背景
よくこんな会話が聞こえてくる。
「お前ほんとスリザリンっぽい顔してるよなー」「あいつまじグリフィンドールっぽくない?」「ハッフルパフってなんだっけ?」
確かになんとなくわかることもある。ハリーポッターにおける寮の組み分けはそもそも精神的なところが重要なのだと作中では言ってた気がするが、精神が肉体に影響を及ぼすのだとしたら、組み分けの特徴も顔に出てくるのではないだろうか。だとしたら顔に寮ごとの特徴量があるはず!よし学習だ!といったモチベーション。
以下に、個人的な主観での組み分け予想を示す。


並びに悪意はありません。
実行環境
- Mac OS X 10.10.5 (Yosemite)
- Python 2.7.13_0
- Chainer 1.20.0.1_0
- Open CV 3.2.0_0 (+contrib+java+python27+qt4+vtk)
目的
人の顔が写った画像を入力としたとき、顔の組み分け結果がどの寮かを出力として返す組み分けニューラルネットを構築する。寮の種類はグリフィンドール・レイブンクロー・ハッフルパフ・スリザリンの4つあるため、ニューラルネットは4クラス分類器となる。以下に、構築する組み分けニューラルネット全体の概念図を示す。
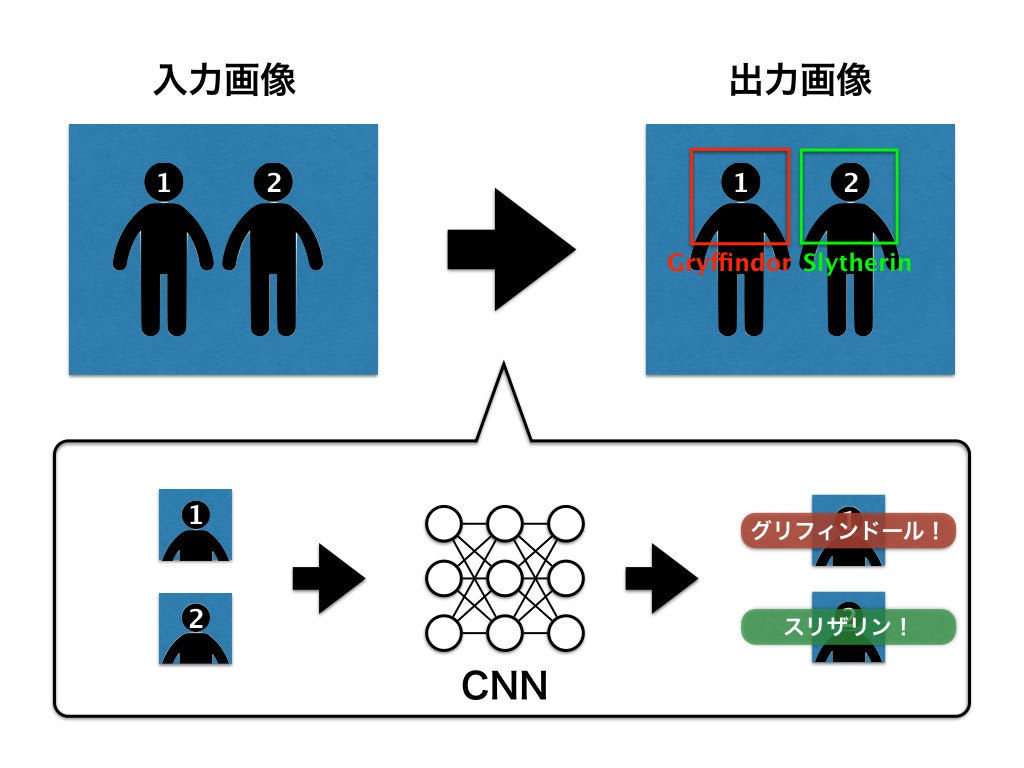
次節では、学習におけるデータセット作成やニューラルネットのモデル構成に焦点を当てて説明していく。
方法
目的で述べた通り、本節ではデータセット作成およびニューラルネットのモデル構成について述べる。
データセット作成
前回行った機械学習に用いるデータセット作成のための画像収集Pythonスクリプトを用いてデータセットを作成した。それぞれの寮に所属するキャラクター名や俳優名をクエリとして収集。最後に各寮ごとのディレクトリ下に該当するキャラの画像かどうか人手で判断して格納した。
以下に寮ごとの収集例の一部を示す。

