Apache Solrとは
- オープンソースの全文検索エンジン
- 競合にApache Lucene, Elasticsearch, Vespa, など
全文検索とは
- ユーザがクエリ文字列を入力すると、文書のランキングを出力
- 技術スタック
- 文字列を形態素解析してトークンにして
- トークンで転置インデックスを引いて
- 引き当てた文書のリスト(ポスティングリスト)をマージして
- このとき、例えば共通部分にマージするとブーリアンAND検索
- リスト中の各文書をTFIDFやBM25などの式でスコアリングして
- スコアが高い文書を優先度つきキューに保持しておいて
- 最後に取り出すと、文書のランキングになっている
- 競合は古典的な書籍の索引、ベクトル検索など
文書とフィールド
-
文書は、単にスコアリングやランキングの単位
- 製品、ニュース記事、質問文、ヘアスタイル、……なんでも
- データベースで言うレコードに相当
- 文書は一般に複数のフィールド型の複数のフィールドから成る
- 商品には商品名 (Str.), 価格 (Int.), 説明文 (Text) などがある
- データベースで言うカラムに相当
- 文書を集めたものがコア(Solr独自の用語)
コアを作成する
- XMLでスキーマを決めてコアを作成
- 以下、具体例はSolrのサンプルデータtechproductsから抜粋
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="cat" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="price" type="pfloat" indexed="true" stored="true"/>
