク
\begin{aligned}
&\text{Inputs} \qquad
&& X_{dec} \in \mathbb{R}^{n \times d_{model}}, \quad X_{enc} \in \mathbb{R}^{m \times d_{model}} \\[4mm]
&\text{Query from Decoder} \qquad
&& Q_{dec} = X_{dec}W^Q \\[4mm]
&\text{Key, Value from Encoder} \qquad
&& K_{enc} = X_{enc}W^K, \quad V_{enc} = X_{enc}W^V \\[4mm]
&\text{Cross-Attention} \qquad
&& Z = \text{softmax}\left(\frac{Q_{dec}K_{enc}^T}{\sqrt{d_k}}\right)V_{enc}
\end{aligned}
■ Self-Attention
同一系列内の要素間の関係性を学習するAttention
-
解決できること
- 系列内の長距離依存関係の捕捉
- 文脈を考慮した単語表現の学習
- 並列処理による高速化
- 高い解釈可能性
- 計算量が小さい
\begin{aligned}
&\text{Input} \qquad
&& X \in \mathbb{R}^{n \times d_{model}} \\[4mm]
&\text{Query, Key, Value} \qquad
&& Q = XW^Q, \quad K = XW^K, \quad V = XW^V \\[4mm]
&\text{Self-Attention} \qquad
&& Z = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
\end{aligned}


■ Multi-Head Attention
複数のアテンションヘッドを並列に計算し、異なる表現部分空間からの情報を統合
-
解決できること
- 異なる位置・異なる表現空間の情報の同時捕捉
- モデルの表現力の向上
- 多様な依存関係の学習
\begin{aligned}
&\text{Multi-Head Attention} \qquad
&& \text{MHA}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O \\[8mm]
&\text{Each Head} \qquad
&& \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \\[8mm]
&\text{Scaled Dot-Product} \qquad
&& \text{head}_i = \text{softmax}\left(\frac{QW_i^Q(KW_i^K)^T}{\sqrt{d_k}}\right)VW_i^V \\[8mm]
&\text{Projection Matrices} \qquad
&& W_i^Q \in \mathbb{R}^{d_{model} \times d_k}, \quad W_i^K \in \mathbb{R}^{d_{model} \times d_k} \\[4mm]
&&& W_i^V \in \mathbb{R}^{d_{model} \times d_v}, \quad W^O \in \mathbb{R}^{hd_v \times d_{model}}
\end{aligned}
W_i^Q, W_i^K \in \mathbb{R}^{d_{model} \times d_k}, W_i^V \in \mathbb{R}^{d_{model} \times d_v}, W^O \in \mathbb{R}^{hd_v \times d_{model}}
■ Masked Attention
未来の情報を参照できないようマスクをかけたアテンション
-
解決できること
- 自己回帰的な生成タスク(GPTなど)
- デコーダでの因果性の保持
- 学習時と推論時の一貫性
