はじめに
みなさんは競馬をしたことがありますか?
私は機械学習を勉強して初めて、競馬に触れました。
プログラミングを勉強する上で「手を動かしながら学ぶ」というのがあります。私は、せっかく勉強するなら楽しく勉強できる題材がいいと思いました。
そこで色々調べた結果、
・特徴量や予測する際のアプローチが多い→やりがいがある
・お金に関係ある→ツールとして作ればビジネスにもなる
・欲しい結果はレース結果として毎週更新される→勉強がしやすい
以上3つの観点から競馬を選びました。
初めての記事なので、分かりにくい部分が多々あるかと思いますが、その際はご指摘いただけると幸いです。
行ったこと
競馬データを分析し、予測精度(AUC)を出すところまで行いました。本当は実際に予測した後に、回収率などを出せるともっと面白そうですが、そこまでの技術はないので「データの取得→前処理→学習→AUCの算出→考察」まで行いました。
環境
Google Colab(初めはローカルのJupyter labで行っていましたが、私のPCでは学習時にkernelが落ちてしまうため、Google colabを使用しました。)
手順
1 https://www.netkeiba.com/ よりスクレイピング
2 前処理
3 lightGBMで学習、予測
1 netkeiba.comよりスクレイピング
この工程は https://qiita.com/penguinz222/items/6a30d026ede2e822e245 を参考にさせていただきました。
2 前処理
スクレイピングしてきたCSVファイルはこんな感じです。

データの大きさは約50万行×20列です。
これらに対して前処理を行っていきます。
先に、一般には馴染みのない列名があるので解説します。
・c_weight...前回のレースからの体重差
・j_weight...ジョッキーの体重
・popu...人気(運営側が事前情報によって馬それぞれに人気をつけます)
・odds...払い戻し額÷掛け金(人気な馬ほどoddsは低いです。)
・trainerA,trainerB...調教師
2-1 データを扱いやすくする
一番左の列がUnnamed:0となっています。この列は開催された日付、レース番号、馬番が連なっていますので、これは2列に分解します。
# データの読み込み
# Unnamed0のカラムは日付、レース番号、馬番号なのでrenameして分割。
keiba_data = pd.read_csv('/content/drive/MyDrive/競馬.csv', encoding = "shift-jis")
keiba_data.rename(columns={"Unnamed: 0":"date_num"},inplace=True)
keiba_data["date_num"]=keiba_data["date_num"].astype(str)
keiba_data["race_num"]=keiba_data["date_num"].str[0:12].astype(int)
keiba_data["horse_num"]=keiba_data["date_num"].str[12:14].astype(int)
keiba_data.drop(columns=["date_num"],inplace=True)
# 扱いやすいようにrace_numとhorse_numは一番左に配置。
keiba_data=keiba_data.reindex(columns=['race_num','horse_num','age', 'c_weight', 'course', 'date', 'field', 'gender', 'head_count',
'horse_name', 'j_weight', 'jackie', 'odds', 'popu', 'race', 'race_name',
'rank', 'trainerA', 'trainerB', 'weight', 'year'])
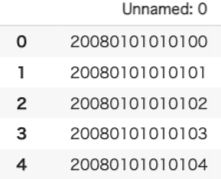
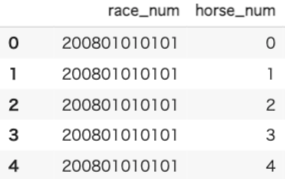
2-2 欠損値処理
データに欠損値があるか確認します。
keiba_data.isnull().sum()

いくつか欠損値があります。今回、学習に使うモデルはlightGBMという欠損値の処理をしなくていいモデルなのですが、どこかでlightGBMも欠損値処理をした方が精度があがるという記事をみたので(すいません、どの記事かは忘れてしまいました。)欠損値処理を行ってみます。
intの列は0や平均値で埋めていき、objectの列はdropしていきます。
popuとoddsはかなり重要な要素となることが予想されるので、欠損値は平均値や中央値では埋めずdropしました。
ただ、どの欠損値も2000以下なので、どう処理しても体勢に影響はないと思います。
# 欠損値処理
keiba_data["c_weight"].fillna(0,inplace=True)
keiba_data["j_weight"].fillna(keiba_data["j_weight"].mean(),inplace=True)
keiba_data["weight"].fillna(keiba_data["weight"].mean(),inplace=True)
keiba_data.dropna(subset=["race_name"],inplace=True)
keiba_data.dropna(subset=["odds"],inplace=True)
keiba_data.dropna(subset=["popu"],inplace=True)
2-3 データ型の確認
keiba_data.dtypes