画像サイズはすべて100 × 100 pixel で、各寮の画像は50枚ずつの計200枚となった。 当たり前だが西洋人が多いし、キャラによって偏りが非常に大きい。特にレイブンクローとハッフルパフが全然集まらなかった…少なすぎる…
この中から無作為に選んだ20枚をテストデータとして学習を行った。
モデル構成
タスクは4クラス分類なので、そこまで規模を大きくする必要はないと考えたが、一部Alexnetを参考にした。モデル構成は以下に示す。
class Model(Chain):
def __init__(self):
super(Model, self).__init__(
conv1=L.Convolution2D(3, 128, 7, stride=1),
bn2=L.BatchNormalization(128),
conv3=L.Convolution2D(128, 256, 5, stride=1),
bn4=L.BatchNormalization(256),
conv5=L.Convolution2D(256, 384, 3, stride=1),
bn6=L.BatchNormalization(384),
fc7=L.Linear(6144, 8192),
fc8=L.Linear(8192, 1024),
fc9=L.Linear(1024, 4),
)
def __call__(self, x, train=True):
h = F.max_pooling_2d(self.bn2(F.relu(self.conv1(x))), 3, stride=3)
h = F.max_pooling_2d(self.bn4(F.relu(self.conv3(h))), 3, stride=3)
h = F.max_pooling_2d(self.bn6(F.relu(self.conv5(h))), 2, stride=2)
h = F.dropout(F.relu(self.fc7(h)), train=train)
h = F.dropout(F.relu(self.fc8(h)), train=train)
y = self.fc9(h)
return y
class Classifier(Chain):
def __init__(self, predictor):
super(Classifier, self).__init__(predictor=predictor)
self.train = True
def __call__(self, x, t, train=True):
y = self.predictor(x, train)
self.loss = F.softmax_cross_entropy(y, t)
self.acc = F.accuracy(y, t)
return self.loss
以上のデータセットとモデルによる学習を行った結果を、次節にて述べる。
結果
本節では、学習器の学習推移と実装した組み分けニューラルネットの結果について述べる。
モデルの学習推移
データセットは全200枚で、その内訳は学習データは180枚、テストデータは20枚となっている。epoch数を100とした時の学習とテストのError Rate (1 - Accuracy Rate) 推移を以下に示す。
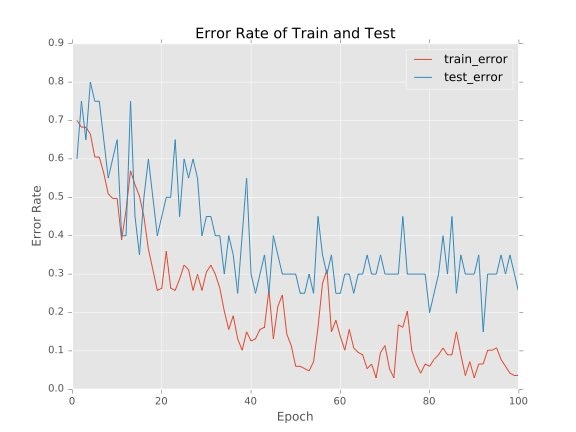
一番低いtest_errorが0.15であったことから、本モデルは4クラス分類で85%の精度を示したといえる。
組み分けニューラルネット実行結果
学習したモデルを組み込んだ組み分けニューラルネットに、実際の画像を入力したときの結果を示す。


答えはわからないが、とりあえず入力に対して目的通りの出力が確認できた!
予想してた通りに阿部寛はグリフィンドール、有吉はスリザリンに組み分けされたのに対して、ガッキーとベッキーはまったく正反対の組み分け結果が出力された。でもスリザリンなガッキーも悪くないですね。いじめられたい。
ちょっと楽しいので、次に多人数を一気に判定できる画像を探してきて入力してみた。

元国民的アイドルグループSMAP (Sports Music Assemble People) を入力してみたところ、このような結果となった。多人数でも一気にいける!しかも割と納得できる結果!笑
一通り遊んでみたが、答えがそもそもない問題なので精度とかに責任持たなくていいから楽しいです。以下に簡単な遊び方を少しだけ。
遊び方
組み分けニューラルネットのソースコード : GitHub
また、今回学習させたモデルはここにおいておきます。
簡単な使い方として、cloneしてきたディレクトリ内に落としてきた学習済みモデルを置いて、以下のコマンドを実行すると遊べたりします。また注意して欲しいのは、顔認識の部分でOpenCVのhaarcascadeを用いているので、haarcascadeディレクトリを作成してその直下に顔認識学習済みモデル (haarcascade_frontalface_default.xmlとか) を置いておく必要があります。コード内でモデルを参照しているpathを書き換えちゃってもいいですが。
$ python main.py -i ImagePath -m ./LearnedModel.model -p 1
また遊ぶときの注意点として、最初の顔認識さえ成功すれば組み分け結果が顔ごとにラベリングされる為、OpenCVの顔認識にひっかかる顔の写った画像を入力することに気をつけなくてはならない。顔認識の精度も学習済みモデルによって変わってくるので、一回失敗したからといって諦めずに色々試した方がよい。
考察
学習データ数が学習結果を大きく左右するが、今回は映画に出演している各寮ごとの俳優さんたちに偏りがありすぎたため、満足する数を集めることができなかった。それでも、正答率85%もあるということは、何かしらの寮ごとの特徴を掴めたということなのかもしれない。人のサンプル数的には同じ顔がバリデーションに入っててもおかしくないので、85%くらい当たり前やろってなりそうだが…
また、今回のモデル構成はAlexNetを参考にしたが、入力画像は100×100を想定しているので、そこまで自由度の高いモデルにする必要はないと判断したことから畳み込み層を減らした。さらにkernelが7×7や5×5の層をもう少しバラして深くしてやった方がより汎化性能が向上したかもしれない。そこまで本気でチューニングを行ったわけではないので、ランダムサーチしてやれば精度の向上はまだ期待できる。
有吉がスリザリンでなんとなく満足した。
ちなみに僕はグリフィンドールでした。やったぜ。