- 系列生成タスク全般
\begin{aligned}
&\text{Score with Mask} \qquad
&& S = \frac{QK^T}{\sqrt{d_k}} + M \\[4mm]
&\text{Masked Attention} \qquad
&& Z = \text{softmax}(S)V = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V \\[4mm]
&\text{Mask Matrix} \qquad
&& M_{ij} = \begin{cases}
0 & \text{if } j \leq i \\
-\infty & \text{if } j > i
\end{cases}
\end{aligned}
■ Positional Encoding
時系列を考慮するために、入力の埋め込み表現に「位置情報」を埋め込む
-
解決できること
- 系列内のトークンの順序情報の表現
- Self-Attentionの位置不変性の解決
- 相対的・絶対的な位置関係の学習
- 任意長の系列への対応
\begin{aligned}
&\displaystyle P(\text{pos},2d) = \sin \left( \frac{ \text{pos} }{ 10000^{2d/d_{model}} }\right)\\[4mm]
&\displaystyle P(\text{pos},2d+1) = \cos \left( \frac{ \text{pos} }{ 10000^{2d/d_{model}} }\right)
\end{aligned}
-
メモ
- 三角関数の理由 任意の長さの入力に対しても値が-1~1の範囲に収まるため(長文は加える値が大きくなる)
- 10000で割る理由 10000で割ることで三角関数の周期が大きくなり繰り返しを防ぐ
- 2つの関数 周期を大きくしたことで、小さい入力の差が反映されにくくなるため、奇数と偶数で別の関数を使う
■ Input (Output) Embedding
トークン(単語やサブワード)を連続的なベクトル空間に変換する層
-
解決できること
- 離散的なトークンの数値化
- 意味的な類似性の表現
- 次元の統一
- EncoderとDecoderの重みを共有
\text{Embedding}(token) = E_{token} \in \mathbb{R}^{d_{model}}
■ Position-wise Feed-Forward Network
位置ごとに独立に適用される2層の全結合ニューラルネットワーク
-
解決できること
- 非線形変換による表現力の向上
- 各位置の特徴の独立した処理
- Attentionで得た情報の統合と変換
- モデル容量の拡大
\rm{FFN}(x) = \max(0, xW_1+b_1)W_2+b_2
■ Add & Norm
残差接続(Residual Connection)と層正規化(Layer Normalization)を組み合わせた構造
-
解決できること
- 勾配消失問題の緩和
- 正規化による収束の促進
- 各層の出力分布の正規化
- 残差接続により入力情報を直接伝播
\text{LayerNorm}(x + \text{Sublayer}(x))
![]()
⑺ 汎化性能向上のためのテクニック
ⅰ. データ集合の拡張
キーワード:画像のデータ拡張、ノイズ付与、Random Flip・Erase・Crop・Contrast・Brightness・Rotate、RandAugment、MixUp、自然言語のデータ拡張、EDA、MixUp、音声のデータ拡張、ノイズ付与、ボリューム変更、ピッチシフト、MixUp、SpecAugment
■ Data Augmentation
- 画像データ拡張
既存の訓練データに変換を加えて人工的にデータ量を増やし、モデルの汎化性能を向上させる技術
-
解決できること
- 訓練データ不足の解消
- 過学習の抑制
- モデルのロバスト性向上
- 多様なバリエーションへの対応
