・完成画面キャプチャ
・ファイル読み込み前
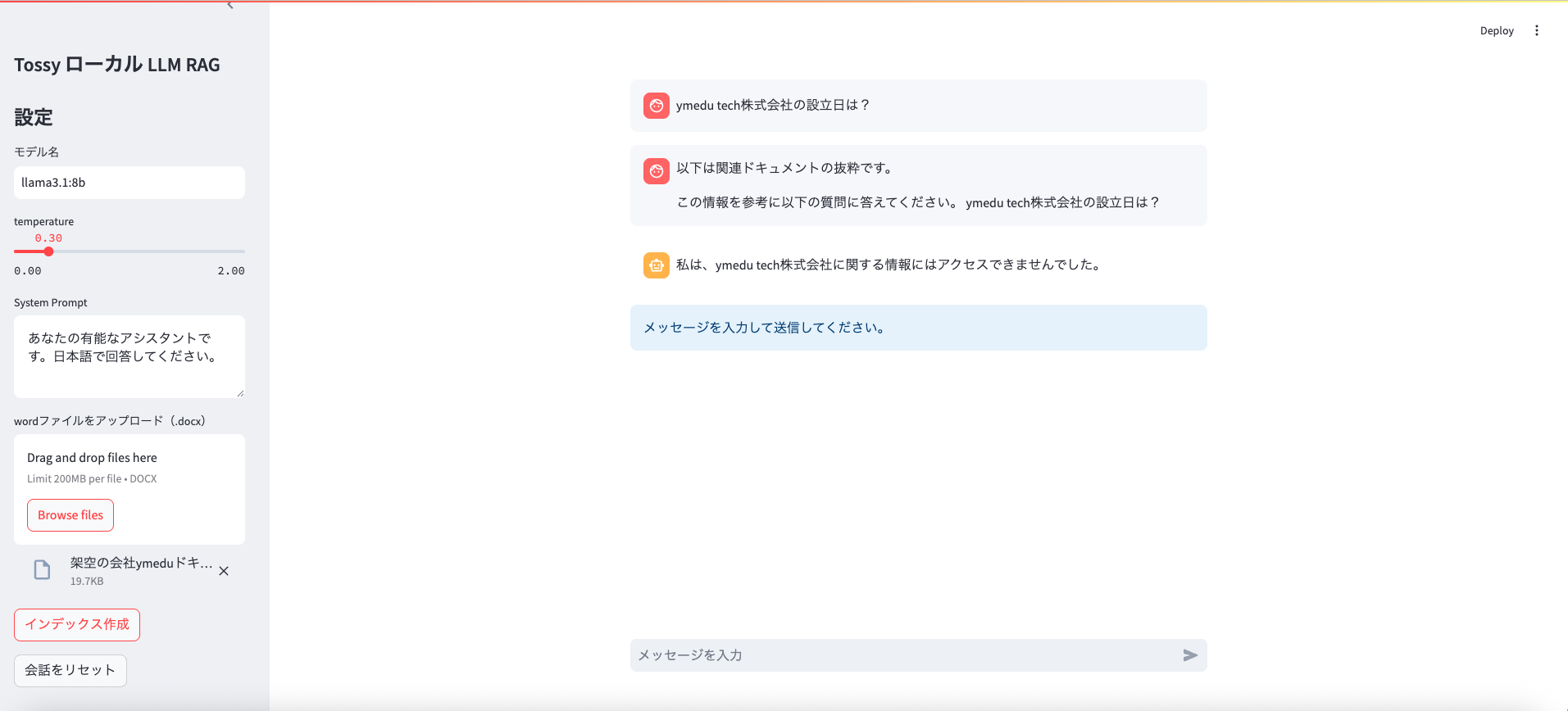
・ファイル読み込み後

概要
OllamaでローカルLLM(例:llama3.1:8b)を動かし、StreamlitでチャットUIを作る手順をまとめます。モデルの導入・一覧・削除・実行などの基本コマンドと、OLLAMA_HOST によるポート指定付きサーバ起動(Mac/Windows)を整理。さらにOpenAI互換APIとして base_url を指定し、会話履歴保持・リセット・System Prompt・temperature調整・ストリーミング表示に対応した最小構成のサンプルコードを掲載します。
その他
・pipコマンド
$pip install chromadb==1.0.16 python-docx==1.2.0 requests==2.32.3
・ollama モデル
ollama pull nomic-embed-text
ソース
import streamlit as st
from openai import OpenAI
import chromadb
from docx import Document
import requests
### chromadb 設定
DB_DIR = "./chroma_db"
chroma_client = chromadb.PersistentClient(path=DB_DIR)
# テーブル作成
if "collection" not in st.session_state:
st.session_state.collection = chroma_client.get_or_create_collection(
name="local_docs"
)
### Ollama モデルを使ったベクトル化
def ollama_embed(text):
r = requests.post(
"http://localhost:12000/api/embeddings",
json={"model": "nomic-embed-text", "prompt": text}
)
data = r.json()
return data["embedding"] # ベクトル化して返す
### Wordファイルを読み込む
def load_word_document(file):
return "¥n" . join(para.text for para in Document(file).paragraphs) # 行ごとの、データを改行で結合
### テキスト分割
def split_text(text):
chunk_size = 200
overlap = 50
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunks.append(text[start:end])
start += chunk_size - overlap
return chunks
# ページタイトル
st.set_page_config(page_title="ローカル LLM Chat")
# サイドバー
st.sidebar.title("Tossy ローカル LLM RAG")
st.sidebar.title("設定")
model = st.sidebar.text_input("モデル名", value="llama3.1:8b")
temperature = st.sidebar.slider("temperature", 0.0, 2.0, 0.3, 0.1)
system_prompt = st.sidebar.text_area(
"System Prompt",
"あなたの有能なアシスタントです。日本語で回答してください。"
)
# ファイルのアップロード
uploaded_files = st.sidebar.file_uploader(
"wordファイルをアップロード(.docx)",
type=["docx"],
accept_multiple_files=True # 複数ファイルアップロード OK
)
### アップロードされたファイルを、テキスト分割して、ベクトル化して、chroma_db へ保存
if st.sidebar.button("インデックス作成"): # ボタンを押した時のイベント
for file in uploaded_files:
text = load_word_document(file) # テキスト化
chunks = split_text(text) # テキスト分割
for i, chunk in enumerate(chunks):
embed = ollama_embed(chunk) # ベクトル化
st.session_state.collection.add(
documents=[chunk],
embeddings=[embed],
ids=[f"{file.name}_{i}"]
)
st.sidebar.success("インデックス作成処理 正常終了")
# 会話の履歴を保管
if "messages" not in st.session_state:
st.session_state.messages = []
# 会話の履歴を削除(リセット)ボタン
if st.sidebar.button("会話をリセット"):
st.session_state.messages = []
# 会話の履歴を表示
for m in st.session_state.messages:
with st.chat_message(m["role"]):
st.write(m["content"])
prompt = st.chat_input("メッセージを入力")
client = OpenAI(
api_key="ollama",
base_url="http://localhost:12000/v1"
)
### 結果出力 ###
# print("response全体:", response)
# print("テキスト抽出:", response.choices[0].message.content)
# プロンプトが空じゃない場合
if prompt:
# 履歴格納
st.session_state.messages.append({"role": "user", "content": prompt})