object型は全てLabel Encoderによってint型に変換します。
その後、yearなどの不要な列を削除します。
# labelencoderを使って、カテゴリ変数を変換。
le=LabelEncoder()
keiba_categorical = keiba_data[["gender","field","horse_name","course","head_count","trainerA","trainerB","race","jackie","race_name"]].apply(le.fit_transform)
keiba_categorical = keiba_categorical.rename(columns={"race_name":"race_name_c","filed":"field_c","gender":"gender_c","horse_name":"horse_name_c","course":"course_c","head_count":"head_count_c","trainerA":"trainerA_c","trainerB":"trainerB_c","jackie":"jackie_c"})
keiba_data = pd.concat([keiba_data,keiba_categorical],axis=1)
# 変換前と不要な列を削除
keiba_data.drop(columns=["race_num","horse_num","date","year","race_name","race","trainerA","trainerB","course","field","gender","jackie","head_count","horse_name"],inplace=True)
2-4 特徴量生成
oddsとpopuはかなり重要な特徴量と考え、それらの積をとった特徴量(odds_popu)とc_weightから前回の体重が分かるので前回の体重(pre_weight)を新たに特徴量として追加しました。
# 特徴量生成
# 1つ目はoddsとpopuの積
# 2つ目は前回の体重
keiba_data["odds_popu"]=keiba_data["odds"]*keiba_data["popu"]
keiba_data["pre_weight"]=keiba_data["weight"]-keiba_data["c_weight"]
2-5 目的変数の処理
ここから目的変数であるrankの処理を行います。
# rankの確認
keiba_data["rank"].unique()

すると順位以外に中止、失格の行があります。rankが分からなければ、学習もできないのでこの行は全てdropします。count()で数えると約2000と数も少ないのでdropしても大丈夫そうです。
# 中止、失格の行は全て削除する。
delete_index = keiba_data.index[((keiba_data["rank"]=="中止") | (keiba_data["rank"]=="失格")]
keiba_data.drop(delete_index,inplace=True)
さて、順位を予測したいところですが、競馬は基本的には3着以内に入るかが賞金に関わってきます。逆に言えば、7位や8位の馬をドンピシャで当てる必要はありません。
ということで、3着以内かそれより下位かの二値分類問題にしようと思います。要は勝つか負けるかですね。
他の方の記事では上位、中位、下位と3つに分けて多値分類問題にしてる方もいらっしゃいました。
# 1,2,3着かそれ以外かに分割して、二値分類問題にする。
keiba_data["rank"]=keiba_data["rank"].astype(int)
keiba_data = keiba_data.assign(target = (keiba_data['rank'] <= 3).astype(int))
3着以内であれば1,それより下位であれば0を与えたtargetという列を作りました。
ここまでが前処理になります。次はlightGBMを使って、学習→予測まで行います。
ここまで処理したデータはこんな感じです。
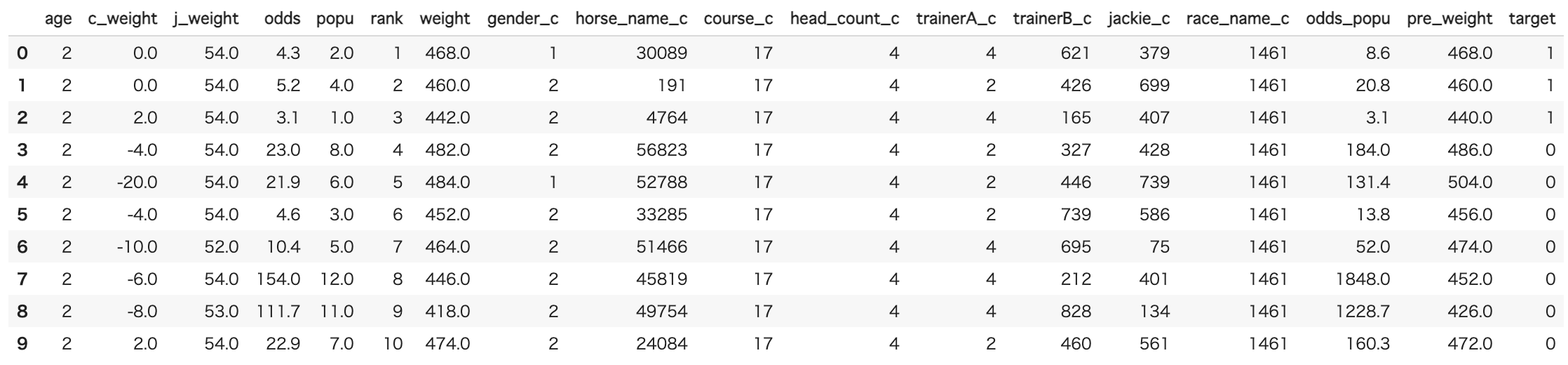
3 学習、予測
特徴量と目的変数をXとyに分割して、さらに学習用データと評価用データに分割します。
またそれらのデータをlgb.DatasetでlightGBMで読めるデータに変換します。
# trainデータおよびtestデータの分割と特徴量および目的変数の分割
import lightgbm as lgb
X = keiba_data.drop(['rank','target'], axis=1)
y = keiba_data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
# データの変換
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test)
パラメータチューニングに関してはoptunaというフレームワークを使って、自動で決めます。
# ハイパーパラメータをoptunaで自動設定
%%time
!pip install optuna
from optuna.integration import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'auc'
}
best_params, history = {}, []
model = lgb.train(params, lgb_train, valid_sets=[lgb_train,lgb_eval],
verbose_eval=False,
num_boost_round=10,
early_stopping_rounds=10)
best_params_ = model.params
# モデルの作成
import lightgbm as lgb_orig
model = lgb_orig.train(best_params_,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=100,
early_stopping_rounds=10)
最終的なAUCは
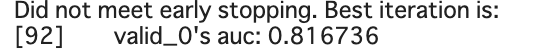
でした。AUCなので82%当てているということではないですが、思ったよりいい数値が出てくれました。
(AUCについてはこちらのサイトが分かりやすかったです。
https://techblog.gmo-ap.jp/2018/12/14/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E8%A9%95%E4%BE%A1%E6%8C%87%E6%A8%99-roc%E6%9B%B2%E7%B7%9A%E3%81%A8auc/)
最後に特徴量の重要度をみてみます。
# 特徴量の重要度を表示。
keiba_data.drop(columns = ["rank","target"],inplace=True)
importance = pd.DataFrame(model.feature_importance(), index=keiba_data.columns,columns=['importance'])
importance=importance.sort_values(by="importance",ascending=False)
display(importance)

