画像の圧縮、超解像、動画フレーム補完、予測などのタスクで用いられるのが 画質評価メトリクス です。元の画像と歪みあり画像を比較し、どれだけ元の画像に近いかを評価するものです。例えばJPEGなどの歪みあり圧縮の場合は、もとの画像と圧縮→復元をした画像をメトリクスで比較し、その値が良いほど良い圧縮とみなされます。

画質評価メトリクスの代表的なものにはMSE (最小二乗誤差)、PSNR (ピーク信号対ノイズ比), SSIM (構造的類似性), LPIPS (ニューラルネットを使った知覚損失) などがあります。ここで、問題は後ろの二つです。この二つはいくつかのパラメータを持っていて、使い方を誤ると致命的に違う値が出てきます。SSIMが実装されているsk-imageライブラリでは、こんなコメントがありました。
「多くの研究者がこの関数 (SSIM) に頼っていますが、浮動小数点数の場合は誤った結果を返します。 (...) 個人的な話ですが、博士課程の4年目でこの問題に気付きました。おそらく何百報という論文が、間違ったSSIMの値を気付かずに報告していると思います」
これはsk-image の実装が悪いというわけではなく、もっと本質的な話で、 評価メトリクスの使い方について、研究者があまり気にしていない ということに由来します。ということでこの記事では、主にSSIMとLPIPSの正しい使い方を学ぶために、そのパラメータの意味や論文での書き方について見ていきます。
SSIM
SSIMは Wang et al. (IEEE TIP 2004) で提案された画質評価指標で、画像間の類似性を輝度 (luminance)・コントラスト (contrast)・構造 (structure) の三成分に分けて計算します。
$$\text{SSIM}(x,y) = \frac{(2\mu_x\mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)}$$
- $\mu_x,, \mu_y$:局所ウィンドウ内の平均(輝度)
- $\sigma_x^2,, \sigma_y^2$:局所分散(コントラスト)
- $\sigma_{xy}$:局所共分散(構造の相関)
- $C_1 = (K_1 L)^2,\quad C_2 = (K_2 L)^2$(安定化定数、$K_1=0.01, K_2=0.03$)
- $L$:data_range — 画素値のダイナミックレンジ
SSIM の値は 1 枚の画像全体ではなく、局所ウィンドウをスライドさせながら各位置で計算し、その平均を取ります。最終的な値は 1 に近いほど元画像に近いことを意味します。
パラメータ①:data_range
安定化定数 $C_1, C_2$ は $L$(data_range)の2乗に比例します。uint8 画像なら $L=255$、float [0,1] 画像なら $L=1.0$ です。これを間違えると安定化定数の大きさが変わり、SSIM の値が変化します。
skimage の structural_similarity はデフォルトで data_range=None になっており、0.21 以前はfloat 画像に対して
data_range = im1.max() - im1.min() # 画像の実際の値域から計算
として data_range を自動推定していました。自然画像の全画素を使えば最大値・最小値が [0, 1] の端に来ることが多く、フル解像度の画像では影響が出にくいです。しかしモデルの出力やパッチ(局所領域)では [0,1] 全体を使い切るとは限らないため、max-min が 1.0 より小さくなり、SSIM 値がずれます。
skimage 0.22 以降では、float 画像に対して data_range を指定しないと
ValueError: Since image dtype is floating point, you must specify the data_range parameter.