# ユーザ側のメッセージ表示
with st.chat_message("user"):
st.write(prompt)
### RAG検索 ###
# ベクトル化
query_embed = ollama_embed(prompt)
# 似ているベクトルを引っ張ってくる, chroma_db
results = st.session_state.collection.query(
query_embeddings=[query_embed],
n_results=2 # 取得情報
)
### 返ってくるデータ構造
#{
# "ids":
# "documents": [["doc1", "doc2"]],
# "distances": [[ ***, ****]] # 距離が返ってくる
#}
if results["documents"]:
context_text = "\n".join(results["documents"][0])
rag_prompt = f"""
以下は関連ドキュメントの抜粋です。
{context_text}
この情報を参考に以下の質問に答えてください。
{prompt}
"""
final_user_prompt = rag_prompt
else:
final_user_prompt = prompt
st.session_state.messages.append({"role": "user", "content": final_user_prompt})
# システムプロンプト処理
if system_prompt.strip():
messages = [{"role": "system", "content": system_prompt}] + st.session_state.messages
else:
messages = st.session_state.messages
# エージェント側のメッセージ表示
with st.chat_message("assistant"):
# 上書き表示用
placeholder = st.empty()
# 表示用
stream_response = ""
stream = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
stream=True
)
# 格納
for chunk in stream:
stream_response += chunk.choices[0].delta.content
placeholder.write(stream_response) # 上書き表示
# st.write(stream_response)
### 履歴格納
st.session_state.messages.append({"role": "assistant", "content": stream_response})
# プロンプトが空の場合
else:
st.info("メッセージを入力して送信してください。")
起動用シェルスクリプト
#!/usr/bin/env bash
set -euo pipefail
# この .sh が置かれているディレクトリ=プロジェクト直下
SCRIPT_DIR="$(cd "$(dirname "$0")" && pwd)"
PROJECT_DIR="$SCRIPT_DIR"
VENV_DIR="$PROJECT_DIR/venv"
OLLAMA_ADDR="127.0.0.1:12000"
STREAMLIT_APP="$PROJECT_DIR/test-3.py"
echo "==> cd $PROJECT_DIR"
cd "$PROJECT_DIR"
# venv 有効化
if [[ ! -f "$VENV_DIR/bin/activate" ]]; then
echo "ERROR: venv not found: $VENV_DIR"
exit 1
fi
# venv 起動
source "$VENV_DIR/bin/activate"
# ollama サーバ立ち上げ
if ! command -v ollama >/dev/null 2>&1; then
echo "ERROR: ollama command not found."
exit 1
fi
# Ollama がすでに起動中か確認
if curl -s "http://$OLLAMA_ADDR/v1/models" >/dev/null 2>&1; then
echo "==> Ollama already running on $OLLAMA_ADDR"
OLLAMA_PID=""
else
echo "==> start Ollama server on $OLLAMA_ADDR"
export OLLAMA_HOST="$OLLAMA_ADDR"
LOGFILE="$PROJECT_DIR/ollama_serve.log"
nohup ollama serve > "$LOGFILE" 2>&1 &
OLLAMA_PID=$!
# 起動待ち(最大30秒)
for _ in {1..30}; do
curl -s "http://$OLLAMA_ADDR/v1/models" >/dev/null 2>&1 && break
sleep 1
done
if ! curl -s "http://$OLLAMA_ADDR/v1/models" >/dev/null 2>&1; then
echo "ERROR: Ollama did not start. Check log: $LOGFILE"
exit 1
fi
fi
# Ctrl+C などで終了したら、スクリプトが起動した Ollama も止める
cleanup() {
if [[-n "${OLLAMA_PID:-}"]]; then
echo ""
echo "==> stopping Ollama (PID: $OLLAMA_PID)"
kill "$OLLAMA_PID" >/dev/null 2>&1 || true
fi
}
trap cleanup EXIT INT TERM
export OLLAMA_HOST="$OLLAMA_ADDR"
# streamlit 起動
echo "==> start Streamlit: $STREAMLIT_APP"
exec streamlit run "$STREAMLIT_APP"