やはりoddsはかなり重要な特徴量であるようです。また馬に乗るジョッキー(jackie_c)も重要なようです。
意外だったのはpopuやtrainerAの重要度が低いという点です。しかしtrainerBは重要度が高いです。この辺りは競馬に詳しい人に聞いた方が良いかもしれないです。筆者は競馬を数回しかやったことがないので、この辺りはまだまだ勉強が必要です。
おわりに
今回、前処理について基礎的なことしか行っていませんが、AUCは0.816736という割と良い数値がでました。
結構当てくれるので、これを使えば儲かるかと言われるとまたそれは別の問題になってきます。モデルは3着以内に入るか否かだけを判定してくれてるので、いくら賭けていくら戻ってくるなどの回収率は一切考慮していません。
人気な馬に賭けておけば的中しやすくなりますが、その分oddsは低いので払い戻し金額も少なくなってしまいます。
要するに「当たるけど、戻ってくるお金は少ない」ということです。
理想は穴馬(oddsが高い不人気な馬)にもかけつつ、人気な馬で安定的に稼ぐみたいな感じがいいのかなと思います。
最終的にできたモデルはDjangoなどで実装して日付とレース番号を入れると、予測を返してくれるようなものを作りたいと思っています。
これを作ってて思いましたが、好きな題材でプログラミングの勉強ができるのは良いですね。とても楽しかったです。
冒頭でも書きましたが、競馬はこれ以外のアプローチもたくさんあります。
・レース直前のTwitterのツイートを分析し、どの馬がどれくらいポジティブな言葉でツイートされているかで予想
・系統(ディープインパクトの子供は強いなど)を特徴量に入れる
・別のモデルの使用やタイムを予測する回帰問題として考える
などなど色々あると思いますので、いずれは他に手法にも挑戦したいと思います。最後までご覧いただきありがとうございました。
全コードは以下に掲載しています。
https://github.com/suzuki24/keiba
参考にさせていただいた記事
・https://qiita.com/Mshimia/items/6c54d82b3792925b8199
・https://qiita.com/km_takao/items/0a448543961a97fc9c94
・https://qiita.com/km_takao/items/70f7a7c3c9c533d7bee4
・https://techblog.gmo-ap.jp/2018/12/14/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%AE%E8%A9%95%E4%BE%A1%E6%8C%87%E6%A8%99-roc%E6%9B%B2%E7%B7%9A%E3%81%A8auc/