| 手法 | データ種類 | 計算コスト | ラベル変更 | 主な用途 |
|---|---|---|---|---|
| 幾何変換 | 画像 | 低 | ✗ | 画像分類、物体検出 |
| Color Jitter | 画像 | 低 | ✗ | 画像分類 |
| Cutout | 画像 | 低 | ✗ | 画像分類 |
| Random Erasing | 画像 | 低 | ✗ | 画像分類、Re-ID |
| Synonym Replacement | テキスト | 低 | ✗ | テキスト分類 |
| Back Translation | テキスト | 高 | ✗ | NLP全般 |
| Mixup | 画像/テキスト | 低 | ○ | 分類タスク |
| CutMix | 画像 | 低 | ○ | 画像分類 |
| AutoAugment | 画像 | 高(探索時) | ✗ | 画像分類 |
| RandAugment | 画像 | 低 | ✗ | 画像分類 |
\begin{aligned}
&\text{Rotation} \qquad
&& I' = R(\theta) \cdot I \quad \text{where } \theta \in [-\theta_{max}, \theta_{max}] \\[8mm]
&\text{Horizontal Flip} \qquad
&& I'(x, y) = I(W - x, y) \\[8mm]
&\text{Vertical Flip} \qquad
&& I'(x, y) = I(x, H - y) \\[8mm]
&\text{Scale/Zoom} \qquad
&& I' = S(s) \cdot I \quad \text{where } s \in [s_{min}, s_{max}] \\[8mm]
&\text{Translation} \qquad
&& I'(x, y) = I(x + \Delta x, y + \Delta y) \\[8mm]
&\text{Crop} \qquad
&& I' = I[x_1:x_2, y_1:y_2] \\[8mm]
&\text{Color Jitter} \qquad
&& I' = \alpha I + \beta \quad \text{(brightness, contrast)} \\[8mm]
&\text{Gaussian Noise} \qquad
&& I' = I + \mathcal{N}(0, \sigma^2) \\[8mm]
&\text{Cutout} \qquad
&& I'(x, y) = \begin{cases}
0 & \text{if } (x, y) \in \text{mask region} \\[2mm]
I(x, y) & \text{otherwise}
\end{cases} \\[2mm]
&&& x_{\text{cutout}} = M \odot x + (1-M) \odot v \\[2mm]
&&& M: \text{マスク}、v: 0またはノイズ
\\[8mm]
&\text{Random Erasing} \qquad
&& I'(x, y) = \begin{cases}
r & \text{if } (x, y) \in \text{erasing region} \\[2mm]
I(x, y) & \text{otherwise}
\end{cases}
\end{aligned}
- $I$: 元画像、$I'$: 変換後画像
- $\theta$: 回転角度
- $W, H$: 画像の幅と高さ
- $s$: スケール係数
- $\Delta x, \Delta y$: 平行移動量
- $\alpha, \beta$: 明るさ・コントラスト調整パラメータ
- $\sigma^2$: ノイズの分散
- $r$: ランダムな値(ピクセル平均値、ランダムノイズなど)
- Cutoutは固定値(0)で埋める、Random Erasingはランダム値で埋める
■ Mixup
2枚の画像とラベルをランダム比率$\lambda$で線形合成し、新たな疑似データを作る。ラベルも同じ比率で混合する。
