はじめに
前回、LightGBMを使って競馬予測行ったところ、結構良い感じのAUCが出てくれました。
今回はkerasに実装されているニューラルネットワークを使って、競馬予測を行いたいと思います。
行ったこと
LightGBM編と同様に「データの取得→前処理→学習→AUCの算出→考察」を行いました。
環境
Google Colab
手順
1 https://www.netkeiba.com/ よりスクレイピング
2 前処理
3 ニューラルネットワークで学習、予測
1,2 スクレイピングと前処理
スクレイピングと前処理についてはLightGBM編と全く同じ処理をしたのでそちらを見ていただければと思います。数値変数に対して、標準化の処理だけプラスして行いました。
LightGBM編の記事は[こちら]から見れます。
[こちら]:https://qiita.com/tommy24/items/acf5dc4152b4a534c058
3-0 そもそもニューラルネットワークって何?
ニューラルネットワークをすでに知っている人はここは飛ばしちゃってください。
ニューラルネットワークとは、人間の脳内にある神経細胞(ニューロン)とそのつながりを人工ニューロンという数式的なモデルで表現したものです。
イメージ的には以下のような感じです。
人間の脳はこんな感じでニューロンがそれぞれ相互作用し合うことで、情報伝達を行っています。
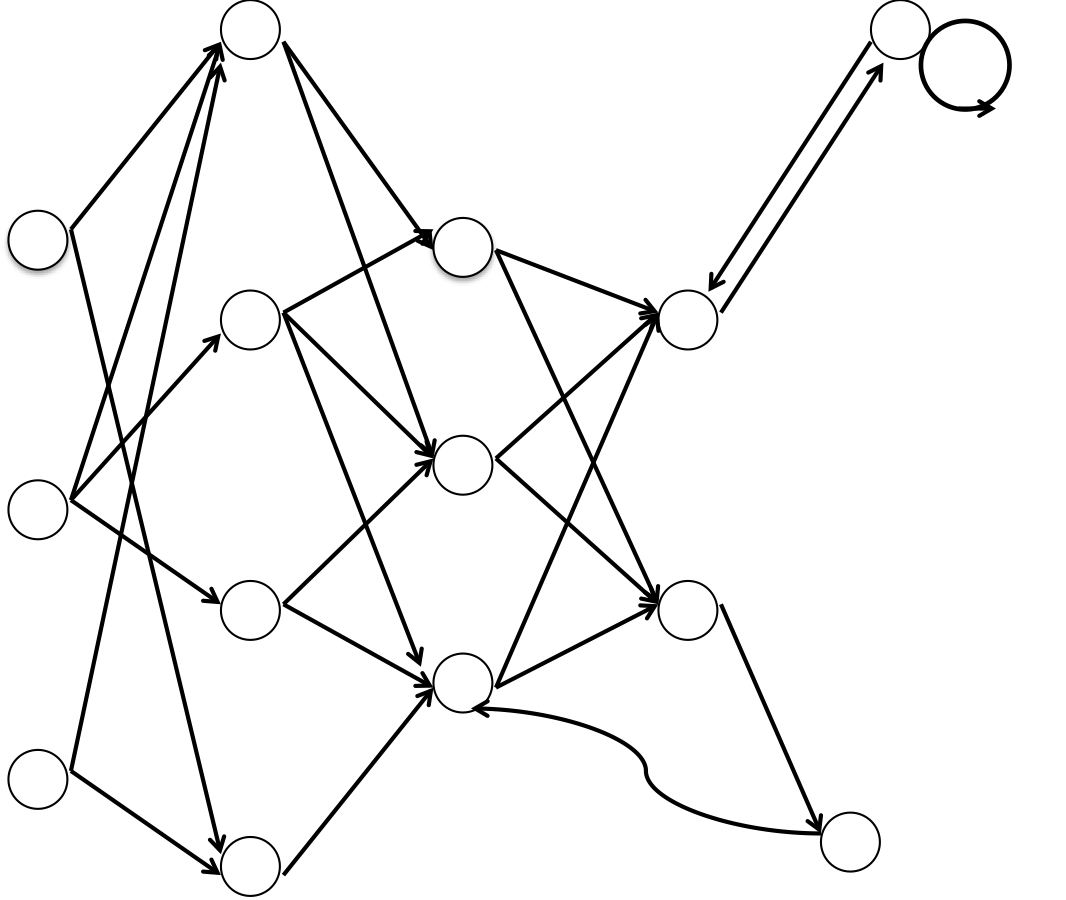
さて、機械学習では次のような図を想像してみてください。

