IBM PowerやIBM Z向けに提供されているIBM Spyreを使ってLLMを動かしてみます。
現在、IBM Spyre for Power向けには Red Hat AI Inference(RHAII)が提供されています。
RHAIIはRed Hatが提供するvLLMベースの推論用サーバーです。
Kubernetes などのオーケストレーター環境を使わず、podman run だけで手軽に試せる方法です。
Spyre for Powerの基本的な使い方である ai-services を使用する方法は下記の記事にまとめています。
環境
- サーバー : IBM Power(Spyre アクセラレーター搭載)
- OS : RHEL 9.6
- コンテナランタイム : Podman
- コンテナイメージ :
registry.redhat.io/rhaii/vllm-spyre-rhel9:3.4.0 - モデル :
ibm-granite/granite-3.3-8b-instruct
Spyre カードの ID を確認する
まず、搭載されている Spyre(IBM AIU)の PCIe ID を確認します。
1014:06a7 がSpyreのデバイスIDなので、 -d でSpyreのみ表示可能です。
lspci -d 1014:06a7
実行例:
# lspci -d 1014:06a7
0381:50:00.0 Processing accelerators: IBM Spyre Accelerator (rev 02)
0382:60:00.0 Processing accelerators: IBM Spyre Accelerator (rev 02)
0383:70:00.0 Processing accelerators: IBM Spyre Accelerator (rev 02)
0384:80:00.0 Processing accelerators: IBM Spyre Accelerator (rev 02)
0481:50:00.0 Processing accelerators: IBM Spyre Accelerator (rev 02)
コンテナ起動時にPCIe IDが必要になります。
コピーしやすいように一行で表示できるコマンドはこちら。
lspci -d 1014:06a7 | awk '{print $1}' | paste -sd" " -
実行例:
0381:50:00.0 0382:60:00.0 0383:70:00.0 0384:80:00.0
コンテナを起動する
以下の環境変数を設定したうえで podman run を実行します。
AIU_IDS は使用するカードを絞りたい場合は手動で指定してください。
今回は簡易的に ai-services を実行時にダウンロードされているモデルをそのまま使用します。
本来は、root権限を持たないユーザーを作成しモデルをダウンロードする方法が推奨されています。
詳細が記載されているドキュメントはこちらです。
export AIU_IDS="$(lspci -d 1014:06a7 | awk '{print $1}' | paste -sd" " -)"
export HOST_MODELS_DIR=/var/lib/ai-services/models
export VLLM_MODEL_PATH=/models/ibm-granite/granite-3.3-8b-instruct
export AIU_WORLD_SIZE=4
export MAX_MODEL_LEN=3072
export MAX_BATCH_SIZE=16
podman run \
--device=/dev/vfio \
-v "${HOST_MODELS_DIR}:/models"Z \
-e AIU_PCIE_IDS="${AIU_IDS}" \
-e VLLM_SPYRE_USE_CB=1 \
--pids-limit=0 \
--userns=keep-id \
--group-add=keep-groups \
--security-opt label=disable \
--memory=100G \
-p 8000:8000 \
registry.redhat.io/rhaiis/vllm-spyre-rhel9:3.3.0-1771459423 \
--model "${VLLM_MODEL_PATH}" \
-tp "${AIU_WORLD_SIZE}" \
--max-model-len "${MAX_MODEL_LEN}" \
--max-num-seqs "${MAX_BATCH_SIZE}" \
--enable-prefix-caching
主なオプションの説明:
| オプション | 内容 |
|---|---|
--device=/dev/vfio |
Spyre デバイスをコンテナに渡す |
-v "${HOST_MODELS_DIR}:/models" |
ホスト上のモデルディレクトリをマウント |
AIU_PCIE_IDS |
使用する Spyre カードの PCIe ID |
VLLM_SPYRE_USE_CB |
Continuous Batching を有効化(1 で ON) |
--memory=100G |
コンテナのメモリー上限 |
-p 8000:8000 |
API サーバーをホスト側にポートフォワード |
-tp |
Tensor Parallel サイズ ※利用するSpyreカードの枚数を指定 |
--enable-prefix-caching |
プレフィックスキャッシュを有効化 |
起動ログを確認する
起動後はウォームアップ処理が走ります。初回起動時はモデルのコンパイルを行うため、完了まで数分かかります。
---- IBM AIU Device Discovery...
---- --> Detecting PCIe devices...
---- --> Detected: 5 AIU PFs, 0 AIU VFs, 0 NICs, 1 NVMEs
---- --> Writing final topology file: /tmp/etc/ibm/spyre/topo.json
---- IBM AIU Environment Setup... (Generate environment from existing config)
---- IBM AIU Devices Found: 5
...