と例外が出るように修正されました。
パラメータ②:ウィンドウの種類
Wang et al. の原著では 11×11 のガウシアンウィンドウ($\sigma=1.5$)を使います。ウィンドウ中心ほど重く計算することで、エッジ付近のアーティファクトへの過敏な反応を抑える設計です。
一方、skimage のデフォルトは 一様な 7×7 矩形ウィンドウ です。両者は異なる SSIM 値を与えるため、どちらを使ったかを明記しないと比較できません。
ベンチマーク結果
試しに、これらの設定次第でどれぐらいSSIMの値が異なるのかを確認してみます。Kodakデータセット 24枚 に、下の画像のように sigma = 3 のガウスぼかしをかけます。

これらの画像群を、間違ったSSIMと正しい SSIM でそれぞれ評価すると、次のようになります。
| # | 設定 | 平均 SSIM |
|---|---|---|
| 1 | skimage 0.26 — デフォルト設定 (data range = [0,1]) | 0.6224 |
| 2 | skimage 0.19 — デフォルト設定(data range 自動推定、 誤り) | 0.6080 |
| 3 | skimage 0.26 — 論文設定 (data_range=1.0、gaussian_weights=True、sigma=1.5) |
0.6236 |
| 4 | torchmetrics SSIM — 論文設定 data_range=1.0
|
0.6220 |
このように、古いバージョンでデフォルト設定のまま動かすと平均SSIMが大きく悪化します。また、論文の設定を用いるか、sklearn ライブラリのデフォルト設定 (ガウス重みなし、窓サイズ7) で動かすかでも値が多少変化します。
さらに同じ正しい設定でも skimage と torchmetrics でかなりの差があります。これは境界処理や積分のやり方の違いによるものです。なお、torchmetrics はデフォルト設定が論文設定と同じ (ガウス重みあり、窓サイズ11) なので、本来は3,4は同じになるはずです。ここからは、(1)どの設定を使ったか、(2)正しくレンジを設定したか、そして(3)どのライブラリを使ったか、まで揃えないと正しい比較ができないことが見て取れます。
正しい使い方
skimage で [0,255] 範囲の画像を用いる場合、正しい使い方は以下です。
from skimage.metrics import structural_similarity
import numpy as np
# float [0,1] で比較する場合:data_range を必ず明示する
ssim_val = structural_similarity(
img_orig.astype(np.float32) / 255.0,
img_comp.astype(np.float32) / 255.0,
data_range=1.0,
channel_axis=-1, # RGB (H, W, C) の場合
)
# 論文設定(Wang et al. 2004)に合わせる場合
ssim_val = structural_similarity(
img_orig.astype(np.float32) / 255.0,
img_comp.astype(np.float32) / 255.0,
data_range=1.0,
channel_axis=-1,
gaussian_weights=True,
sigma=1.5,
win_size=11,
)
# uint8 でも問題ない(dtype から data_range=255 が自動設定される)
ssim_val = structural_similarity(img_orig, img_comp, channel_axis=-1)
