Overview
AWS Glue のスクリプトで、DynamicFrameWriter を使ってできることより、もう少し色々細かいことをやりたかったので、PostgreSQL の RDS インスタンスに Python のライブラリで接続したかった。
その手順メモ。
なお、Glue では pure-Python なライブラリしか使えない。例えば pandas のような C library は未サポート。なので pg8000 を使う。
Procedure
手順
- pg8000, scramp (依存で必要) の tar ファイルをダウンロード
- tar を解凍して zip を作る
- zip を s3 に置く
- Glue job の設定、Python library path に s3 のパスを入力
詳細は以下
1. pg8000, scramp (依存で必要) の tar ファイルをダウンロード
pypi から tar がダウンロードできるのでローカルに落とす。
(pypi > "Download files")
以下直リンク
2. tar を解凍して zip を作る
落としてきた tar を解凍すると、中にライブラリ本体のソースコードがあるのでそれを抜いて zip にする。
pg8000
$ tar xzf pg8000-1.16.5.tar.gz --strip-components 1 pg8000-1.16.5/pg8000/
$ zip -r pg8000.zip pg8000
adding: pg8000/ (stored 0%)
adding: pg8000/_version.py (deflated 31%)
adding: pg8000/__init__.py (deflated 58%)
adding: pg8000/core.py (deflated 76%)
adding: pg8000/exceptions.py (deflated 77%)
adding: pg8000/converters.py (deflated 74%)
scramp
$ tar xzf scramp-1.2.0.tar.gz --strip-components 1 scramp-1.2.0/scramp/
$ zip -r scramp.zip scramp
adding: scramp/ (stored 0%)
adding: scramp/_version.py (deflated 31%)
adding: scramp/__init__.py (deflated 41%)
adding: scramp/core.py (deflated 75%)
adding: scramp/utils.py (deflated 56%)
3. zip を s3 に置く
ここでは仮に以下の場所に置いたとする。
-
s3://tommarute/python/lib/pg8000.zip -
s3://tommarute/python/lib/scramp.zip
4. Glue job の設定、Python library path に s3 のパスを入力
以下に入力。
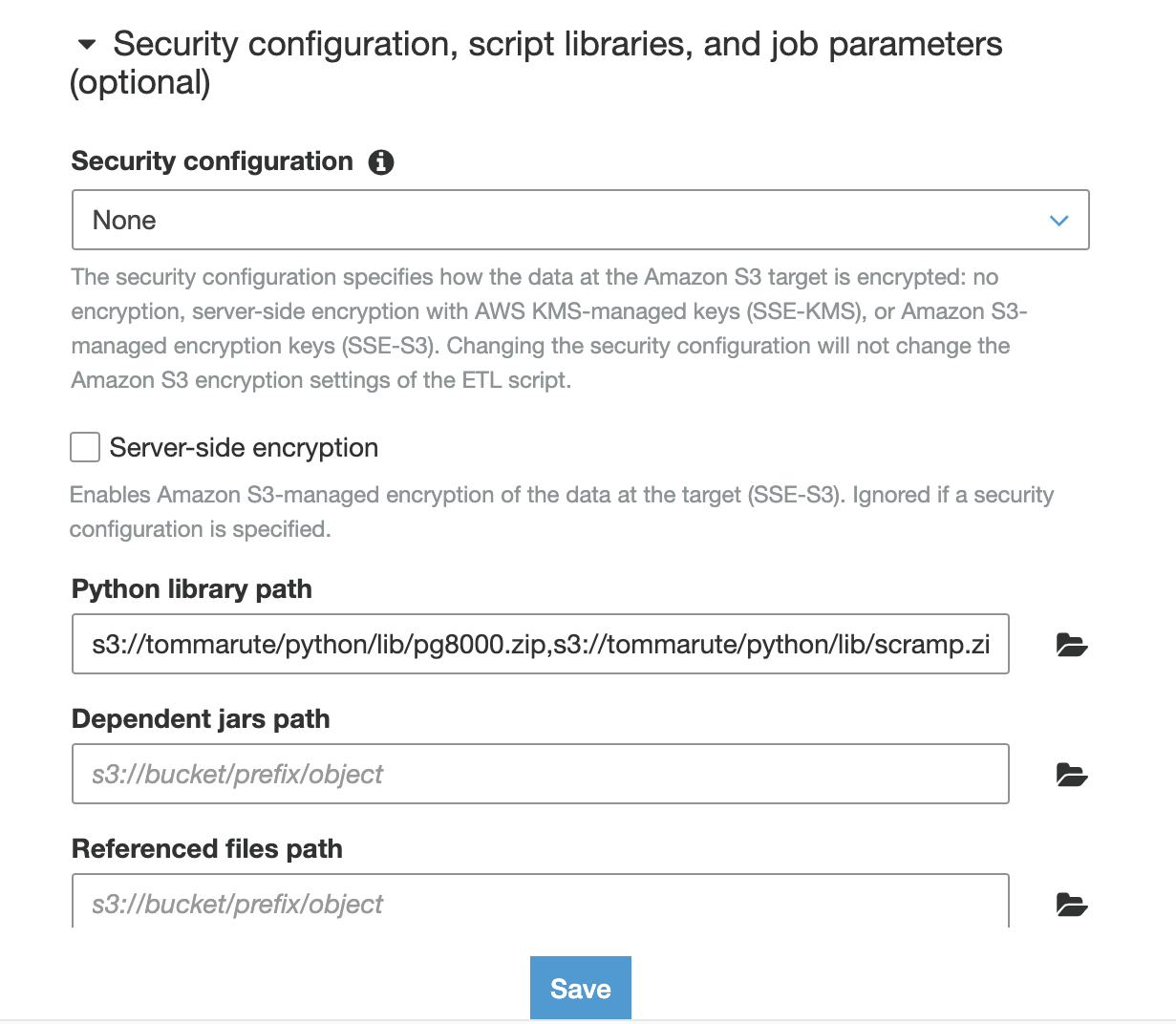
複数あるのでカンマで区切る。
s3://tommarute/python/lib/pg8000.zip,s3://tommarute/python/lib/scramp.zip
これで設定は完了
使う
後は普通に import して使えばOK
例えばこんな感じ
import pg8000
DSN = {
'host': 'postgres.xxxx.us-east-1.rds.amazonaws.com',
'port': 5432,
'database': 'ec',
'user': 'tommarute',
'password': 'secret'
}
table = 'my_contact'
with pg8000.connect(**DSN) as con:
res = con.run("SELECT count(*) FROM information_schema.tables WHERE table_name = :table", table=table)
table_count = res[0][0]
print(f'table_count of {table} = {table_count}')
使い方のサンプルは pg8000 の Github リポジトリに豊富に載っている。
なお、Glue の jupyter notebook で使いたい場合は、Dev endpoints の設定で上記 4 で行った設定をすればいける。