(EngineCore_DP0 pid=94) INFO 05-12 02:25:21 [spyre_worker.py:415] load model...
(EngineCore_DP0 pid=94) INFO 05-12 02:25:25 [spyre_worker.py:443] load model took 4.755s
(EngineCore_DP0 pid=94) INFO 05-12 02:25:26 [spyre_worker.py:704] [WARMUP] Prefill [1/1]...
(EngineCore_DP0 pid=94) INFO 05-12 02:26:45 [spyre_worker.py:526] [WARMUP] Deploying to device...
(EngineCore_DP0 pid=94) INFO 05-12 02:28:11 [spyre_worker.py:536] [WARMUP] Finished in 165.372s (compilation cache enabled)
(EngineCore_DP0 pid=94) INFO 05-12 02:28:11 [core.py:210] init engine (profile, create kv cache, warmup model) took 165.37 seconds
...
(APIServer pid=1) INFO 05-12 02:28:12 [api_server.py:1912] Starting vLLM API server 0 on http://0.0.0.0:8000
(APIServer pid=1) INFO: Application startup complete.
Application startup complete. が表示されれば API サーバーが起動完了です。
ウォームアップには今回の環境で約 2 分 45 秒かかりました(コンパイルキャッシュが有効な場合)。
補足: ログに
[PRECOMPILED_WARN]が出る場合があります。コンパイル済みキャッシュのバージョンやモデルパスが異なる場合の警告であり、動作には影響しません。
curl で動作確認
API サーバーが起動したら、curl でリクエストを送って確認してみます。
curl -X POST -H "Content-Type: application/json" -d '{
"model": "/models/granite-3.3-8b-instruct",
"prompt": "日本の首都はどこですか?端的に教えてください。",
"max_tokens": 50
}' http://127.0.0.1:8000/v1/completions | jq
レスポンス例:
{
"id": "cmpl-9fc82009a691cbb9",
"object": "text_completion",
"created": 1781226728,
"model": "/models/ibm-granite/granite-3.3-8b-instruct",
"choices": [
{
"index": 0,
"text": "\n東京\n\n日本の首都は東京です。",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"token_ids": null,
"prompt_logprobs": null,
"prompt_token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 17,
"total_tokens": 34,
"completion_tokens": 17,
"prompt_tokens_details": null
},
"kv_transfer_params": null
}
無事に回答が返ってきました。
OpenWebUI と連携してみる
せっかくなので、ブラウザから使えるチャットUIも試してみます。
Mac 上で OpenWebUI を Podman で起動し、先ほど起動した vLLM API に接続します。
podman run -d \
-p 7860:8080 \
-v open-webui:/app/backend/data \
--name open-webui \
ghcr.io/open-webui/open-webui:main
http://localhost:7860/ にアクセスすると OpenWebUI の画面が表示されます。
OpenAI APIの接続管理に起動したサーバーの接続情報を入れていきます。
API キーは設定していないため、任意の値(例: vllm)を入力します。
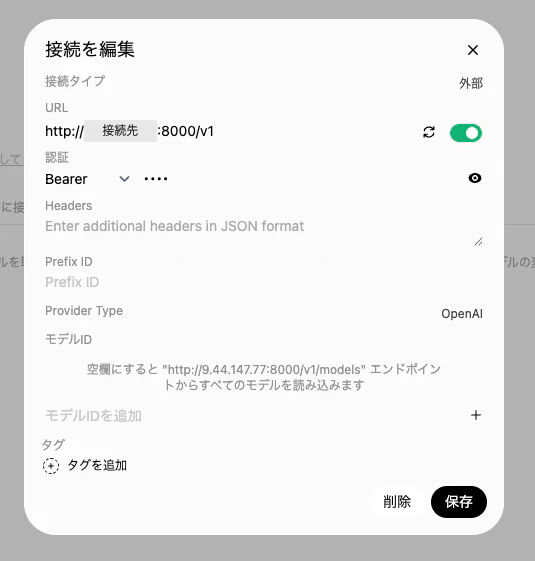
接続先として vLLM の API エンドポイントを指定することで、Granite モデルとブラウザからチャットできるようになります。

まとめ
RHAIIコンテナを使うことで、IBM Spyre アクセラレーター上での LLM 推論をシンプルな podman run コマンドだけで試せることが確認できました。
- Spyre カードの PCIe ID を環境変数にセットして渡すだけでデバイスが認識される
- ウォームアップ込みで数分以内に OpenAI 互換の API サーバーが起動する
- OpenWebUI など既存の UI ツールとそのまま連携できる
手軽に試せる構成なので、まずは動作確認やベンチマークの出発点としておすすめです。