いきなり訳の分からない図が出てきました。笑
これは何を表しているかというと、MNISTというデータセット(7万枚の手書き数字の画像とその正解ラベルが入っている。)に入っている「8」をニューラルネットワークに通して学習をしている図です。この画像は28×28=784ピクセルの画像で、そのピクセル一つ一つをネットワークにいれています。ネットワーク内で起きていることは数学的な話になるので割愛しますが、最終的にこのネットワークは**「確率」を算出してくれます。
何の確率かというと入力した数字が「0」である確率、「1」である確率、、、「9」である確率をそれぞれ出してくれます。「この確率が90%以上だったら8と認識する」みたいに使われます。また、この90%という数字は人間が決め、閾値と呼ばれます。
ちなみに、一番左の層から順に入力層**、中間層、出力層と呼ばれ、白丸一つ一つはノードと呼ばれます。
3-1 kerasについて
kerasはTensorFlowのラッパーライブラリとして登場し、比較的分かりやすいコードで実装されています。今回使用するニューラルネットワークはこのkerasに実装されているものを使います。
また、GPUを使用することで学習を高速化することができます。ちなみにGoogle ColabではGPUが無料で使えます。
3-2 必要なモジュールをimport
# モジュールのimport
import keras
from keras.models import Model,Sequential
from keras.layers import Input, Dense, Activation, Dropout
from keras.layers import BatchNormalization, Add, Dense
from keras.callbacks import ModelCheckpoint
from keras.utils import to_categorical
from keras.initializers import he_normal
import keras.backend as K
3-3 モデルの定義
kerasでニューラルネットワークを実装するには2種類の実装が存在しますが、今回は簡単なSequentialモデルを使用します。Sequentialモデルというのは全結合のニューラルネットワークで、ノードが次の層のノードに全て結合しているものです。(ノードから出る矢印が次のノードに全て繋がっている。)
もう一つのFunctionalモデルは層を分岐させたり、層を飛び越えて結合することができます。こちらの方が自由度があり、複雑なモデルを定義できます。
今回はSequentialモデルを使いますが、やることはニューラルネットワークをcreate_modelという関数で定義して、学習時に呼び出すだけです。
def create_model(optimizer='adam', init='glorot_normal'):
model=Sequential()
model.add(Dense(16, input_dim=X.shape[1], kernel_initializer=init, activation='relu'))
model.add(Dense(8, kernel_initializer=init, activation='relu'))
model.add(Dense(4, kernel_initializer=init, activation='relu'))
model.add(Dense(1, kernel_initializer=init, activation='sigmoid'))
#2値分類なのでbinary_crossentropyを使う
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
model=create_model()
書き方はこんな感じです。はじめにmodel=Sequential()として空のネットワークを生成し、そこに後からaddメソッドで層を追加していきます。
今回は入力層、中間層2層、出力層の計4つの層で学習します。
3-4 学習
前処理は終わっているのでfitメソッドで学習させていくのですが、ここでkerasの便利機能を紹介しておきます。
それはコールバックという機能です。コールバックとは学習中にある条件を満たした時に作動する機能です。今回は2つのコールバックを設定します。
1つ目はEaryStoppingです。これは何エポック連続でvalidationのlossや何かしらの指標が改善しなかったら、指定したエポック数に達していなくても学習を終了してくれます。
2つ目はModelCheckpointです。これは1エポック目からのvalidationの何かしらの指標の値を内部で保持しておいて、その指標がそれまでのエポックでベストを記録した場合、そのモデルをdumpする機能です。
直感的には最終エポックが一番良いモデルになりそうですが、実際学習させると全エポックが20エポックで12エポック目がベストだったなんてことはよくあります。何も設定しないと最終エポックの20エポック目が採用されますが、ModelCheckpointを設定することで、ベストである12エポック目を採用してくれます。
※batch-size(2のn乗にするのが一般的らしい)とepochsは適当に設定してください。
# checkpointとearystoppingの設定
es = EarlyStopping(monitor='val_loss', patience=3, verbose=1)
cp = ModelCheckpoint(filepath = 'best_model.h5', monitor='val_loss', save_best_only=True, verbose=1)
history = model.fit(x=X_train, y=y_train,
validation_data=(X_test, y_test),
batch_size=512,
epochs=100,
shuffle=True,
callbacks=[es, cp]
)
学習を始めるとこんな感じになります。

Earystoppingのおかげで途中で学習が止まりました。
最終的には20エポック目で止まっています。

3-5 AUCの確認
最後にAUCを確認します。
pred = model.predict(X_test)
print(roc_auc_score(y_test, pred))
 LightGBMで予想した時とほとんど同じでした。もっと変わると思ったのですが、前処理が同じだとモデルを変えてもAUCはあまり変わらないようです。よく言われていますが、やはり機械学習は前処理が命ですね。
LightGBMで予想した時とほとんど同じでした。もっと変わると思ったのですが、前処理が同じだとモデルを変えてもAUCはあまり変わらないようです。よく言われていますが、やはり機械学習は前処理が命ですね。
おわりに
今回はニューラルネットワークを使って、競馬AIを実装してみました。結果はLightGBMで予想した時とあまり変わりませんでした。
LightGBMではハイパーパラメータをいじってもそこまで大きく精度が変わることはなく、特徴量生成やアンサンブル学習によって精度を上げることが課題でした。
しかし、ニューラルネットワークでは層を何層も重ねたり、Dropout層を追加したりすることで精度の向上が予想されます。ただこの辺りは経験が大事になってくると思うので、とにかくいじってみることが大事ですね。
そして、残念なことにこのモデルも回収率を一切考慮していないのでこれを使って儲けることは出来ません。
これからは回収率シュミレーションなども行い、モデルの精度を上げていきたいと思います。(頑張って精度上げて儲けたい!)
最後までご覧いただき、ありがとうございました。
全コードは以下に掲載しています。
https://github.com/suzuki24/keiba
参考
・https://ml4a.github.io/ml4a/jp/looking_inside_neural_nets/
・https://www.sbbit.jp/article/cont1/33345
・https://ja.wikipedia.org/wiki/%E3%83%8B%E3%83%A5%E3%83%BC%E3%83%A9%E3%83%AB%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF
・Python機械学習プログラミング 達人データサイエンティストによる理論と実践