また、torchmetrics を用いる場合は、デフォルト設定で [0,1] 画像を入力すると論文設定で動きます。
ssim = torchmetrics.image.StructuralSimilarityIndexMeasure(data_range=1.0)
ssim_val = ssim(img_orig_tensor, img_comp_tensor) #[0,1] 画像
LPIPS
LPIPS は Zhang et al. CVPR 2018 で提案された知覚評価手法です。SSIMなどは完全にアルゴリズムベースの手法でしたが、LPIPSではニューラルネットを使います。具体的には二つの画像を、訓練済みの画像分類ネットワークに入力し、その中間層の特徴量をL2で比べます。この手法の良さは、人間の「似ている」「似ていない」という判断にかなり近い指標で判断ができるということです。
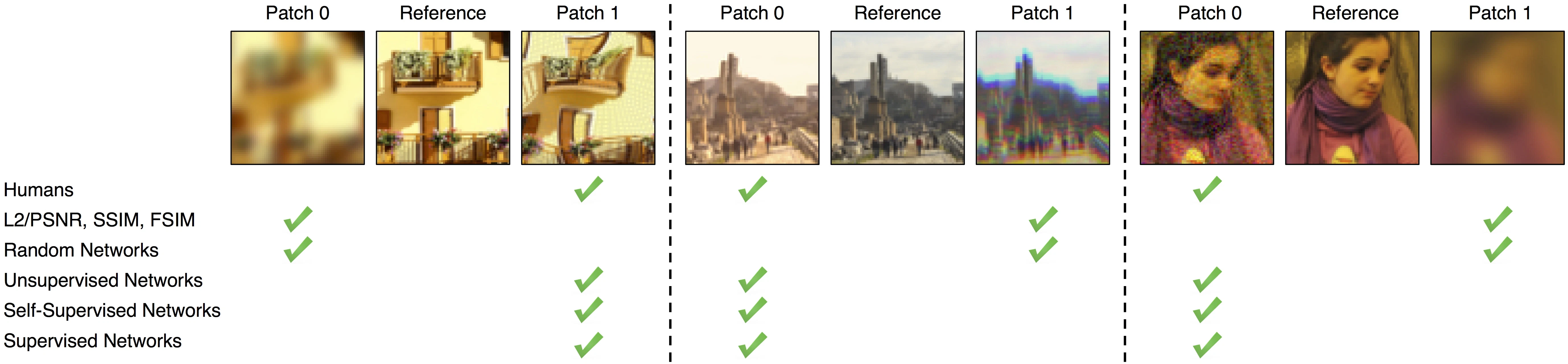
さて、標準的なLPIPSの実装は lpips パッケージにあります。このパッケージを使う際の注意点は二つあり、 (1) ネットワークとして AlexNetとVGGどちらを使うか統一しないといけないこと、そして (2) 画素値は [-1,1] の範囲でないといけない ということです。まず(1) についてですが、原論文では AlexNetとVGGの二つのネットワークで実験を行っており、実装にも二つがあります。当然ながら LPIPS-AlexとLPIPS-VGGはまったく違う指標になってしまうので、値を比べることはできません。にもかかわらず、結構な量の論文が 「LPIPSはいくつでした」とだけ報告しています。
そして (1) よりもさらに恐ろしいのは (2) で、lpips パッケージの実装は入力として [-1,1] にスケーリングされた画素値を前提しているというところです。最近のPytorchの標準的な実装では、画像を連続値で取り扱うときは [-1,1] ではなく [0,1] です。例えば画像を torchvision.transforms.ToTensor で読み込むときは [0,1] にスケーリングされます。なので、これを知らないとモデルの出力などを[-1,1]へのスケーリングなしで lpips に入力してしまい、誤った値を得てしまいます。
正しい使い方
lpips パッケージを直接使う場合(自分で [-1,1] 変換が必要):
import lpips
import torch
loss_fn = lpips.LPIPS(net='alex') # 'alex' または 'vgg'
# [0,1] の tensor を [-1,1] にスケーリングしてから渡す
img1_scaled = img1 * 2.0 - 1.0
img2_scaled = img2 * 2.0 - 1.0
score = loss_fn(img1_scaled, img2_scaled)
torchmetrics を使う場合(normalize=True で自動変換):
from torchmetrics.image import LearnedPerceptualImagePatchSimilarity
# normalize=True にすると [0,1] → [-1,1] への変換を内部で自動実行
lpips_fn = LearnedPerceptualImagePatchSimilarity(net_type='alex', normalize=True)
# img1, img2 は [0,1] の (N, C, H, W) tensor をそのまま渡せる
score = lpips_fn(img1, img2)