<field name="inStock" type="boolean" indexed="true" stored="true" />
<field name="store" type="location" indexed="true" stored="true"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
…
文書を保存する
- SolrはWebサーバ (Jetty)。文書を例えばCSVでHTTP POST
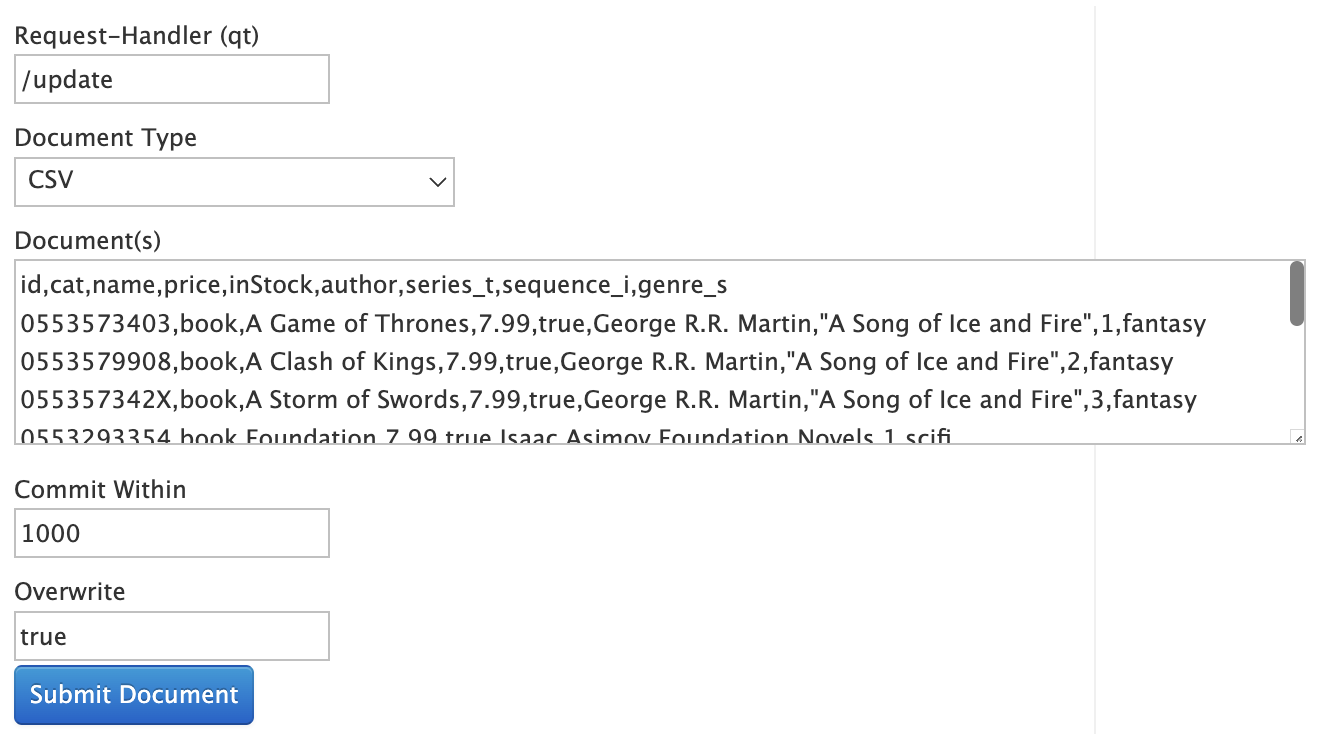
クエリを入力する
- 独自のクエリ言語でHTTP GET
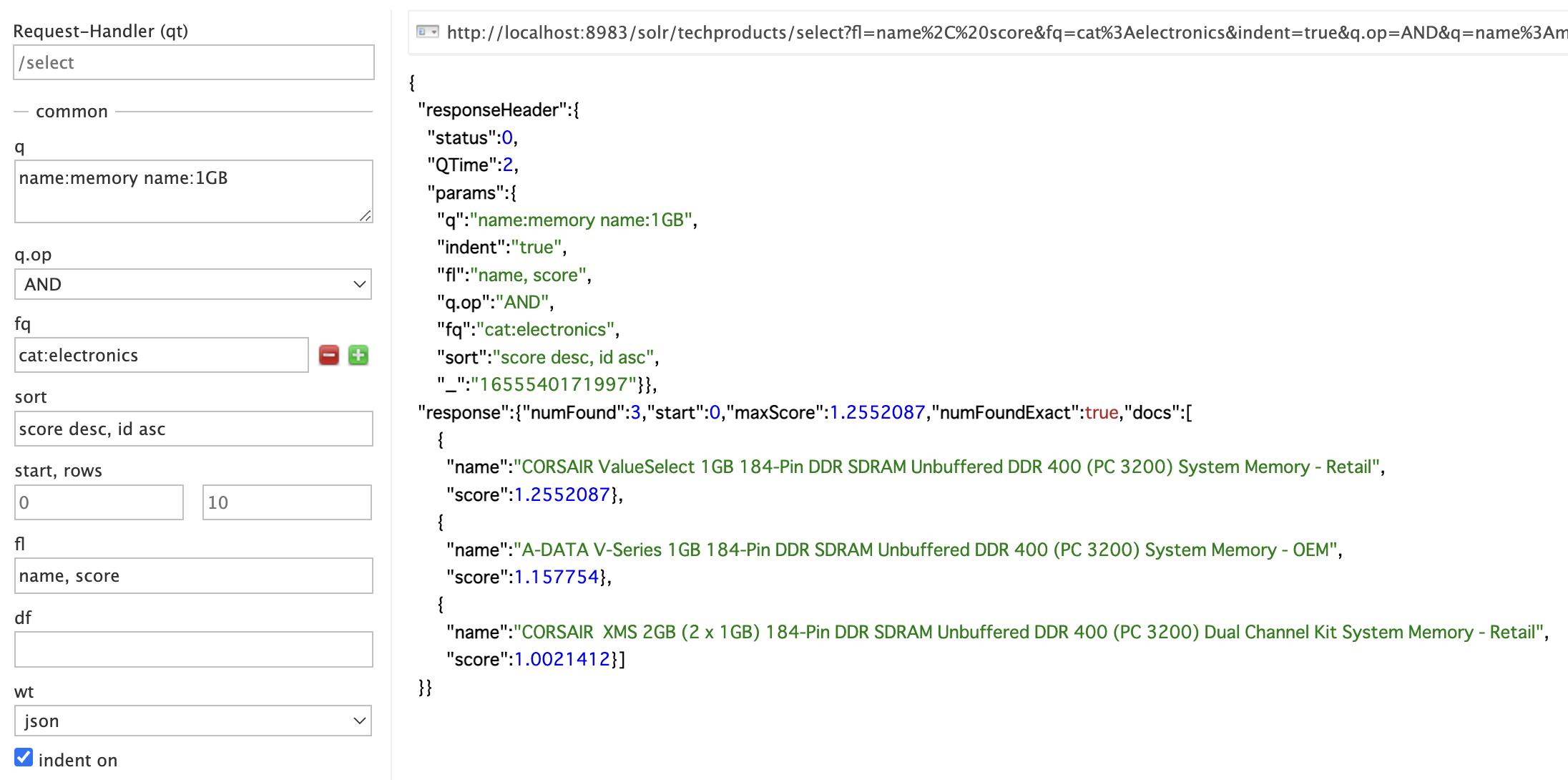
ヤフーのランキングプラグイン
- 以上、Solrにはさまざまな標準機能があるが、
ヤフーで使うには不足も - 独自のランキングプラグインを開発
- スコアの計算式を独自に記述する機能
- ランキング上位の文書を、より重いがより高精度な計算式
(要は機械学習したモデル)でリランキングする機能 - モデルを機械学習するために、外部に特徴量をダンプする機能
- など
- 参照:Solrで多様なランキングモデルを活用するためのプラグイン開発
https://www.slideshare.net/techblogyahoo/solr-solrjp