-
解決できること
- 決定境界を滑らかにする効果
\begin{aligned}
& \quad x_{\text{mix}} = \lambda x_i + (1-\lambda)x_j \\[2mm]
& \quad y_{\text{mix}} = \lambda y_i + (1-\lambda)y_j \\[2mm]
& \quad \lambda \sim \text{Beta}(\alpha, \alpha)
\end{aligned}
■ CutMix
1枚の画像の一部領域を、別画像から切り貼りして合成する。
\begin{aligned}
& \quad x_{\text{cm}} = M \odot x_i + (1-M) \odot x_j \\[2mm]
& \quad y_{\text{cm}} = \lambda y_i + (1-\lambda)y_j \\[2mm]
& \quad M: \text{マスク}, \; \lambda: \text{面積比}
\end{aligned}
-
メモ
- Mixupと異なり、局所的な特徴が保持される
- より自然なデータ拡張

ⅱ. 正規化
キーワード:Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization
■ Normalization
| 手法 | 平均・分散の計算範囲 | 図式表現 |
|---|---|---|
| Batch Norm | $(N, H, W)$ 方向 | 各チャネル $c$ ごとに、全サンプル・全空間位置で統計計算 |
| Layer Norm | $(C, H, W)$ 方向 | 各サンプル $n$ ごとに、全チャネル・全空間位置で統計計算 |
| Instance Norm | $(H, W)$ 方向 | 各サンプル $n$、各チャネル $c$ ごとに、空間位置のみで統計計算 |
| Group Norm | $(C/G, H, W)$ 方向 | 各サンプル $n$、各グループ $g$ ごとに統計計算 |
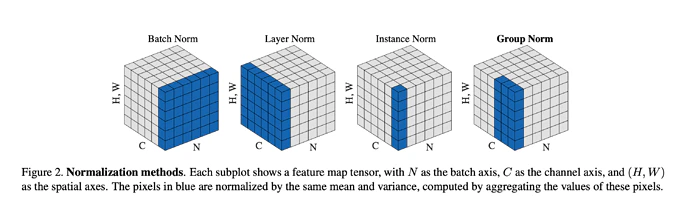
■ Batch Normalization
ミニバッチ内のデータを正規化することで学習を安定化させ、高速化する手法
-
解決できること
- 内部共変量シフト(Internal Covariate Shift)の軽減
- 学習率を大きく設定可能(高速な学習)
- 勾配消失・爆発問題の緩和
- 正則化効果による過学習の抑制
-
計算フロー
- 初期設定 学習率 $\eta$ , 微小定数 $\epsilon$ を設定
-
統計量計算
- 学習時 ミニバッチ内の複数サンプル $m$ について、同じチャンネル $c$ ごとに平均・分散を計算
- 推論時 学習時に得たバッチ平均・分散をチャンネル $c$ ごとに移動平均として蓄積
-
正規化・更新
- 学習時 各チャンネル $c$ ごとにバッチ正規化を行い、スケール・シフトパラメータ $\gamma_c$, $\beta_c$ で分布を再調整
- 推論時 推論時は各チャンネル $c$ の移動平均値・分散値を用い、1サンプル単位で正規化・再調整
- 学習 損失関数の勾配を利用した誤差逆伝播と更新式でパラメータを最適化
\begin{array}{ll}
\text{統計量計算}
&\text{学習時} & \mu_{\mathcal{B},c} = \dfrac{1}{m} \displaystyle\sum_{i=1}^{m} x_{i, c} \\[4mm]
&& \sigma_{\mathcal{B},c}^2 = \dfrac{1}{m} \displaystyle\sum_{i=1}^{m} (x_{i, c} - \mu_{\mathcal{B},c})^2 \\[8mm]
&\text{推論時} & \mathbb{E}[x]_c \leftarrow \alpha \cdot \mathbb{E}[x]_c + (1-\alpha) \cdot \mu_{\mathcal{B},c} \\[4mm]