normalize=False(torchmetrics のデフォルト)のままだと、[0,1] の入力を [-1,1] として扱うため誤った値になります。
ベンチマーク結果
先ほどと同様に、ガウスぼかしをかけたkodak データセットで評価します。
| # | 設定 | 平均 LPIPS |
|---|---|---|
| 1 | LPIPS-VGG(normalize=True、正しい) |
0.4969 |
| 2 | LPIPS-Alex(normalize=True、正しい) |
0.5891 |
| 3 | LPIPS-Alex(normalize=False、[0,1] をそのまま渡す — バグ) |
0.5248 |
VGG, Alex は当然異なる値を出します。また、normalize を忘れるだけで Alex の値が0.065ほど悪化します。スケーリングを忘れると入力の「中心」が正しい 0([-1,1] の中心)ではなく 0.5([0,1] の中心 → [-1,1] では -0.5 相当)にずれ、ネットワークの内部正規化と噛み合わなくなるためです。
Bjontegaard-Delta Rate
この部分は画質評価メトリクスそのものの話ではないですが、関連して重要な話です。画像圧縮や動画圧縮では、画質だけではなく圧縮率 (ビットレート) も大事です。そこで、複数のビットレートでの結果から平均の圧縮率の差を見るために Bjontegaard-Delta Rate, 通称BD-Rateが出てきます。このBD-Rateも実は 測定法に依存する割に、ほとんどの論文ではそれが書かれてない という問題があります。
まず簡単にBD-Rateが何かを説明します。画像・動画圧縮では、圧縮の強さを変えることで複数の(ビットレート、画質)ペアが得られます。これを横軸をビットレート $R$、縦軸を PSNR $D$ としてプロットしたものが レート・歪み曲線 (Rate-Distortion Curve) です。例えばJPEGで圧縮品質を変えながらKodak Dataset を圧縮・評価してみると、このような曲線が得られます。
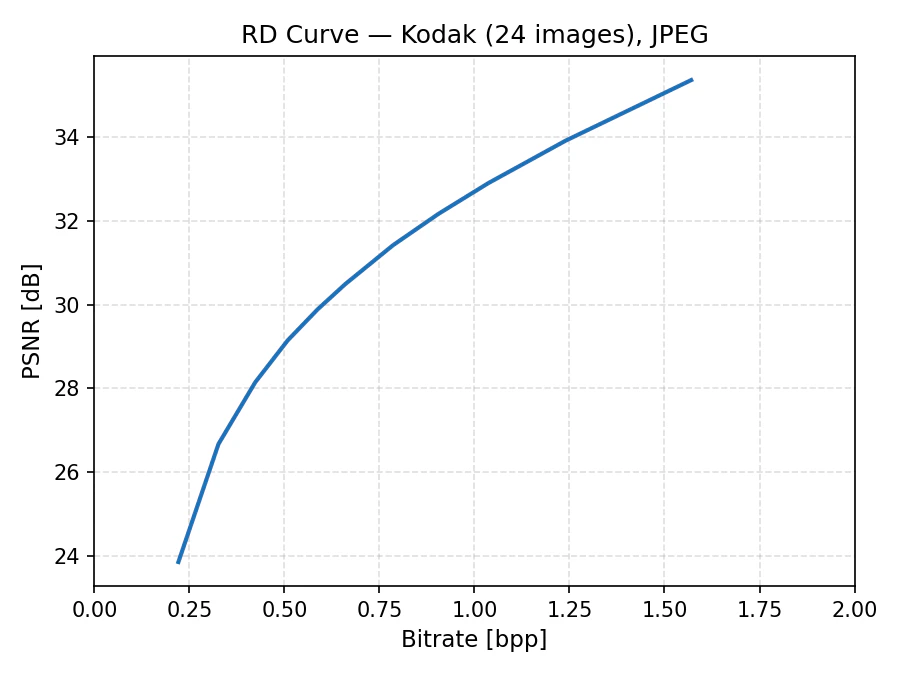
二つの手法を比較するとき、単純に「この画質でどちらのビットレートが低いか」だけを見ると、比較するPSNRの点によって結論が変わる可能性があります。BD-Rateはこれを解決するために、RD曲線全体にわたって平均的なビットレート差を一つの数値に集約します。
計算手順
各手法について、$N$ 点の(ビットレート、PSNR)ペアを用意します。
$${(R_1, D_1), (R_2, D_2),\ \ldots, (R_N, D_N)}$$
ステップ 1:対数変換
ビットレートの差を相対値(パーセント)で評価するため、横軸を対数スケールに変換します。
$$r_i = \log_{10}(R_i)$$
ステップ 2:RD曲線を多項式で近似
各手法の ${(r_i, D_i)}$ を3次多項式(キュービック)で近似します。アンカー手法(比較基準)を $f_A$、テスト手法を $f_T$ とすると:
$$D = f_A(r) = a_A r^3 + b_A r^2 + c_A r + d_A$$
$$D = f_T(r) = a_T r^3 + b_T r^2 + c_T r + d_T$$
ステップ 3:共通のPSNR範囲を決定
二つの曲線が重なるPSNR範囲を積分区間とします。
$$D_{\min} = \max\bigl(\min_i D_i^A, \min_i D_i^T\bigr), \qquad D_{\max} = \min\bigl(\max_i D_i^A, \max_i D_i^T\bigr)$$
