はじめに
技術チャレンジ部のとも(Tomo)です。チームTPACで自動運転AIチャレンジ2024に参加中です。
こちらやこちらの記事で作ってみたチャットボットに、Difyを使用して本大会の知識を埋め込んでみました。
素人なので、変なことを言っていたらすいません!
実現したいこと
「本大会の予選の締め切りっていつでしたっけ?」と聞いたら答えてくれる、締め切り駆動型開発の必須機能。
環境
- チャットボットで使った環境そのまま = 自動運転AIチャレンジのGPU環境がベース
-
ZBOX E
- RTX 4070 Laptop GPU搭載
- Ubuntu 22.04 Desktop
- Docker Engine
- NVIDIA Container Toolkit
- self hostedなDify
- OpenAI API
-
ZBOX E
- 今回追加したもの
Reranker
DifyのナレッジとRerankモデル
Difyから使用できる外部サービスはたくさんあり、このチャットボットではOpenAIのLLMを使用していました。
Difyのナレッジで設定できるモデルとしては、埋め込みモデルとRerankモデルがあります。このうち、埋め込みモデルは、OpenAI APIでも提供されるため、そのまま使えましたが、Rerankモデルがありません。
Difyのナレッジの検索設定では、Rerankモデルを使用しない設定もできるため、最初これで試していたのですが、なかなかうまく答えてくれません。外部のRerankサービスを別途使えるようにすることも考えたのですが、重い腰が上がりませんでした(←アカウント作るだけだろ)。
日本語対応Reranker
うまく答えてくれない理由を色々考えていたのですが、そもそもRerankerはどの程度日本語に対応しているのか、気になって検索してみたところ、今年4月のこちらの記事に出会えました。
日本語を適切に学習させたRerankerファミリー
きっと今の私に必要なものです。このようなモデルを公開されていることに、圧倒的感謝です。
DifyからのRerankモデルの使用
ところが、このモデルをどうやって使用するのか、さっぱり分かりません。素人なので…。
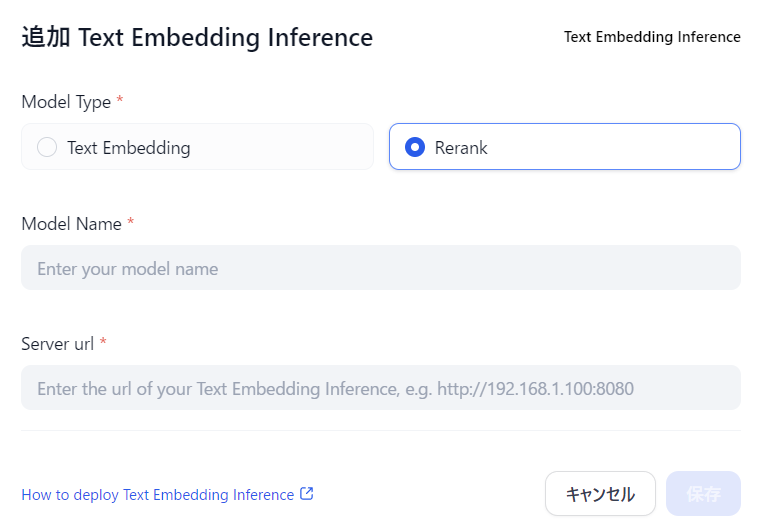
Difyの 設定 -> モデルプロバイダー の画面を見ていると、RERANKと書かれたものがいくつかありますが、その中にサービスのアイコンがないものがあります。Text Embedding Inferenceです。
このモデルプロバイダー設定では、Server urlが設定できるので、ローカルでモデルを実行するサービスを作れば、結合できそうです。
HuggingfaceのText Embedding Inference
Text Embedding Inferenceで検索すると、以下のリポジトリがあるようです。
Using Re-rankers modelsという章もあり、docker化された実行環境に対し、curlでアクセスできるようです。
これは、ローカルでサービスとしてモデルを実行できるのでは…? そしてDifyと結合できるのでは…?
Rerankerサービス
起動
先ほどのUsing Re-rankers modelsに書かれていた起動方法をベースに、以下を変更しました。
- モデル名:
hotchpotch/japanese-reranker-cross-encoder-small-v1 - デーモン化:
-d - Docker Image:
ghcr.io/huggingface/text-embeddings-inference:89-1.5
結果として、以下を入力。
sudo apt install git-lfs
mkdir data
model=hotchpotch/japanese-reranker-cross-encoder-small-v1
volume=$PWD/data
docker run -d --gpus all -p 8080:80 -v $volume:/data --pull always ghcr.io/huggingface/text-embeddings-inference:89-1.5 --model-id $model
モデル名に少し戸惑いました。モデルをローカルに持ってきて指定するのかと思いましたが、Hugging Faceから取ってきてくれるようなので、Hugging Face上のパスを指定します。
ただ、その時にtokenizer.jsonが存在することが必要なようで、japanese-reranker-cross-encoder-small-v1にはこれがあったため、使用してみました。チャットボットであることを考えると、smallが合っていそうな気もします。
Docker ImageはGPUの種類によって変えるようですが、今回の環境はここにある「Ada Lovelace (RTX 4000 series, ...)」に該当するため、text-embeddings-inference:89-1.5を指定しました。あってよかった。
これだけでサービスが起動できるの、ほんと楽…。
動作確認
こちらもUsing Re-rankers modelsに書かれていた通りに実行したら、scoreが取得できました。英語ですが…。
curl 127.0.0.1:8080/rerank \
-X POST \
-d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]}' \
-H 'Content-Type: application/json'
Difyから接続すると、/infoにアクセスするようなので、こちらも確認しておきます。
curl 127.0.0.1:8080/info
Dify
Rerankerサービスへの接続
先ほどのDifyの 設定 -> モデルプロバイダー -> Text Embedding Inferenceにて、以下を設定しました。
- Model Name:
japanese-reranker-cross-encoder-small-v1 - Server url:
http://host.docker.internal:8080
host.docker.internalは、Firecrawlを使えるようにする際に設定していました。
接続すると、以下のように、モデルが表示されます。やった。

ナレッジの作成
Difyでナレッジを作成し、以下のように設定しました。
埋め込みモデルは、コストパフォーマンスが良さそうなtext-embedding-3-smallを指定。
検索設定は、おすすめとあるハイブリッド検索にて、Rerankモデルが設定できるようになったので、japanese-reranker-cross-encoder-small-v1を指定。

ナレッジのドキュメントは、若干の試行錯誤の結果、HTMLよりはMarkdownのほうが良さそうだったので、一旦は本大会の情報をMarkdownで入力し、セグメント設定のチャンク設定は自動としました。
LLMブロック
LLMブロックでは、元の「Knowledge Retreival + Chatbot」テンプレートをそのまま活用してコンテキストを埋め込みました。

結果

ヤバい!(締め切りが)
今後に向けて
上記以外にも、結構うまく答えてくれる場面があり、可能性を感じています。開発の現状をインプットするなど、知識と質問の方法によっては、チームを支援してくれる頼れる仲間になってもらえる気がしています。
うまく答えてもらえないこともまだまだありますが、現状は動かしてみただけ状態で、比較評価ができていません。
各種設定やモデルなどを変えながら、効果を確認していければと思います。