はじめに
新型コロナウイルス感染者数の増加関連して、各都道府県ごとで感染者数を確認できるサイトが多く登場してきました。しかしながら厚生労働省のホームページには肝心の各都道府県ごとの感染者数のデータは今でもPDFだけでしか提供されていません。
そこで今回は厚生労働省のホームページで公開されているPDFデータを自動でスクレイピングし、APIとしてjsonでダウンロードできるようなコードを書いていこうと思います。
PDFファイル内の表を文字列に変換するのは難しいのではないかと思う方も多いと思いますが、実はpythonにはtabula-pyライブラリというものがありまして、PDF内の表を簡単にpandasのフレームに変換できるんです。
流れとしましては次の4ステップになります。
- 厚生労働省のホームページからPDFのURLをpythonのbeautifulsoupを使ってスクレイピング
- PDFファイルをpythonのurllibでダウンロードする
- pythonのtabula-pyライブラリを用いて、pdf内の表をpandasフレームに変換する
- flaskサーバでjsonを返すサーバを作る
今回作成したAPIが各都道府県の感染者状況を見れるサイトを運営している方に届いたら幸いです。
厚生労働省のホームページからPDFのURLをスクレイピング
下記のURLにて、毎日の発生状況が更新されているページがあります。今回は毎日スクリプトを実行することを想定して、一番上のURLだけをスクレイピングするようにしようと思います。
https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000121431_00086.html
下記がスクレイピングのコードになります。次のコードはpythonのbeautifulsoupとurllibを使用して当日のURLを取得しています。
import urllib.request
from bs4 import BeautifulSoup
def extract_page_url(infomation_url):
req = urllib.request.Request(infomation_url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
topic = soup.find_all('div', attrs={'class': 'm-grid__col1'})[1]
article_urls = [tag['href'] for tag in topic.find_all('a', href=True)]
article_titles = [tag.text for tag in topic.find_all('a', href=True)]
return article_urls, article_titles
target_url = "https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000121431_00086.html"
page_urls, page_titles = extract_page_url(target_url)
さきほどのURLをクリックしたら、次のページに移動します。今回は各都道府県別の陽性患者数を知りたいので、赤枠で囲んでいる「各都道府県の検査陽性者の状況」のpdfのurlを取得します。

def get_pdf_url(target_url):
req = urllib.request.Request(page_url)
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
for atag in soup.find_all('a', href=True):
if '各都道府県の検査陽性者の状況' in atag.text:
return atag['href']
pdf_url = "https://www.mhlw.go.jp" + get_pdf_url(page_urls[0])
PDFファイルをpythonのurllibでダウンロードする
各都道府県の検査陽性者の状況は下記のようなPDFになっています。