ステップ 4:各曲線をPSNRの関数として積分
$r$ を $D$ の関数とみなした逆関数 $g_A(D),, g_T(D)$ を使い、共通PSNR範囲で平均対数ビットレート差を求めます。
$$\Delta r = \frac{1}{D_{\max} - D_{\min}} \int_{D_{\min}}^{D_{\max}} \bigl[g_T(D) - g_A(D)\bigr], \mathrm{d}D$$
この積分は多項式近似の係数から解析的に計算できます。
ステップ 5:パーセント変換
対数の差をビットレートの相対差(パーセント)に戻します。
$$\text{BD-Rate} = \bigl(10^{\Delta r} - 1\bigr) \times 100;%$$
例えば BD-Rate $= {-20}%$ は、「アンカー(例:VVC)と同じ PSNR を、提案手法は 20% 少ないビットレートで達成した」という意味です。
それでは、この操作のなかで何が差を産む原因になるのかというと、 (1) ベースラインの計測方法と (2) 3次曲線で近似する際の手法、の二つです。ベースラインには h.266/VVCなどの標準化手法が用いられることが多いですが、この性能が微妙に違うことがあります。例えば標準ソフトウェアのバージョンの差異 (VTM-10.0とVTM-20.0など) 、RGB-YUVの色空間変換のレンジ、その他のたくさんのパラメータなどです。なお、 CompressAI の compressai.bench のVTM性能測定はよく論文で使われていますが、実は色空間変換のレンジが狭く性能がやや悪いです。
この場合、元のRD-Curveの形自体が変わります。なので当然、BD-Rateの値も違うものが報告されます。圧縮系の論文では「VVC-Intraに対して20%の性能改善を達成しました」みたいにアブストに書いてありますが、わざとベースラインを弱めにして性能を高めに見せるという悪いハックもできてしまいます。
さらに、RD-Curveの形が同じでもBD-Rateの性能は変わります。それは3次近似の手法の違いです。Pythonの bjontegaard ライブラリには、Cubic Spline や Akima 近似などの近似手法が用意されています。ほとんどの場合はデフォルトの Akima 近似が用いられているかと思いますが、論文にここまで書いてあることは稀です。
余談ですが、BD-Rateの正しい使い方については最近出た The Bjontegaard Bible (Herglotz et al. IEEE TIP 2024) という論文に詳しく載っています。興味のある向きはぜひ参照してみてください。
おわりに
この記事では、 画質評価メトリクスは、雑に使うとまったく違う値が出る ということを説明してきました。画像処理の多くの論文では、「先行論文では画質はこの程度ですが、今回の研究ではこの程度まで向上しました」ということを主張します。その時に使ったメトリクスが揃っていないと、意図しない結果が出てしまいます。例えば、既存論文は正しくLPIPSを測っていたが、提案手法のLPIPSの測り方が間違っていたため良い値が出て、既存論文を超えたと報告してしまう、ということが起こり得ます。また、これらを悪用して既存論文を低く見せ、提案手法を高く見せる、ということもできます。
大事なのは、論文になるべく詳しく計測手法を書くか、再現コードを公開することです。逆に、査読者は画質評価に怪しいところが合ったら突っ込むべきです。知覚系の品質よりも誤差の出づらい、PSNRやL1などの品質をチェックする、というのも良いかもしれません。