&& \text{Var}[x]_c \leftarrow \alpha \cdot \text{Var}[x]_c + (1-\alpha) \cdot \sigma_{\mathcal{B},c}^2 \\[8mm]
\text{正規化・更新}
&\text{学習時} & \hat{x}_{i, c} = \dfrac{x_{i, c} - \mu_{\mathcal{B},c}}{\sqrt{\sigma_{\mathcal{B},c}^2 + \epsilon}} \\[4mm]
&& y_{i, c} = \gamma_c \hat{x}_{i, c} + \beta_c \\[8mm]
&\text{推論時} & \hat{x}_c = \dfrac{x_c - \mathbb{E}[x]_c}{\sqrt{\text{Var}[x]_c + \epsilon}} \\[4mm]
&& y_c = \gamma_c \hat{x}_c + \beta_c
\end{array}
- $\gamma_c,\beta_c$:チャネルごとの学習可能なスケール・シフト、$m$:バッチ内サンプル数、$\epsilon$:ゼロ除算防止の微小定数
- $\alpha$:移動平均の係数(momentum)。手順1の学習率 $\eta$ とは別物
- 勾配計算
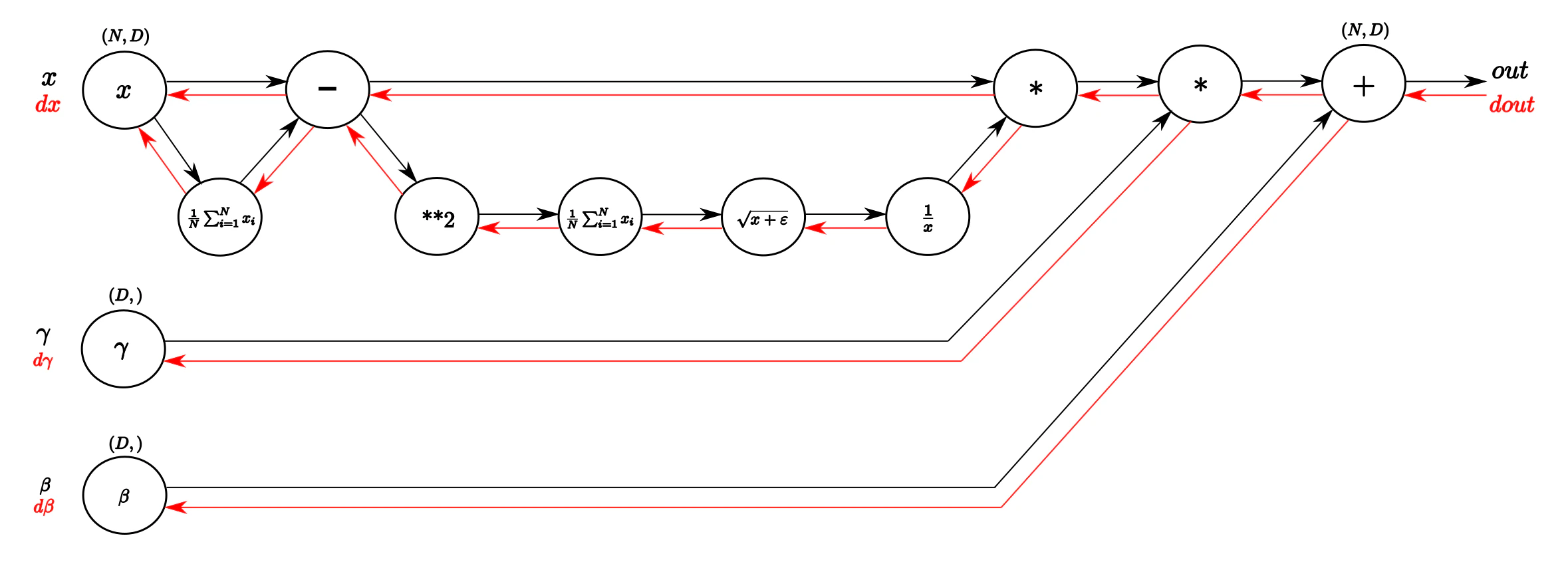
■ LayerNorm
各サンプルの特徴次元全体を正規化することで、バッチサイズに依存しない安定した学習を実現する手法
-
解決できること
- バッチサイズに依存しない正規化
- RNNやTransformerでの学習安定化
- ミニバッチ間の依存関係の排除
- 系列長が可変なタスクへの対応
-
計算フロー
- 各サンプル $n$ ごとに層内全特徴 $K$ 方向で平均・分散を計算し、サンプル単位で正規化・再調整する。学習時と推論時は同じ処理。
\begin{array}{ll}
\text{入力} & \quad\mathbf{x}_n = [x_n^{(1)}, x_n^{(2)}, ..., x_n^{(K)}] \\[8mm]
\text{統計量計算} & \quad\mu_n = \dfrac{1}{K} \displaystyle\sum_{k=1}^K x_n^{(k)} \\[4mm]
& \quad\sigma_n^2 = \dfrac{1}{K} \displaystyle\sum_{k=1}^K \left(x_n^{(k)} - \mu_n\right)^2
\end{array}
■ InstanceNorm
各サンプルの各チャネルごとに独立に正規化を行う手法で、スタイル転送などで効果的
-
解決できること
- スタイル情報(コントラスト、明るさ)の正規化
- 画像生成タスクでの品質向上
- バッチやチャネル間の依存関係の排除
- 画像のスタイル転送での安定化
-
計算フロー
- 各サンプル $n$・各チャンネル $c$ ごとに空間次元 $S$ 方向で平均・分散を計算し、サンプルとチャンネル単位で正規化・再調整する。(空間次元 $S$、例えば画像なら各ピクセル位置)学習時と推論時は同じ処理。
\begin{array}{ll}
\text{入力} & \quad\mathbf{x}_{n,c} = [x_{n,c}^{(1)}, x_{n,c}^{(2)}, ..., x_{n,c}^{(S)}] \\[8mm]
\text{統計量計算}
& \quad\mu_{n,c} = \dfrac{1}{S} \displaystyle\sum_{s=1}^{S} x_{n,c}^{(s)} \\[4mm]
& \quad\sigma_{n,c}^2 = \dfrac{1}{S} \displaystyle\sum_{s=1}^{S} \left(x_{n,c}^{(s)} - \mu_{n,c}\right)^2
\end{array}
■ GroupNorm
チャネルをグループに分割し、各グループ内で正規化を行う手法で、小さいバッチサイズでも安定動作
-