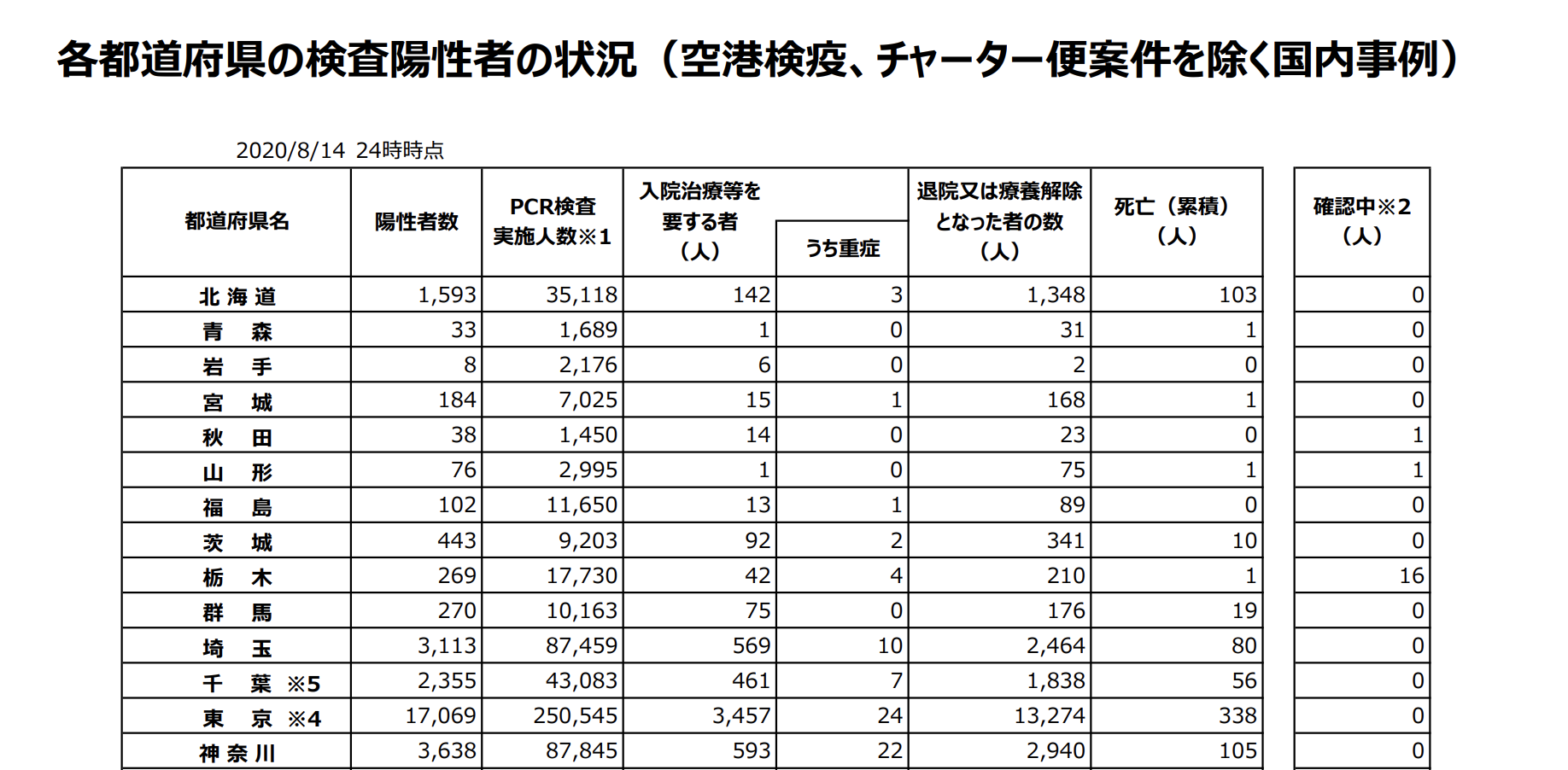
PDF内の表をローカルで読み込むために一度ローカルにダウンロードします。web上のファイルにはurllibのurlretrieve関数を使用してダウンロードできます。
pdf_file_name = "infected_person_data.pdf"
urllib.request.urlretrieve(pdf_url, pdf_file_name)
pdf内の表をpandasフレームに変換する
TabulaというPDF内の表を読み込み、CSV形式で出力できるOSSライブラリがあります。
今回はそのpython実装のtabula-pyを使用します。
他にも表から変換できるライブラリもありますが、特にtabula-pyはPDF内の表をPandasに変換できるのでおすすめです。
import pandas as pd
import tabula
df = tabula.read_pdf(pdf_file_name, pages = '1', multiple_tables = False)[0]
これだけでは列名などが適切に読み込まれないため、次のようにdata frameを整形してあげます。次のコードでは、列名の変更、naの除去、不必要な列の削除、indexのフリ直しなどを行っています。
df = df.drop(["Unnamed: 9", "Unnamed: 10"], axis=1)
df = df.rename(columns={"Unnamed: 0": "都道府県名",
"Unnamed: 1": "陽性者数",
"Unnamed: 2": "PCR検査実施人数",
"入院治療等を": "入院治療等を要する者",
"Unnamed: 4": "うち重症",
"Unnamed: 5": "退院又は療養解除となった者の数",
"Unnamed: 7": "死亡(累積)",
"Unnamed: 8": "確認中"})
df = df.fillna(0)
df = df.drop(df.index[[0, 1, len(df)-1, len(df)-2]])
df.reset_index(drop=True)
df.index = np.arange(1, len(df) + 1)
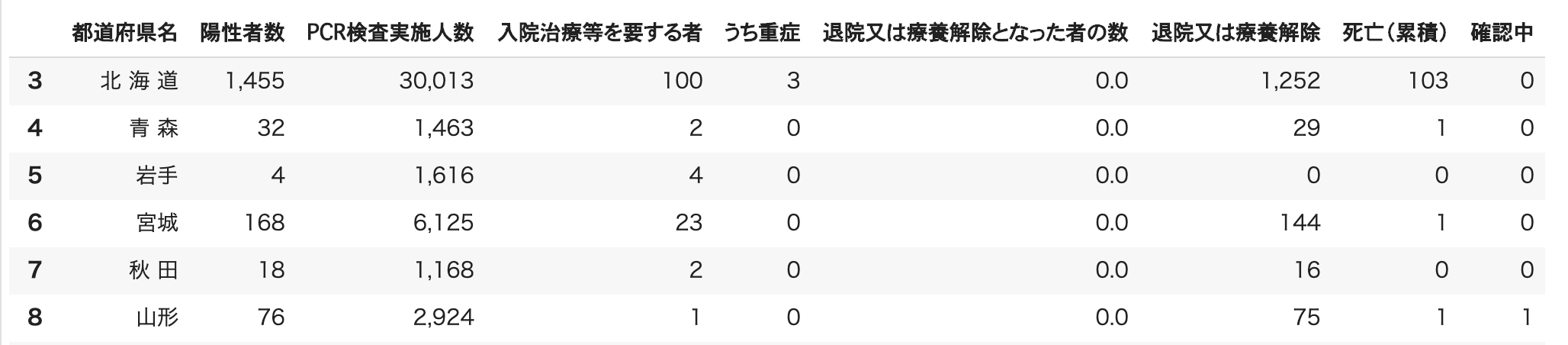
上記の図は読み込んだdata frameの整形後の中身です。
これで無事に表データをきれいにpandasのdata frameとして読み込むことができました。
flaskサーバでjsonを返すサーバを作る
最後に読み込んだpandasのdata frameをjsonとして返すflaskサーバを構築していこうと思います。
先程作成したdf変数をjsonに変換して返すエンドポイントを作成します。
from flask import Response
app = Flask(__name__)
@app.route("/")
def infected_person():
return Response(df.to_json(orient="records"), mimetype='application/json')
次のコマンドでflaskサーバを立ち上げます。これで外部からこのサーバにアクセスしてきたときに表データをjsonとして受け取ることができるようになりました。
env FLASK_APP=server.py flask run
おわりに
今回は厚生労働省のホームページで公開されているPDFデータを自動でスクレイピングし、APIとしてjsonでダウンロードできるflaskサーバを立てるまでの過程を一通り触れました。
スクレイピングで大量のアクセスをするのは良くないことです。誤って毎回毎回ホームページにアクセスするような構造にしないように気をつけてください。更新されるのは一日一度しかないのでスクレイピングの頻度も一日一度がいいと思います。
今後は今回作成したAPIを誰でも簡単に叩けるようにheroku等で公開しようと思います。
ぜひこのAPIが各都道府県の感染者状況を見れるサイトを運営している方に届いたら幸いです。