解決できること
- 小バッチサイズでの学習安定化
- Batch Normalizationの代替(バッチサイズ依存の解消)
- 物体検出・セグメンテーションでの性能向上
- メモリ制約下での大規模モデル学習
-
計算フロー
- 各サンプル $n$・各グループ $g$ ごとに、指定した複数チャンネルにまたがる空間次元 $S$ 方向で平均・分散を計算し、グループ単位で正規化・再調整する。学習時と推論時は同じ処理。
\begin{array}{ll}
\text{入力} & \quad \mathbf{x}_{n, c} = [x_{n, c}^{(1)}, x_{n, c}^{(2)}, ..., x_{n, c}^{(S)}] \quad (c = 1, ..., C) \\[8mm]
\text{グループ分割} & \quad C \text{チャンネルを}~G \text{グループに分割} \\[4mm]
& \quad \mathcal{G}_{n, g} : \text{サンプル}~n~\text{内グループ}~g\\[8mm]
\text{統計量計算} & \quad \mu_{n, g} = \dfrac{1}{|\mathcal{G}_{n,g}|} \displaystyle\sum_{j \in \mathcal{G}_{n,g}} x_j \\[4mm]
& \quad \sigma_{n, g}^2 = \dfrac{1}{|\mathcal{G}_{n,g}|} \displaystyle\sum_{j \in \mathcal{G}_{n,g}} (x_j - \mu_{n,g})^2
\end{array}
■ 勾配クリッピング
RNNや深いネットワークなどの逆伝播時の全パラメータの集合勾配 $g$ に対して、勾配のL2ノルムが閾値 $v$ を超えたとき、勾配をスケールして安定した学習を保つ。勾配爆発を防ぐ。
\begin{array}{ll}
\text{勾配ノルムの算出} & \|g\| = \sqrt{ \displaystyle\sum_k \left( \frac{\partial L}{\partial \mathbf{W}_k} \right)^2 } \\[8mm]
\text{しきい値判定}
& \text{if} \; \|g\| > v \\[8mm]
\text{勾配修正}
& g \leftarrow \cfrac{v}{\|g\|} g
\end{array}
ⅲ. アンサンブル手法
キーワード:バギング、ブースティング、ブートストラップ、スタッキング
■ Bagging, Boosting, Stacking
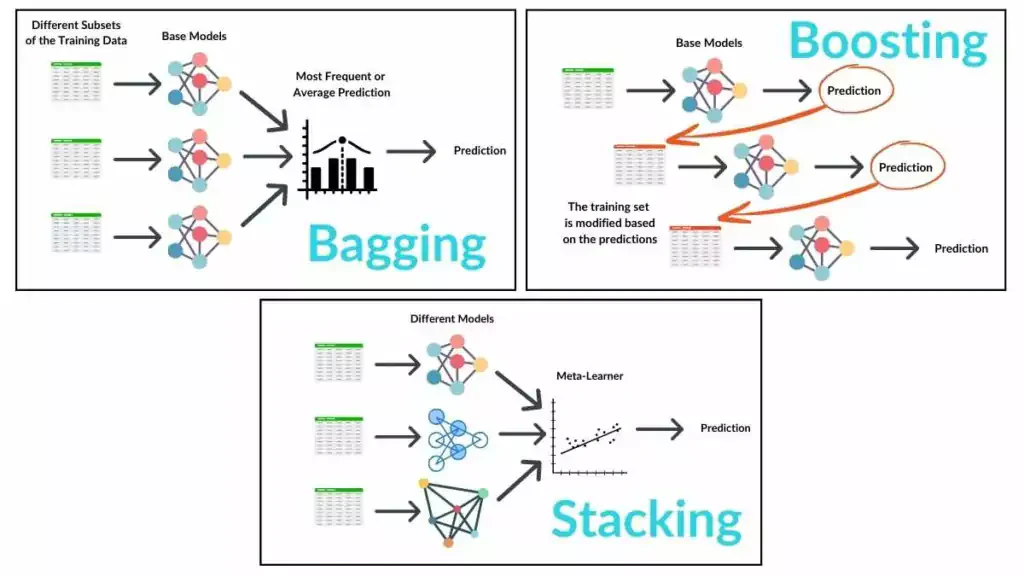
■ Bootstrap Sampling
母集団データから重複を許してランダムにサンプリングを行い、新たなサンプルデータを生成する手法。

ⅳ. ハイパーパラメータの選択
キーワード:基本的なハイパーパラメータ調整、学習率、隠れ層の数 (レイヤー層数)、ユニット数、ドロップアウトの割合、バッチサイズ、ハイパーパラメータの最適化、グリッドサーチ、ランダムサーチ、ベイズ最適化
\begin{array}{ll}
\text{ラベル変換}
& \text{元ラベル } ~ t_k =
\begin{cases}
1 \quad \text{(正解クラス)} \\
0 \quad \text{(不正解クラス)}
\end{cases} \\[4mm]
& \text{平滑化後ラベル } ~
\begin{cases}
1-\epsilon \quad \text{(正解クラス)} \\
\epsilon/(K-1) \quad \text{(不正解クラス)}
\end{cases} \\[4mm]
\text{平滑化ラベル}
& t_k^{LS} = (1-\epsilon)t_k + \epsilon u(k) \\[4mm]
\text{損失関数}
& \mathcal{L} = -\displaystyle\sum_{k=1}^{K} t_k^{LS} \log y_k
\end{array}